
Compare commits
merge into: jmg:main
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/1.0b
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/MegaIng-fix-818
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/antlr
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/embedded_discard
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/end_symbol_2021
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/inline
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/master
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/priority_decay
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/tree_templates
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/v0.12.0
jmg:main
pull from: jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/embedded_discard
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/1.0b
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/MegaIng-fix-818
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/antlr
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/embedded_discard
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/end_symbol_2021
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/inline
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/master
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/priority_decay
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/tree_templates
jmg:gm/2021-09-23T00Z/github.com--lark-parser-lark/v0.12.0
jmg:main
No commits in common. 'main' and 'gm/2021-09-23T00Z/github.com--lark-parser-lark/embedded_discard' have entirely different histories.
No commits in common. 'main' and 'gm/2021-09-23T00Z/github.com--lark-parser-lark/embedded_discard' have entirely different histories.
100 changed files with 12178 additions and 74 deletions
Split View
Diff Options
-
+11 -1.gitignore
-
+3 -0.gitmodules
-
+13 -0.travis.yml
-
+19 -0LICENSE
-
+1 -0MANIFEST.in
-
+183 -23README.md
-
+227 -0docs/classes.md
-
BINdocs/comparison_memory.png
-
BINdocs/comparison_runtime.png
-
+32 -0docs/features.md
-
+172 -0docs/grammar.md
-
+63 -0docs/how_to_develop.md
-
+46 -0docs/how_to_use.md
-
+51 -0docs/index.md
-
+444 -0docs/json_tutorial.md
-
BINdocs/lark_cheatsheet.pdf
-
+49 -0docs/parsers.md
-
+63 -0docs/philosophy.md
-
+76 -0docs/recipes.md
-
+147 -0docs/tree_construction.md
-
+0 -13doupdate.sh
-
+33 -0examples/README.md
-
+0 -0examples/__init__.py
-
+75 -0examples/calc.py
-
+42 -0examples/conf_earley.py
-
+38 -0examples/conf_lalr.py
-
+56 -0examples/custom_lexer.py
-
+76 -0examples/error_reporting_lalr.py
-
BINexamples/fruitflies.png
-
+49 -0examples/fruitflies.py
-
+52 -0examples/indented_tree.py
-
+81 -0examples/json_parser.py
-
+50 -0examples/lark.lark
-
+21 -0examples/lark_grammar.py
-
+168 -0examples/python2.lark
-
+187 -0examples/python3.lark
-
+82 -0examples/python_parser.py
-
+201 -0examples/qscintilla_json.py
-
+52 -0examples/reconstruct_json.py
-
+1 -0examples/relative-imports/multiple2.lark
-
+5 -0examples/relative-imports/multiple3.lark
-
+5 -0examples/relative-imports/multiples.lark
-
+28 -0examples/relative-imports/multiples.py
-
+1 -0examples/standalone/create_standalone.sh
-
+21 -0examples/standalone/json.lark
-
+1838 -0examples/standalone/json_parser.py
-
+25 -0examples/standalone/json_parser_main.py
-
+85 -0examples/turtle_dsl.py
-
+8 -0lark/__init__.py
-
+28 -0lark/common.py
-
+98 -0lark/exceptions.py
-
+104 -0lark/grammar.py
-
+50 -0lark/grammars/common.lark
-
+61 -0lark/indenter.py
-
+308 -0lark/lark.py
-
+375 -0lark/lexer.py
-
+860 -0lark/load_grammar.py
-
+266 -0lark/parse_tree_builder.py
-
+219 -0lark/parser_frontends.py
-
+0 -0lark/parsers/__init__.py
-
+345 -0lark/parsers/cyk.py
-
+322 -0lark/parsers/earley.py
-
+75 -0lark/parsers/earley_common.py
-
+430 -0lark/parsers/earley_forest.py
-
+155 -0lark/parsers/grammar_analysis.py
-
+136 -0lark/parsers/lalr_analysis.py
-
+107 -0lark/parsers/lalr_parser.py
-
+149 -0lark/parsers/xearley.py
-
+129 -0lark/reconstruct.py
-
+0 -0lark/tools/__init__.py
-
+190 -0lark/tools/nearley.py
-
+39 -0lark/tools/serialize.py
-
+137 -0lark/tools/standalone.py
-
+183 -0lark/tree.py
-
+241 -0lark/utils.py
-
+273 -0lark/visitors.py
-
+13 -0mkdocs.yml
-
+1 -0nearley-requirements.txt
-
+10 -0readthedocs.yml
-
+0 -35reponames.py
-
+0 -2repos.txt
-
+10 -0setup.cfg
-
+62 -0setup.py
-
+0 -0tests/__init__.py
-
+36 -0tests/__main__.py
-
+10 -0tests/grammars/ab.lark
-
+6 -0tests/grammars/leading_underscore_grammar.lark
-
+3 -0tests/grammars/test.lark
-
+4 -0tests/grammars/test_relative_import_of_nested_grammar.lark
-
+4 -0tests/grammars/test_relative_import_of_nested_grammar__grammar_to_import.lark
-
+1 -0tests/grammars/test_relative_import_of_nested_grammar__nested_grammar.lark
-
+7 -0tests/grammars/three_rules_using_same_token.lark
-
+0 -0tests/test_nearley/__init__.py
-
+3 -0tests/test_nearley/grammars/include_unicode.ne
-
+1 -0tests/test_nearley/grammars/unicode.ne
-
+1 -0tests/test_nearley/nearley
-
+105 -0tests/test_nearley/test_nearley.py
-
+1618 -0tests/test_parser.py
-
+116 -0tests/test_reconstructor.py
-
+7 -0tests/test_relative_import.lark
+ 11
- 1
.gitignore
View File
| @@ -1 +1,11 @@ | |||
| __pycache__ | |||
| *.pyc | |||
| *.pyo | |||
| /.tox | |||
| /lark_parser.egg-info/** | |||
| tags | |||
| .vscode | |||
| .idea | |||
| .ropeproject | |||
| .cache | |||
| /dist | |||
| /build | |||
+ 3
- 0
.gitmodules
View File
| @@ -0,0 +1,3 @@ | |||
| [submodule "tests/test_nearley/nearley"] | |||
| path = tests/test_nearley/nearley | |||
| url = https://github.com/Hardmath123/nearley | |||
+ 13
- 0
.travis.yml
View File
| @@ -0,0 +1,13 @@ | |||
| dist: xenial | |||
| language: python | |||
| python: | |||
| - "2.7" | |||
| - "3.4" | |||
| - "3.5" | |||
| - "3.6" | |||
| - "3.7" | |||
| - "pypy2.7-6.0" | |||
| - "pypy3.5-6.0" | |||
| install: pip install tox-travis | |||
| script: | |||
| - tox | |||
+ 19
- 0
LICENSE
View File
| @@ -0,0 +1,19 @@ | |||
| Copyright © 2017 Erez Shinan | |||
| Permission is hereby granted, free of charge, to any person obtaining a copy of | |||
| this software and associated documentation files (the "Software"), to deal in | |||
| the Software without restriction, including without limitation the rights to | |||
| use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of | |||
| the Software, and to permit persons to whom the Software is furnished to do so, | |||
| subject to the following conditions: | |||
| The above copyright notice and this permission notice shall be included in all | |||
| copies or substantial portions of the Software. | |||
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | |||
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS | |||
| FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR | |||
| COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER | |||
| IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN | |||
| CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | |||
+ 1
- 0
MANIFEST.in
View File
| @@ -0,0 +1 @@ | |||
| include README.md LICENSE docs/* examples/*.py examples/*.png examples/*.lark tests/*.py tests/*.lark tests/grammars/* tests/test_nearley/*.py tests/test_nearley/grammars/* | |||
+ 183
- 23
README.md
View File
| @@ -1,31 +1,191 @@ | |||
| GITMIRROR | |||
| ========= | |||
| # Lark - a modern parsing library for Python | |||
| This repo is a mirror of various repositories that I want to keep track of. | |||
| I realized that git, w/ it's inherently dedupability, and the ability to | |||
| store many trees in a single repo, that it'd be easy to create a repo that | |||
| regularly clones/mirrors other source repos. Not only this, but the | |||
| state of the tags and branches can be archived on a daily basis, | |||
| consuming very little space. | |||
| Parse any context-free grammar, FAST and EASY! | |||
| The main reason that I want this is from a supply chain availability | |||
| perspective. As a consumer of source, it isn't always guaranteed that | |||
| the project you depend upon will continue to exist in the future. It | |||
| could also be that older version are removed, etc. | |||
| **Beginners**: Lark is not just another parser. It can parse any grammar you throw at it, no matter how complicated or ambiguous, and do so efficiently. It also constructs a parse-tree for you, without additional code on your part. | |||
| **Experts**: Lark implements both Earley(SPPF) and LALR(1), and several different lexers, so you can trade-off power and speed, according to your requirements. It also provides a variety of sophisticated features and utilities. | |||
| Quick start | |||
| ----------- | |||
| Lark can: | |||
| 1. Update the file `repos.txt` with a list of urls that you want to mirror. | |||
| 2. Run the script `doupdate.sh` to mirror all the repos. | |||
| 3. Optionally run `git push --mirror origin` to store the data on the server. | |||
| - Parse all context-free grammars, and handle any ambiguity | |||
| - Build a parse-tree automagically, no construction code required | |||
| - Outperform all other Python libraries when using LALR(1) (Yes, including PLY) | |||
| - Run on every Python interpreter (it's pure-python) | |||
| - Generate a stand-alone parser (for LALR(1) grammars) | |||
| And many more features. Read ahead and find out. | |||
| Process | |||
| ------- | |||
| Most importantly, Lark will save you time and prevent you from getting parsing headaches. | |||
| 1. Repo will self update main to get latest repos/code to mirror. | |||
| 2. Fetch the repos to mirror into their respective date tagged tags/branches. | |||
| 3. Push the tags/branches to the parent. | |||
| 4. Repeat | |||
| ### Quick links | |||
| - [Documentation @readthedocs](https://lark-parser.readthedocs.io/) | |||
| - [Cheatsheet (PDF)](/docs/lark_cheatsheet.pdf) | |||
| - [Tutorial](/docs/json_tutorial.md) for writing a JSON parser. | |||
| - Blog post: [How to write a DSL with Lark](http://blog.erezsh.com/how-to-write-a-dsl-in-python-with-lark/) | |||
| - [Gitter chat](https://gitter.im/lark-parser/Lobby) | |||
| ### Install Lark | |||
| $ pip install lark-parser | |||
| Lark has no dependencies. | |||
| [](https://travis-ci.org/lark-parser/lark) | |||
| ### Syntax Highlighting (new) | |||
| Lark now provides syntax highlighting for its grammar files (\*.lark): | |||
| - [Sublime Text & TextMate](https://github.com/lark-parser/lark_syntax) | |||
| - [vscode](https://github.com/lark-parser/vscode-lark) | |||
| ### Hello World | |||
| Here is a little program to parse "Hello, World!" (Or any other similar phrase): | |||
| ```python | |||
| from lark import Lark | |||
| l = Lark('''start: WORD "," WORD "!" | |||
| %import common.WORD // imports from terminal library | |||
| %ignore " " // Disregard spaces in text | |||
| ''') | |||
| print( l.parse("Hello, World!") ) | |||
| ``` | |||
| And the output is: | |||
| ```python | |||
| Tree(start, [Token(WORD, 'Hello'), Token(WORD, 'World')]) | |||
| ``` | |||
| Notice punctuation doesn't appear in the resulting tree. It's automatically filtered away by Lark. | |||
| ### Fruit flies like bananas | |||
| Lark is great at handling ambiguity. Let's parse the phrase "fruit flies like bananas": | |||
|  | |||
| See more [examples here](https://github.com/lark-parser/lark/tree/master/examples) | |||
| ## List of main features | |||
| - Builds a parse-tree (AST) automagically, based on the structure of the grammar | |||
| - **Earley** parser | |||
| - Can parse all context-free grammars | |||
| - Full support for ambiguous grammars | |||
| - **LALR(1)** parser | |||
| - Fast and light, competitive with PLY | |||
| - Can generate a stand-alone parser | |||
| - **CYK** parser, for highly ambiguous grammars (NEW! Courtesy of [ehudt](https://github.com/ehudt)) | |||
| - **EBNF** grammar | |||
| - **Unicode** fully supported | |||
| - **Python 2 & 3** compatible | |||
| - Automatic line & column tracking | |||
| - Standard library of terminals (strings, numbers, names, etc.) | |||
| - Import grammars from Nearley.js | |||
| - Extensive test suite [](https://codecov.io/gh/erezsh/lark) | |||
| - And much more! | |||
| See the full list of [features here](https://lark-parser.readthedocs.io/en/latest/features/) | |||
| ### Comparison to other libraries | |||
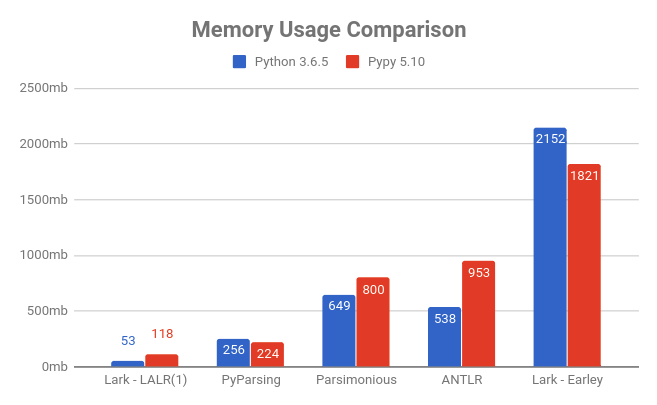
| #### Performance comparison | |||
| Lark is the fastest and lightest (lower is better) | |||
|  | |||
|  | |||
| Check out the [JSON tutorial](/docs/json_tutorial.md#conclusion) for more details on how the comparison was made. | |||
| *Note: I really wanted to add PLY to the benchmark, but I couldn't find a working JSON parser anywhere written in PLY. If anyone can point me to one that actually works, I would be happy to add it!* | |||
| *Note 2: The parsimonious code has been optimized for this specific test, unlike the other benchmarks (Lark included). Its "real-world" performance may not be as good.* | |||
| #### Feature comparison | |||
| | Library | Algorithm | Grammar | Builds tree? | Supports ambiguity? | Can handle every CFG? | Line/Column tracking | Generates Stand-alone | |||
| |:--------|:----------|:----|:--------|:------------|:------------|:----------|:---------- | |||
| | **Lark** | Earley/LALR(1) | EBNF | Yes! | Yes! | Yes! | Yes! | Yes! (LALR only) | | |||
| | [PLY](http://www.dabeaz.com/ply/) | LALR(1) | BNF | No | No | No | No | No | | |||
| | [PyParsing](http://pyparsing.wikispaces.com/) | PEG | Combinators | No | No | No\* | No | No | | |||
| | [Parsley](https://pypi.python.org/pypi/Parsley) | PEG | EBNF | No | No | No\* | No | No | | |||
| | [Parsimonious](https://github.com/erikrose/parsimonious) | PEG | EBNF | Yes | No | No\* | No | No | | |||
| | [ANTLR](https://github.com/antlr/antlr4) | LL(*) | EBNF | Yes | No | Yes? | Yes | No | | |||
| (\* *PEGs cannot handle non-deterministic grammars. Also, according to Wikipedia, it remains unanswered whether PEGs can really parse all deterministic CFGs*) | |||
| ### Projects using Lark | |||
| - [storyscript](https://github.com/storyscript/storyscript) - The programming language for Application Storytelling | |||
| - [tartiflette](https://github.com/dailymotion/tartiflette) - a GraphQL engine by Dailymotion. Lark is used to parse the GraphQL schemas definitions. | |||
| - [Hypothesis](https://github.com/HypothesisWorks/hypothesis) - Library for property-based testing | |||
| - [mappyfile](https://github.com/geographika/mappyfile) - a MapFile parser for working with MapServer configuration | |||
| - [synapse](https://github.com/vertexproject/synapse) - an intelligence analysis platform | |||
| - [Command-Block-Assembly](https://github.com/simon816/Command-Block-Assembly) - An assembly language, and C compiler, for Minecraft commands | |||
| - [SPFlow](https://github.com/SPFlow/SPFlow) - Library for Sum-Product Networks | |||
| - [Torchani](https://github.com/aiqm/torchani) - Accurate Neural Network Potential on PyTorch | |||
| - [required](https://github.com/shezadkhan137/required) - multi-field validation using docstrings | |||
| - [miniwdl](https://github.com/chanzuckerberg/miniwdl) - A static analysis toolkit for the Workflow Description Language | |||
| - [pytreeview](https://gitlab.com/parmenti/pytreeview) - a lightweight tree-based grammar explorer | |||
| Using Lark? Send me a message and I'll add your project! | |||
| ### How to use Nearley grammars in Lark | |||
| Lark comes with a tool to convert grammars from [Nearley](https://github.com/Hardmath123/nearley), a popular Earley library for Javascript. It uses [Js2Py](https://github.com/PiotrDabkowski/Js2Py) to convert and run the Javascript postprocessing code segments. | |||
| Here's an example: | |||
| ```bash | |||
| git clone https://github.com/Hardmath123/nearley | |||
| python -m lark.tools.nearley nearley/examples/calculator/arithmetic.ne main nearley > ncalc.py | |||
| ``` | |||
| You can use the output as a regular python module: | |||
| ```python | |||
| >>> import ncalc | |||
| >>> ncalc.parse('sin(pi/4) ^ e') | |||
| 0.38981434460254655 | |||
| ``` | |||
| ## License | |||
| Lark uses the [MIT license](LICENSE). | |||
| (The standalone tool is under GPL2) | |||
| ## Contribute | |||
| Lark is currently accepting pull-requests. See [How to develop Lark](/docs/how_to_develop.md) | |||
| ## Donate | |||
| If you like Lark and feel like donating, you can do so at my [patreon page](https://www.patreon.com/erezsh). | |||
| If you wish for a specific feature to get a higher priority, you can request it in a follow-up email, and I'll consider it favorably. | |||
| ## Contact | |||
| If you have any questions or want my assistance, you can email me at erezshin at gmail com. | |||
| I'm also available for contract work. | |||
| -- [Erez](https://github.com/erezsh) | |||
+ 227
- 0
docs/classes.md
View File
| @@ -0,0 +1,227 @@ | |||
| # Classes - Reference | |||
| This page details the important classes in Lark. | |||
| ---- | |||
| ## Lark | |||
| The Lark class is the main interface for the library. It's mostly a thin wrapper for the many different parsers, and for the tree constructor. | |||
| ### Methods | |||
| #### \_\_init\_\_(self, grammar, **options) | |||
| The Lark class accepts a grammar string or file object, and keyword options: | |||
| * start - The symbol in the grammar that begins the parse (Default: `"start"`) | |||
| * parser - Decides which parser engine to use, "earley", "lalr" or "cyk". (Default: `"earley"`) | |||
| * lexer - Overrides default lexer. | |||
| * transformer - Applies the transformer instead of building a parse tree (only allowed with parser="lalr") | |||
| * postlex - Lexer post-processing (Default: None. only works when lexer is "standard" or "contextual") | |||
| * ambiguity (only relevant for earley and cyk) | |||
| * "explicit" - Return all derivations inside an "_ambig" data node. | |||
| * "resolve" - Let the parser choose the best derivation (greedy for tokens, non-greedy for rules. Default) | |||
| * debug - Display warnings (such as Shift-Reduce warnings for LALR) | |||
| * keep_all_tokens - Don't throw away any terminals from the tree (Default=False) | |||
| * propagate_positions - Propagate line/column count to tree nodes (default=False) | |||
| * lexer_callbacks - A dictionary of callbacks of type f(Token) -> Token, used to interface with the lexer Token generation. Only works with the standard and contextual lexers. See [Recipes](recipes.md) for more information. | |||
| #### parse(self, text) | |||
| Return a complete parse tree for the text (of type Tree) | |||
| If a transformer is supplied to `__init__`, returns whatever is the result of the transformation. | |||
| ---- | |||
| ## Tree | |||
| The main tree class | |||
| ### Properties | |||
| * `data` - The name of the rule or alias | |||
| * `children` - List of matched sub-rules and terminals | |||
| * `meta` - Line & Column numbers, if using `propagate_positions` | |||
| ### Methods | |||
| #### \_\_init\_\_(self, data, children) | |||
| Creates a new tree, and stores "data" and "children" in attributes of the same name. | |||
| #### pretty(self, indent_str=' ') | |||
| Returns an indented string representation of the tree. Great for debugging. | |||
| #### find_pred(self, pred) | |||
| Returns all nodes of the tree that evaluate pred(node) as true. | |||
| #### find_data(self, data) | |||
| Returns all nodes of the tree whose data equals the given data. | |||
| #### iter_subtrees(self) | |||
| Depth-first iteration. | |||
| Iterates over all the subtrees, never returning to the same node twice (Lark's parse-tree is actually a DAG). | |||
| #### iter_subtrees_topdown(self) | |||
| Breadth-first iteration. | |||
| Iterates over all the subtrees, return nodes in order like pretty() does. | |||
| #### \_\_eq\_\_, \_\_hash\_\_ | |||
| Trees can be hashed and compared. | |||
| ---- | |||
| ## Transformers & Visitors | |||
| Transformers & Visitors provide a convenient interface to process the parse-trees that Lark returns. | |||
| They are used by inheriting from the correct class (visitor or transformer), and implementing methods corresponding to the rule you wish to process. Each methods accepts the children as an argument. That can be modified using the `v-args` decorator, which allows to inline the arguments (akin to `*args`), or add the tree `meta` property as an argument. | |||
| See: https://github.com/lark-parser/lark/blob/master/lark/visitors.py | |||
| ### Visitors | |||
| Visitors visit each node of the tree, and run the appropriate method on it according to the node's data. | |||
| They work bottom-up, starting with the leaves and ending at the root of the tree. | |||
| **Example** | |||
| ```python | |||
| class IncreaseAllNumbers(Visitor): | |||
| def number(self, tree): | |||
| assert tree.data == "number" | |||
| tree.children[0] += 1 | |||
| IncreaseAllNumbers().visit(parse_tree) | |||
| ``` | |||
| There are two classes that implement the visitor interface: | |||
| * Visitor - Visit every node (without recursion) | |||
| * Visitor_Recursive - Visit every node using recursion. Slightly faster. | |||
| ### Transformers | |||
| Transformers visit each node of the tree, and run the appropriate method on it according to the node's data. | |||
| They work bottom-up (or: depth-first), starting with the leaves and ending at the root of the tree. | |||
| Transformers can be used to implement map & reduce patterns. | |||
| Because nodes are reduced from leaf to root, at any point the callbacks may assume the children have already been transformed (if applicable). | |||
| Transformers can be chained into a new transformer by using multiplication. | |||
| **Example:** | |||
| ```python | |||
| from lark import Tree, Transformer | |||
| class EvalExpressions(Transformer): | |||
| def expr(self, args): | |||
| return eval(args[0]) | |||
| t = Tree('a', [Tree('expr', ['1+2'])]) | |||
| print(EvalExpressions().transform( t )) | |||
| # Prints: Tree(a, [3]) | |||
| ``` | |||
| Here are the classes that implement the transformer interface: | |||
| - Transformer - Recursively transforms the tree. This is the one you probably want. | |||
| - Transformer_InPlace - Non-recursive. Changes the tree in-place instead of returning new instances | |||
| - Transformer_InPlaceRecursive - Recursive. Changes the tree in-place instead of returning new instances | |||
| ### v_args | |||
| `v_args` is a decorator. | |||
| By default, callback methods of transformers/visitors accept one argument: a list of the node's children. `v_args` can modify this behavior. | |||
| When used on a transformer/visitor class definition, it applies to all the callback methods inside it. | |||
| `v_args` accepts one of three flags: | |||
| - `inline` - Children are provided as `*args` instead of a list argument (not recommended for very long lists). | |||
| - `meta` - Provides two arguments: `children` and `meta` (instead of just the first) | |||
| - `tree` - Provides the entire tree as the argument, instead of the children. | |||
| Examples: | |||
| ```python | |||
| @v_args(inline=True) | |||
| class SolveArith(Transformer): | |||
| def add(self, left, right): | |||
| return left + right | |||
| class ReverseNotation(Transformer_InPlace): | |||
| @v_args(tree=True): | |||
| def tree_node(self, tree): | |||
| tree.children = tree.children[::-1] | |||
| ``` | |||
| ### Discard | |||
| When raising the `Discard` exception in a transformer callback, that node is discarded and won't appear in the parent. | |||
| ## Token | |||
| When using a lexer, the resulting tokens in the trees will be of the Token class, which inherits from Python's string. So, normal string comparisons and operations will work as expected. Tokens also have other useful attributes: | |||
| * `type` - Name of the token (as specified in grammar). | |||
| * `pos_in_stream` - the index of the token in the text | |||
| * `line` - The line of the token in the text (starting with 1) | |||
| * `column` - The column of the token in the text (starting with 1) | |||
| * `end_line` - The line where the token ends | |||
| * `end_column` - The next column after the end of the token. For example, if the token is a single character with a `column` value of 4, `end_column` will be 5. | |||
| ## UnexpectedInput | |||
| - `UnexpectedInput` | |||
| - `UnexpectedToken` - The parser recieved an unexpected token | |||
| - `UnexpectedCharacters` - The lexer encountered an unexpected string | |||
| After catching one of these exceptions, you may call the following helper methods to create a nicer error message: | |||
| ### Methods | |||
| #### get_context(text, span) | |||
| Returns a pretty string pinpointing the error in the text, with `span` amount of context characters around it. | |||
| (The parser doesn't hold a copy of the text it has to parse, so you have to provide it again) | |||
| #### match_examples(parse_fn, examples) | |||
| Allows you to detect what's wrong in the input text by matching against example errors. | |||
| Accepts the parse function (usually `lark_instance.parse`) and a dictionary of `{'example_string': value}`. | |||
| The function will iterate the dictionary until it finds a matching error, and return the corresponding value. | |||
| For an example usage, see: [examples/error_reporting_lalr.py](https://github.com/lark-parser/lark/blob/master/examples/error_reporting_lalr.py) | |||
BIN
docs/comparison_memory.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 657 | Height: 405 | Size: 26 KiB |
BIN
docs/comparison_runtime.png
View File
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 656 | Height: 406 | Size: 24 KiB |
+ 32
- 0
docs/features.md
View File
| @@ -0,0 +1,32 @@ | |||
| # Main Features | |||
| - Earley parser, capable of parsing any context-free grammar | |||
| - Implements SPPF, for efficient parsing and storing of ambiguous grammars. | |||
| - LALR(1) parser, limited in power of expression, but very efficient in space and performance (O(n)). | |||
| - Implements a parse-aware lexer that provides a better power of expression than traditional LALR implementations (such as ply). | |||
| - EBNF-inspired grammar, with extra features (See: [Grammar Reference](grammar.md)) | |||
| - Builds a parse-tree (AST) automagically based on the grammar | |||
| - Stand-alone parser generator - create a small independent parser to embed in your project. | |||
| - Automatic line & column tracking | |||
| - Automatic terminal collision resolution | |||
| - Standard library of terminals (strings, numbers, names, etc.) | |||
| - Unicode fully supported | |||
| - Extensive test suite | |||
| - Python 2 & Python 3 compatible | |||
| - Pure-Python implementation | |||
| [Read more about the parsers](parsers.md) | |||
| # Extra features | |||
| - Import rules and tokens from other Lark grammars, for code reuse and modularity. | |||
| - Import grammars from Nearley.js | |||
| - CYK parser | |||
| ### Experimental features | |||
| - Automatic reconstruction of input from parse-tree (see examples) | |||
| ### Planned features (not implemented yet) | |||
| - Generate code in other languages than Python | |||
| - Grammar composition | |||
| - LALR(k) parser | |||
| - Full regexp-collision support using NFAs | |||
+ 172
- 0
docs/grammar.md
View File
| @@ -0,0 +1,172 @@ | |||
| # Grammar Reference | |||
| ## Definitions | |||
| **A grammar** is a list of rules and terminals, that together define a language. | |||
| Terminals define the alphabet of the language, while rules define its structure. | |||
| In Lark, a terminal may be a string, a regular expression, or a concatenation of these and other terminals. | |||
| Each rule is a list of terminals and rules, whose location and nesting define the structure of the resulting parse-tree. | |||
| A **parsing algorithm** is an algorithm that takes a grammar definition and a sequence of symbols (members of the alphabet), and matches the entirety of the sequence by searching for a structure that is allowed by the grammar. | |||
| ## General Syntax and notes | |||
| Grammars in Lark are based on [EBNF](https://en.wikipedia.org/wiki/Extended_Backus–Naur_form) syntax, with several enhancements. | |||
| Lark grammars are composed of a list of definitions and directives, each on its own line. A definition is either a named rule, or a named terminal. | |||
| **Comments** start with `//` and last to the end of the line (C++ style) | |||
| Lark begins the parse with the rule 'start', unless specified otherwise in the options. | |||
| Names of rules are always in lowercase, while names of terminals are always in uppercase. This distinction has practical effects, for the shape of the generated parse-tree, and the automatic construction of the lexer (aka tokenizer, or scanner). | |||
| ## Terminals | |||
| Terminals are used to match text into symbols. They can be defined as a combination of literals and other terminals. | |||
| **Syntax:** | |||
| ```html | |||
| <NAME> [. <priority>] : <literals-and-or-terminals> | |||
| ``` | |||
| Terminal names must be uppercase. | |||
| Literals can be one of: | |||
| * `"string"` | |||
| * `/regular expression+/` | |||
| * `"case-insensitive string"i` | |||
| * `/re with flags/imulx` | |||
| * Literal range: `"a".."z"`, `"1".."9"`, etc. | |||
| ### Priority | |||
| Terminals can be assigned priority only when using a lexer (future versions may support Earley's dynamic lexing). | |||
| Priority can be either positive or negative. In not specified for a terminal, it's assumed to be 1 (i.e. the default). | |||
| #### Notes for when using a lexer: | |||
| When using a lexer (standard or contextual), it is the grammar-author's responsibility to make sure the literals don't collide, or that if they do, they are matched in the desired order. Literals are matched in an order according to the following criteria: | |||
| 1. Highest priority first (priority is specified as: TERM.number: ...) | |||
| 2. Length of match (for regexps, the longest theoretical match is used) | |||
| 3. Length of literal / pattern definition | |||
| 4. Name | |||
| **Examples:** | |||
| ```perl | |||
| IF: "if" | |||
| INTEGER : /[0-9]+/ | |||
| INTEGER2 : ("0".."9")+ //# Same as INTEGER | |||
| DECIMAL.2: INTEGER "." INTEGER //# Will be matched before INTEGER | |||
| WHITESPACE: (" " | /\t/ )+ | |||
| SQL_SELECT: "select"i | |||
| ``` | |||
| ## Rules | |||
| **Syntax:** | |||
| ```html | |||
| <name> : <items-to-match> [-> <alias> ] | |||
| | ... | |||
| ``` | |||
| Names of rules and aliases are always in lowercase. | |||
| Rule definitions can be extended to the next line by using the OR operator (signified by a pipe: `|` ). | |||
| An alias is a name for the specific rule alternative. It affects tree construction. | |||
| Each item is one of: | |||
| * `rule` | |||
| * `TERMINAL` | |||
| * `"string literal"` or `/regexp literal/` | |||
| * `(item item ..)` - Group items | |||
| * `[item item ..]` - Maybe. Same as `(item item ..)?` | |||
| * `item?` - Zero or one instances of item ("maybe") | |||
| * `item*` - Zero or more instances of item | |||
| * `item+` - One or more instances of item | |||
| * `item ~ n` - Exactly *n* instances of item | |||
| * `item ~ n..m` - Between *n* to *m* instances of item (not recommended for wide ranges, due to performance issues) | |||
| **Examples:** | |||
| ```perl | |||
| hello_world: "hello" "world" | |||
| mul: [mul "*"] number //# Left-recursion is allowed! | |||
| expr: expr operator expr | |||
| | value //# Multi-line, belongs to expr | |||
| four_words: word ~ 4 | |||
| ``` | |||
| ### Priority | |||
| Rules can be assigned priority only when using Earley (future versions may support LALR as well). | |||
| Priority can be either positive or negative. In not specified for a terminal, it's assumed to be 1 (i.e. the default). | |||
| ## Directives | |||
| ### %ignore | |||
| All occurrences of the terminal will be ignored, and won't be part of the parse. | |||
| Using the `%ignore` directive results in a cleaner grammar. | |||
| It's especially important for the LALR(1) algorithm, because adding whitespace (or comments, or other extranous elements) explicitly in the grammar, harms its predictive abilities, which are based on a lookahead of 1. | |||
| **Syntax:** | |||
| ```html | |||
| %ignore <TERMINAL> | |||
| ``` | |||
| **Examples:** | |||
| ```perl | |||
| %ignore " " | |||
| COMMENT: "#" /[^\n]/* | |||
| %ignore COMMENT | |||
| ``` | |||
| ### %import | |||
| Allows to import terminals and rules from lark grammars. | |||
| When importing rules, all their dependencies will be imported into a namespace, to avoid collisions. It's not possible to override their dependencies (e.g. like you would when inheriting a class). | |||
| **Syntax:** | |||
| ```html | |||
| %import <module>.<TERMINAL> | |||
| %import <module>.<rule> | |||
| %import <module>.<TERMINAL> -> <NEWTERMINAL> | |||
| %import <module>.<rule> -> <newrule> | |||
| %import <module> (<TERM1> <TERM2> <rule1> <rule2>) | |||
| ``` | |||
| If the module path is absolute, Lark will attempt to load it from the built-in directory (currently, only `common.lark` is available). | |||
| If the module path is relative, such as `.path.to.file`, Lark will attempt to load it from the current working directory. Grammars must have the `.lark` extension. | |||
| The rule or terminal can be imported under an other name with the `->` syntax. | |||
| **Example:** | |||
| ```perl | |||
| %import common.NUMBER | |||
| %import .terminals_file (A B C) | |||
| %import .rules_file.rulea -> ruleb | |||
| ``` | |||
| Note that `%ignore` directives cannot be imported. Imported rules will abide by the `%ignore` directives declared in the main grammar. | |||
| ### %declare | |||
| Declare a terminal without defining it. Useful for plugins. | |||
+ 63
- 0
docs/how_to_develop.md
View File
| @@ -0,0 +1,63 @@ | |||
| # How to develop Lark - Guide | |||
| There are many ways you can help the project: | |||
| * Help solve issues | |||
| * Improve the documentation | |||
| * Write new grammars for Lark's library | |||
| * Write a blog post introducing Lark to your audience | |||
| * Port Lark to another language | |||
| * Help me with code developemnt | |||
| If you're interested in taking one of these on, let me know and I will provide more details and assist you in the process. | |||
| ## Unit Tests | |||
| Lark comes with an extensive set of tests. Many of the tests will run several times, once for each parser configuration. | |||
| To run the tests, just go to the lark project root, and run the command: | |||
| ```bash | |||
| python -m tests | |||
| ``` | |||
| or | |||
| ```bash | |||
| pypy -m tests | |||
| ``` | |||
| For a list of supported interpreters, you can consult the `tox.ini` file. | |||
| You can also run a single unittest using its class and method name, for example: | |||
| ```bash | |||
| ## test_package test_class_name.test_function_name | |||
| python -m tests TestLalrStandard.test_lexer_error_recovering | |||
| ``` | |||
| ### tox | |||
| To run all Unit Tests with tox, | |||
| install tox and Python 2.7 up to the latest python interpreter supported (consult the file tox.ini). | |||
| Then, | |||
| run the command `tox` on the root of this project (where the main setup.py file is on). | |||
| And, for example, | |||
| if you would like to only run the Unit Tests for Python version 2.7, | |||
| you can run the command `tox -e py27` | |||
| ### pytest | |||
| You can also run the tests using pytest: | |||
| ```bash | |||
| pytest tests | |||
| ``` | |||
| ### Using setup.py | |||
| Another way to run the tests is using setup.py: | |||
| ```bash | |||
| python setup.py test | |||
| ``` | |||
+ 46
- 0
docs/how_to_use.md
View File
| @@ -0,0 +1,46 @@ | |||
| # How To Use Lark - Guide | |||
| ## Work process | |||
| This is the recommended process for working with Lark: | |||
| 1. Collect or create input samples, that demonstrate key features or behaviors in the language you're trying to parse. | |||
| 2. Write a grammar. Try to aim for a structure that is intuitive, and in a way that imitates how you would explain your language to a fellow human. | |||
| 3. Try your grammar in Lark against each input sample. Make sure the resulting parse-trees make sense. | |||
| 4. Use Lark's grammar features to [shape the tree](tree_construction.md): Get rid of superfluous rules by inlining them, and use aliases when specific cases need clarification. | |||
| - You can perform steps 1-4 repeatedly, gradually growing your grammar to include more sentences. | |||
| 5. Create a transformer to evaluate the parse-tree into a structure you'll be comfortable to work with. This may include evaluating literals, merging branches, or even converting the entire tree into your own set of AST classes. | |||
| Of course, some specific use-cases may deviate from this process. Feel free to suggest these cases, and I'll add them to this page. | |||
| ## Getting started | |||
| Browse the [Examples](https://github.com/lark-parser/lark/tree/master/examples) to find a template that suits your purposes. | |||
| Read the tutorials to get a better understanding of how everything works. (links in the [main page](/)) | |||
| Use the [Cheatsheet (PDF)](lark_cheatsheet.pdf) for quick reference. | |||
| Use the reference pages for more in-depth explanations. (links in the [main page](/)] | |||
| ## LALR usage | |||
| By default Lark silently resolves Shift/Reduce conflicts as Shift. To enable warnings pass `debug=True`. To get the messages printed you have to configure `logging` framework beforehand. For example: | |||
| ```python | |||
| from lark import Lark | |||
| import logging | |||
| logging.basicConfig(level=logging.DEBUG) | |||
| collision_grammar = ''' | |||
| start: as as | |||
| as: a* | |||
| a: "a" | |||
| ''' | |||
| p = Lark(collision_grammar, parser='lalr', debug=True) | |||
| ``` | |||
+ 51
- 0
docs/index.md
View File
| @@ -0,0 +1,51 @@ | |||
| # Lark | |||
| A modern parsing library for Python | |||
| ## Overview | |||
| Lark can parse any context-free grammar. | |||
| Lark provides: | |||
| - Advanced grammar language, based on EBNF | |||
| - Three parsing algorithms to choose from: Earley, LALR(1) and CYK | |||
| - Automatic tree construction, inferred from your grammar | |||
| - Fast unicode lexer with regexp support, and automatic line-counting | |||
| Lark's code is hosted on Github: [https://github.com/lark-parser/lark](https://github.com/lark-parser/lark) | |||
| ### Install | |||
| ```bash | |||
| $ pip install lark-parser | |||
| ``` | |||
| #### Syntax Highlighting | |||
| - [Sublime Text & TextMate](https://github.com/lark-parser/lark_syntax) | |||
| - [Visual Studio Code](https://github.com/lark-parser/vscode-lark) (Or install through the vscode plugin system) | |||
| ----- | |||
| ## Documentation Index | |||
| * [Philosophy & Design Choices](philosophy.md) | |||
| * [Full List of Features](features.md) | |||
| * [Examples](https://github.com/lark-parser/lark/tree/master/examples) | |||
| * Tutorials | |||
| * [How to write a DSL](http://blog.erezsh.com/how-to-write-a-dsl-in-python-with-lark/) - Implements a toy LOGO-like language with an interpreter | |||
| * [How to write a JSON parser](json_tutorial.md) | |||
| * External | |||
| * [Program Synthesis is Possible](https://www.cs.cornell.edu/~asampson/blog/minisynth.html) - Creates a DSL for Z3 | |||
| * Guides | |||
| * [How to use Lark](how_to_use.md) | |||
| * [How to develop Lark](how_to_develop.md) | |||
| * Reference | |||
| * [Grammar](grammar.md) | |||
| * [Tree Construction](tree_construction.md) | |||
| * [Classes](classes.md) | |||
| * [Cheatsheet (PDF)](lark_cheatsheet.pdf) | |||
| * Discussion | |||
| * [Gitter](https://gitter.im/lark-parser/Lobby) | |||
| * [Forum (Google Groups)](https://groups.google.com/forum/#!forum/lark-parser) | |||
+ 444
- 0
docs/json_tutorial.md
View File
| @@ -0,0 +1,444 @@ | |||
| # Lark Tutorial - JSON parser | |||
| Lark is a parser - a program that accepts a grammar and text, and produces a structured tree that represents that text. | |||
| In this tutorial we will write a JSON parser in Lark, and explore Lark's various features in the process. | |||
| It has 5 parts. | |||
| 1. Writing the grammar | |||
| 2. Creating the parser | |||
| 3. Shaping the tree | |||
| 4. Evaluating the tree | |||
| 5. Optimizing | |||
| Knowledge assumed: | |||
| - Using Python | |||
| - A basic understanding of how to use regular expressions | |||
| ## Part 1 - The Grammar | |||
| Lark accepts its grammars in a format called [EBNF](https://www.wikiwand.com/en/Extended_Backus%E2%80%93Naur_form). It basically looks like this: | |||
| rule_name : list of rules and TERMINALS to match | |||
| | another possible list of items | |||
| | etc. | |||
| TERMINAL: "some text to match" | |||
| (*a terminal is a string or a regular expression*) | |||
| The parser will try to match each rule (left-part) by matching its items (right-part) sequentially, trying each alternative (In practice, the parser is predictive so we don't have to try every alternative). | |||
| How to structure those rules is beyond the scope of this tutorial, but often it's enough to follow one's intuition. | |||
| In the case of JSON, the structure is simple: A json document is either a list, or a dictionary, or a string/number/etc. | |||
| The dictionaries and lists are recursive, and contain other json documents (or "values"). | |||
| Let's write this structure in EBNF form: | |||
| value: dict | |||
| | list | |||
| | STRING | |||
| | NUMBER | |||
| | "true" | "false" | "null" | |||
| list : "[" [value ("," value)*] "]" | |||
| dict : "{" [pair ("," pair)*] "}" | |||
| pair : STRING ":" value | |||
| A quick explanation of the syntax: | |||
| - Parenthesis let us group rules together. | |||
| - rule\* means *any amount*. That means, zero or more instances of that rule. | |||
| - [rule] means *optional*. That means zero or one instance of that rule. | |||
| Lark also supports the rule+ operator, meaning one or more instances. It also supports the rule? operator which is another way to say *optional*. | |||
| Of course, we still haven't defined "STRING" and "NUMBER". Luckily, both these literals are already defined in Lark's common library: | |||
| %import common.ESCAPED_STRING -> STRING | |||
| %import common.SIGNED_NUMBER -> NUMBER | |||
| The arrow (->) renames the terminals. But that only adds obscurity in this case, so going forward we'll just use their original names. | |||
| We'll also take care of the white-space, which is part of the text. | |||
| %import common.WS | |||
| %ignore WS | |||
| We tell our parser to ignore whitespace. Otherwise, we'd have to fill our grammar with WS terminals. | |||
| By the way, if you're curious what these terminals signify, they are roughly equivalent to this: | |||
| NUMBER : /-?\d+(\.\d+)?([eE][+-]?\d+)?/ | |||
| STRING : /".*?(?<!\\)"/ | |||
| %ignore /[ \t\n\f\r]+/ | |||
| Lark will accept this, if you really want to complicate your life :) | |||
| You can find the original definitions in [common.lark](/lark/grammars/common.lark). | |||
| They're don't strictly adhere to [json.org](https://json.org/) - but our purpose here is to accept json, not validate it. | |||
| Notice that terminals are written in UPPER-CASE, while rules are written in lower-case. | |||
| I'll touch more on the differences between rules and terminals later. | |||
| ## Part 2 - Creating the Parser | |||
| Once we have our grammar, creating the parser is very simple. | |||
| We simply instantiate Lark, and tell it to accept a "value": | |||
| ```python | |||
| from lark import Lark | |||
| json_parser = Lark(r""" | |||
| value: dict | |||
| | list | |||
| | ESCAPED_STRING | |||
| | SIGNED_NUMBER | |||
| | "true" | "false" | "null" | |||
| list : "[" [value ("," value)*] "]" | |||
| dict : "{" [pair ("," pair)*] "}" | |||
| pair : ESCAPED_STRING ":" value | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """, start='value') | |||
| ``` | |||
| It's that simple! Let's test it out: | |||
| ```python | |||
| >>> text = '{"key": ["item0", "item1", 3.14]}' | |||
| >>> json_parser.parse(text) | |||
| Tree(value, [Tree(dict, [Tree(pair, [Token(STRING, "key"), Tree(value, [Tree(list, [Tree(value, [Token(STRING, "item0")]), Tree(value, [Token(STRING, "item1")]), Tree(value, [Token(NUMBER, 3.14)])])])])])]) | |||
| >>> print( _.pretty() ) | |||
| value | |||
| dict | |||
| pair | |||
| "key" | |||
| value | |||
| list | |||
| value "item0" | |||
| value "item1" | |||
| value 3.14 | |||
| ``` | |||
| As promised, Lark automagically creates a tree that represents the parsed text. | |||
| But something is suspiciously missing from the tree. Where are the curly braces, the commas and all the other punctuation literals? | |||
| Lark automatically filters out literals from the tree, based on the following criteria: | |||
| - Filter out string literals without a name, or with a name that starts with an underscore. | |||
| - Keep regexps, even unnamed ones, unless their name starts with an underscore. | |||
| Unfortunately, this means that it will also filter out literals like "true" and "false", and we will lose that information. The next section, "Shaping the tree" deals with this issue, and others. | |||
| ## Part 3 - Shaping the Tree | |||
| We now have a parser that can create a parse tree (or: AST), but the tree has some issues: | |||
| 1. "true", "false" and "null" are filtered out (test it out yourself!) | |||
| 2. Is has useless branches, like *value*, that clutter-up our view. | |||
| I'll present the solution, and then explain it: | |||
| ?value: dict | |||
| | list | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| ... | |||
| string : ESCAPED_STRING | |||
| 1. Those little arrows signify *aliases*. An alias is a name for a specific part of the rule. In this case, we will name the *true/false/null* matches, and this way we won't lose the information. We also alias *SIGNED_NUMBER* to mark it for later processing. | |||
| 2. The question-mark prefixing *value* ("?value") tells the tree-builder to inline this branch if it has only one member. In this case, *value* will always have only one member, and will always be inlined. | |||
| 3. We turned the *ESCAPED_STRING* terminal into a rule. This way it will appear in the tree as a branch. This is equivalent to aliasing (like we did for the number), but now *string* can also be used elsewhere in the grammar (namely, in the *pair* rule). | |||
| Here is the new grammar: | |||
| ```python | |||
| from lark import Lark | |||
| json_parser = Lark(r""" | |||
| ?value: dict | |||
| | list | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| list : "[" [value ("," value)*] "]" | |||
| dict : "{" [pair ("," pair)*] "}" | |||
| pair : string ":" value | |||
| string : ESCAPED_STRING | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """, start='value') | |||
| ``` | |||
| And let's test it out: | |||
| ```python | |||
| >>> text = '{"key": ["item0", "item1", 3.14, true]}' | |||
| >>> print( json_parser.parse(text).pretty() ) | |||
| dict | |||
| pair | |||
| string "key" | |||
| list | |||
| string "item0" | |||
| string "item1" | |||
| number 3.14 | |||
| true | |||
| ``` | |||
| Ah! That is much much nicer. | |||
| ## Part 4 - Evaluating the tree | |||
| It's nice to have a tree, but what we really want is a JSON object. | |||
| The way to do it is to evaluate the tree, using a Transformer. | |||
| A transformer is a class with methods corresponding to branch names. For each branch, the appropriate method will be called with the children of the branch as its argument, and its return value will replace the branch in the tree. | |||
| So let's write a partial transformer, that handles lists and dictionaries: | |||
| ```python | |||
| from lark import Transformer | |||
| class MyTransformer(Transformer): | |||
| def list(self, items): | |||
| return list(items) | |||
| def pair(self, (k,v)): | |||
| return k, v | |||
| def dict(self, items): | |||
| return dict(items) | |||
| ``` | |||
| And when we run it, we get this: | |||
| ```python | |||
| >>> tree = json_parser.parse(text) | |||
| >>> MyTransformer().transform(tree) | |||
| {Tree(string, [Token(ANONRE_1, "key")]): [Tree(string, [Token(ANONRE_1, "item0")]), Tree(string, [Token(ANONRE_1, "item1")]), Tree(number, [Token(ANONRE_0, 3.14)]), Tree(true, [])]} | |||
| ``` | |||
| This is pretty close. Let's write a full transformer that can handle the terminals too. | |||
| Also, our definitions of list and dict are a bit verbose. We can do better: | |||
| ```python | |||
| from lark import Transformer | |||
| class TreeToJson(Transformer): | |||
| def string(self, (s,)): | |||
| return s[1:-1] | |||
| def number(self, (n,)): | |||
| return float(n) | |||
| list = list | |||
| pair = tuple | |||
| dict = dict | |||
| null = lambda self, _: None | |||
| true = lambda self, _: True | |||
| false = lambda self, _: False | |||
| ``` | |||
| And when we run it: | |||
| ```python | |||
| >>> tree = json_parser.parse(text) | |||
| >>> TreeToJson().transform(tree) | |||
| {u'key': [u'item0', u'item1', 3.14, True]} | |||
| ``` | |||
| Magic! | |||
| ## Part 5 - Optimizing | |||
| ### Step 1 - Benchmark | |||
| By now, we have a fully working JSON parser, that can accept a string of JSON, and return its Pythonic representation. | |||
| But how fast is it? | |||
| Now, of course there are JSON libraries for Python written in C, and we can never compete with them. But since this is applicable to any parser you would write in Lark, let's see how far we can take this. | |||
| The first step for optimizing is to have a benchmark. For this benchmark I'm going to take data from [json-generator.com/](http://www.json-generator.com/). I took their default suggestion and changed it to 5000 objects. The result is a 6.6MB sparse JSON file. | |||
| Our first program is going to be just a concatenation of everything we've done so far: | |||
| ```python | |||
| import sys | |||
| from lark import Lark, Transformer | |||
| json_grammar = r""" | |||
| ?value: dict | |||
| | list | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| list : "[" [value ("," value)*] "]" | |||
| dict : "{" [pair ("," pair)*] "}" | |||
| pair : string ":" value | |||
| string : ESCAPED_STRING | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """ | |||
| class TreeToJson(Transformer): | |||
| def string(self, (s,)): | |||
| return s[1:-1] | |||
| def number(self, (n,)): | |||
| return float(n) | |||
| list = list | |||
| pair = tuple | |||
| dict = dict | |||
| null = lambda self, _: None | |||
| true = lambda self, _: True | |||
| false = lambda self, _: False | |||
| json_parser = Lark(json_grammar, start='value', lexer='standard') | |||
| if __name__ == '__main__': | |||
| with open(sys.argv[1]) as f: | |||
| tree = json_parser.parse(f.read()) | |||
| print(TreeToJson().transform(tree)) | |||
| ``` | |||
| We run it and get this: | |||
| $ time python tutorial_json.py json_data > /dev/null | |||
| real 0m36.257s | |||
| user 0m34.735s | |||
| sys 0m1.361s | |||
| That's unsatisfactory time for a 6MB file. Maybe if we were parsing configuration or a small DSL, but we're trying to handle large amount of data here. | |||
| Well, turns out there's quite a bit we can do about it! | |||
| ### Step 2 - LALR(1) | |||
| So far we've been using the Earley algorithm, which is the default in Lark. Earley is powerful but slow. But it just so happens that our grammar is LR-compatible, and specifically LALR(1) compatible. | |||
| So let's switch to LALR(1) and see what happens: | |||
| ```python | |||
| json_parser = Lark(json_grammar, start='value', parser='lalr') | |||
| ``` | |||
| $ time python tutorial_json.py json_data > /dev/null | |||
| real 0m7.554s | |||
| user 0m7.352s | |||
| sys 0m0.148s | |||
| Ah, that's much better. The resulting JSON is of course exactly the same. You can run it for yourself and see. | |||
| It's important to note that not all grammars are LR-compatible, and so you can't always switch to LALR(1). But there's no harm in trying! If Lark lets you build the grammar, it means you're good to go. | |||
| ### Step 3 - Tree-less LALR(1) | |||
| So far, we've built a full parse tree for our JSON, and then transformed it. It's a convenient method, but it's not the most efficient in terms of speed and memory. Luckily, Lark lets us avoid building the tree when parsing with LALR(1). | |||
| Here's the way to do it: | |||
| ```python | |||
| json_parser = Lark(json_grammar, start='value', parser='lalr', transformer=TreeToJson()) | |||
| if __name__ == '__main__': | |||
| with open(sys.argv[1]) as f: | |||
| print( json_parser.parse(f.read()) ) | |||
| ``` | |||
| We've used the transformer we've already written, but this time we plug it straight into the parser. Now it can avoid building the parse tree, and just send the data straight into our transformer. The *parse()* method now returns the transformed JSON, instead of a tree. | |||
| Let's benchmark it: | |||
| real 0m4.866s | |||
| user 0m4.722s | |||
| sys 0m0.121s | |||
| That's a measurable improvement! Also, this way is more memory efficient. Check out the benchmark table at the end to see just how much. | |||
| As a general practice, it's recommended to work with parse trees, and only skip the tree-builder when your transformer is already working. | |||
| ### Step 4 - PyPy | |||
| PyPy is a JIT engine for running Python, and it's designed to be a drop-in replacement. | |||
| Lark is written purely in Python, which makes it very suitable for PyPy. | |||
| Let's get some free performance: | |||
| $ time pypy tutorial_json.py json_data > /dev/null | |||
| real 0m1.397s | |||
| user 0m1.296s | |||
| sys 0m0.083s | |||
| PyPy is awesome! | |||
| ### Conclusion | |||
| We've brought the run-time down from 36 seconds to 1.1 seconds, in a series of small and simple steps. | |||
| Now let's compare the benchmarks in a nicely organized table. | |||
| I measured memory consumption using a little script called [memusg](https://gist.github.com/netj/526585) | |||
| | Code | CPython Time | PyPy Time | CPython Mem | PyPy Mem | |||
| |:-----|:-------------|:------------|:----------|:--------- | |||
| | Lark - Earley *(with lexer)* | 42s | 4s | 1167M | 608M | | |||
| | Lark - LALR(1) | 8s | 1.53s | 453M | 266M | | |||
| | Lark - LALR(1) tree-less | 4.76s | 1.23s | 70M | 134M | | |||
| | PyParsing ([Parser](http://pyparsing.wikispaces.com/file/view/jsonParser.py)) | 32s | 3.53s | 443M | 225M | | |||
| | funcparserlib ([Parser](https://github.com/vlasovskikh/funcparserlib/blob/master/funcparserlib/tests/json.py)) | 8.5s | 1.3s | 483M | 293M | | |||
| | Parsimonious ([Parser](https://gist.githubusercontent.com/reclosedev/5222560/raw/5e97cf7eb62c3a3671885ec170577285e891f7d5/parsimonious_json.py)) | ? | 5.7s | ? | 1545M | | |||
| I added a few other parsers for comparison. PyParsing and funcparselib fair pretty well in their memory usage (they don't build a tree), but they can't compete with the run-time speed of LALR(1). | |||
| These benchmarks are for Lark's alpha version. I already have several optimizations planned that will significantly improve run-time speed. | |||
| Once again, shout-out to PyPy for being so effective. | |||
| ## Afterword | |||
| This is the end of the tutorial. I hoped you liked it and learned a little about Lark. | |||
| To see what else you can do with Lark, check out the [examples](/examples). | |||
| For questions or any other subject, feel free to email me at erezshin at gmail dot com. | |||
BIN
docs/lark_cheatsheet.pdf
View File
+ 49
- 0
docs/parsers.md
View File
| @@ -0,0 +1,49 @@ | |||
| Lark implements the following parsing algorithms: Earley, LALR(1), and CYK | |||
| # Earley | |||
| An [Earley Parser](https://www.wikiwand.com/en/Earley_parser) is a chart parser capable of parsing any context-free grammar at O(n^3), and O(n^2) when the grammar is unambiguous. It can parse most LR grammars at O(n). Most programming languages are LR, and can be parsed at a linear time. | |||
| Lark's Earley implementation runs on top of a skipping chart parser, which allows it to use regular expressions, instead of matching characters one-by-one. This is a huge improvement to Earley that is unique to Lark. This feature is used by default, but can also be requested explicitely using `lexer='dynamic'`. | |||
| It's possible to bypass the dynamic lexing, and use the regular Earley parser with a traditional lexer, that tokenizes as an independant first step. Doing so will provide a speed benefit, but will tokenize without using Earley's ambiguity-resolution ability. So choose this only if you know why! Activate with `lexer='standard'` | |||
| **SPPF & Ambiguity resolution** | |||
| Lark implements the Shared Packed Parse Forest data-structure for the Earley parser, in order to reduce the space and computation required to handle ambiguous grammars. | |||
| You can read more about SPPF [here](http://www.bramvandersanden.com/post/2014/06/shared-packed-parse-forest/) | |||
| As a result, Lark can efficiently parse and store every ambiguity in the grammar, when using Earley. | |||
| Lark provides the following options to combat ambiguity: | |||
| 1) Lark will choose the best derivation for you (default). Users can choose between different disambiguation strategies, and can prioritize (or demote) individual rules over others, using the rule-priority syntax. | |||
| 2) Users may choose to recieve the set of all possible parse-trees (using ambiguity='explicit'), and choose the best derivation themselves. While simple and flexible, it comes at the cost of space and performance, and so it isn't recommended for highly ambiguous grammars, or very long inputs. | |||
| 3) As an advanced feature, users may use specialized visitors to iterate the SPPF themselves. Future versions of Lark intend to improve and simplify this interface. | |||
| **dynamic_complete** | |||
| **TODO: Add documentation on dynamic_complete** | |||
| # LALR(1) | |||
| [LALR(1)](https://www.wikiwand.com/en/LALR_parser) is a very efficient, true-and-tested parsing algorithm. It's incredibly fast and requires very little memory. It can parse most programming languages (For example: Python and Java). | |||
| Lark comes with an efficient implementation that outperforms every other parsing library for Python (including PLY) | |||
| Lark extends the traditional YACC-based architecture with a *contextual lexer*, which automatically provides feedback from the parser to the lexer, making the LALR(1) algorithm stronger than ever. | |||
| The contextual lexer communicates with the parser, and uses the parser's lookahead prediction to narrow its choice of tokens. So at each point, the lexer only matches the subgroup of terminals that are legal at that parser state, instead of all of the terminals. It’s surprisingly effective at resolving common terminal collisions, and allows to parse languages that LALR(1) was previously incapable of parsing. | |||
| This is an improvement to LALR(1) that is unique to Lark. | |||
| # CYK Parser | |||
| A [CYK parser](https://www.wikiwand.com/en/CYK_algorithm) can parse any context-free grammar at O(n^3*|G|). | |||
| Its too slow to be practical for simple grammars, but it offers good performance for highly ambiguous grammars. | |||
+ 63
- 0
docs/philosophy.md
View File
| @@ -0,0 +1,63 @@ | |||
| # Philosophy | |||
| Parsers are innately complicated and confusing. They're difficult to understand, difficult to write, and difficult to use. Even experts on the subject can become baffled by the nuances of these complicated state-machines. | |||
| Lark's mission is to make the process of writing them as simple and abstract as possible, by following these design principles: | |||
| ### Design Principles | |||
| 1. Readability matters | |||
| 2. Keep the grammar clean and simple | |||
| 2. Don't force the user to decide on things that the parser can figure out on its own | |||
| 4. Usability is more important than performance | |||
| 5. Performance is still very important | |||
| 6. Follow the Zen Of Python, whenever possible and applicable | |||
| In accordance with these principles, I arrived at the following design choices: | |||
| ----------- | |||
| # Design Choices | |||
| ### 1. Separation of code and grammar | |||
| Grammars are the de-facto reference for your language, and for the structure of your parse-tree. For any non-trivial language, the conflation of code and grammar always turns out convoluted and difficult to read. | |||
| The grammars in Lark are EBNF-inspired, so they are especially easy to read & work with. | |||
| ### 2. Always build a parse-tree (unless told not to) | |||
| Trees are always simpler to work with than state-machines. | |||
| 1. Trees allow you to see the "state-machine" visually | |||
| 2. Trees allow your computation to be aware of previous and future states | |||
| 3. Trees allow you to process the parse in steps, instead of forcing you to do it all at once. | |||
| And anyway, every parse-tree can be replayed as a state-machine, so there is no loss of information. | |||
| See this answer in more detail [here](https://github.com/erezsh/lark/issues/4). | |||
| To improve performance, you can skip building the tree for LALR(1), by providing Lark with a transformer (see the [JSON example](https://github.com/erezsh/lark/blob/master/examples/json_parser.py)). | |||
| ### 3. Earley is the default | |||
| The Earley algorithm can accept *any* context-free grammar you throw at it (i.e. any grammar you can write in EBNF, it can parse). That makes it extremely friendly to beginners, who are not aware of the strange and arbitrary restrictions that LALR(1) places on its grammars. | |||
| As the users grow to understand the structure of their grammar, the scope of their target language, and their performance requirements, they may choose to switch over to LALR(1) to gain a huge performance boost, possibly at the cost of some language features. | |||
| In short, "Premature optimization is the root of all evil." | |||
| ### Other design features | |||
| - Automatically resolve terminal collisions whenever possible | |||
| - Automatically keep track of line & column numbers | |||
+ 76
- 0
docs/recipes.md
View File
| @@ -0,0 +1,76 @@ | |||
| # Recipes | |||
| A collection of recipes to use Lark and its various features | |||
| ## lexer_callbacks | |||
| Use it to interface with the lexer as it generates tokens. | |||
| Accepts a dictionary of the form | |||
| {TOKEN_TYPE: callback} | |||
| Where callback is of type `f(Token) -> Token` | |||
| It only works with the standard and contextual lexers. | |||
| ### Example 1: Replace string values with ints for INT tokens | |||
| ```python | |||
| from lark import Lark, Token | |||
| def tok_to_int(tok): | |||
| "Convert the value of `tok` from string to int, while maintaining line number & column." | |||
| # tok.type == 'INT' | |||
| return Token.new_borrow_pos(tok.type, int(tok), tok) | |||
| parser = Lark(""" | |||
| start: INT* | |||
| %import common.INT | |||
| %ignore " " | |||
| """, parser="lalr", lexer_callbacks = {'INT': tok_to_int}) | |||
| print(parser.parse('3 14 159')) | |||
| ``` | |||
| Prints out: | |||
| ```python | |||
| Tree(start, [Token(INT, 3), Token(INT, 14), Token(INT, 159)]) | |||
| ``` | |||
| ### Example 2: Collect all comments | |||
| ```python | |||
| from lark import Lark | |||
| comments = [] | |||
| parser = Lark(""" | |||
| start: INT* | |||
| COMMENT: /#.*/ | |||
| %import common (INT, WS) | |||
| %ignore COMMENT | |||
| %ignore WS | |||
| """, parser="lalr", lexer_callbacks={'COMMENT': comments.append}) | |||
| parser.parse(""" | |||
| 1 2 3 # hello | |||
| # world | |||
| 4 5 6 | |||
| """) | |||
| print(comments) | |||
| ``` | |||
| Prints out: | |||
| ```python | |||
| [Token(COMMENT, '# hello'), Token(COMMENT, '# world')] | |||
| ``` | |||
| *Note: We don't have to return a token, because comments are ignored* | |||
+ 147
- 0
docs/tree_construction.md
View File
| @@ -0,0 +1,147 @@ | |||
| # Automatic Tree Construction - Reference | |||
| Lark builds a tree automatically based on the structure of the grammar, where each rule that is matched becomes a branch (node) in the tree, and its children are its matches, in the order of matching. | |||
| For example, the rule `node: child1 child2` will create a tree node with two children. If it is matched as part of another rule (i.e. if it isn't the root), the new rule's tree node will become its parent. | |||
| Using `item+` or `item*` will result in a list of items, equivalent to writing `item item item ..`. | |||
| ### Terminals | |||
| Terminals are always values in the tree, never branches. | |||
| Lark filters out certain types of terminals by default, considering them punctuation: | |||
| - Terminals that won't appear in the tree are: | |||
| - Unnamed literals (like `"keyword"` or `"+"`) | |||
| - Terminals whose name starts with an underscore (like `_DIGIT`) | |||
| - Terminals that *will* appear in the tree are: | |||
| - Unnamed regular expressions (like `/[0-9]/`) | |||
| - Named terminals whose name starts with a letter (like `DIGIT`) | |||
| Note: Terminals composed of literals and other terminals always include the entire match without filtering any part. | |||
| **Example:** | |||
| ``` | |||
| start: PNAME pname | |||
| PNAME: "(" NAME ")" | |||
| pname: "(" NAME ")" | |||
| NAME: /\w+/ | |||
| %ignore /\s+/ | |||
| ``` | |||
| Lark will parse "(Hello) (World)" as: | |||
| start | |||
| (Hello) | |||
| pname World | |||
| Rules prefixed with `!` will retain all their literals regardless. | |||
| **Example:** | |||
| ```perl | |||
| expr: "(" expr ")" | |||
| | NAME+ | |||
| NAME: /\w+/ | |||
| %ignore " " | |||
| ``` | |||
| Lark will parse "((hello world))" as: | |||
| expr | |||
| expr | |||
| expr | |||
| "hello" | |||
| "world" | |||
| The brackets do not appear in the tree by design. The words appear because they are matched by a named terminal. | |||
| # Shaping the tree | |||
| Users can alter the automatic construction of the tree using a collection of grammar features. | |||
| * Rules whose name begins with an underscore will be inlined into their containing rule. | |||
| **Example:** | |||
| ```perl | |||
| start: "(" _greet ")" | |||
| _greet: /\w+/ /\w+/ | |||
| ``` | |||
| Lark will parse "(hello world)" as: | |||
| start | |||
| "hello" | |||
| "world" | |||
| * Rules that receive a question mark (?) at the beginning of their definition, will be inlined if they have a single child, after filtering. | |||
| **Example:** | |||
| ```ruby | |||
| start: greet greet | |||
| ?greet: "(" /\w+/ ")" | |||
| | /\w+/ /\w+/ | |||
| ``` | |||
| Lark will parse "hello world (planet)" as: | |||
| start | |||
| greet | |||
| "hello" | |||
| "world" | |||
| "planet" | |||
| * Rules that begin with an exclamation mark will keep all their terminals (they won't get filtered). | |||
| ```perl | |||
| !expr: "(" expr ")" | |||
| | NAME+ | |||
| NAME: /\w+/ | |||
| %ignore " " | |||
| ``` | |||
| Will parse "((hello world))" as: | |||
| expr | |||
| ( | |||
| expr | |||
| ( | |||
| expr | |||
| hello | |||
| world | |||
| ) | |||
| ) | |||
| Using the `!` prefix is usually a "code smell", and may point to a flaw in your grammar design. | |||
| * Aliases - options in a rule can receive an alias. It will be then used as the branch name for the option, instead of the rule name. | |||
| **Example:** | |||
| ```ruby | |||
| start: greet greet | |||
| greet: "hello" | |||
| | "world" -> planet | |||
| ``` | |||
| Lark will parse "hello world" as: | |||
| start | |||
| greet | |||
| planet | |||
+ 0
- 13
doupdate.sh
View File
| @@ -1,13 +0,0 @@ | |||
| #!/bin/sh | |||
| runtime=$(TZ=UTC date +'%Y-%m-%dT%HZ') | |||
| while read repourl name c; do | |||
| baseref="gm/$runtime/$name" | |||
| mkdir -p "gm/$name" | |||
| git ls-remote "$repourl" > "gm/$name/${runtime}.refs.txt" | |||
| #dr="--dry-run" | |||
| git fetch $dr --no-tags "$repourl" +refs/tags/*:refs/tags/"$baseref/*" +refs/heads/*:refs/heads/"$baseref/*" | |||
| done <<EOF | |||
| $(python3 reponames.py < repos.txt) | |||
| EOF | |||
+ 33
- 0
examples/README.md
View File
| @@ -0,0 +1,33 @@ | |||
| # Examples for Lark | |||
| #### How to run the examples | |||
| After cloning the repo, open the terminal into the root directory of the project, and run the following: | |||
| ```bash | |||
| [lark]$ python -m examples.<name_of_example> | |||
| ``` | |||
| For example, the following will parse all the Python files in the standard library of your local installation: | |||
| ```bash | |||
| [lark]$ python -m examples.python_parser | |||
| ``` | |||
| ### Beginners | |||
| - [calc.py](calc.py) - A simple example of a REPL calculator | |||
| - [json\_parser.py](json_parser.py) - A simple JSON parser (comes with a tutorial, see docs) | |||
| - [indented\_tree.py](indented\_tree.py) - A demonstration of parsing indentation ("whitespace significant" language) | |||
| - [fruitflies.py](fruitflies.py) - A demonstration of ambiguity | |||
| - [turtle\_dsl.py](turtle_dsl.py) - Implements a LOGO-like toy language for Python's turtle, with interpreter. | |||
| - [lark\_grammar.py](lark_grammar.py) + [lark.lark](lark.lark) - A reference implementation of the Lark grammar (using LALR(1) + standard lexer) | |||
| ### Advanced | |||
| - [error\_reporting\_lalr.py](error_reporting_lalr.py) - A demonstration of example-driven error reporting with the LALR parser | |||
| - [python\_parser.py](python_parser.py) - A fully-working Python 2 & 3 parser (but not production ready yet!) | |||
| - [conf\_lalr.py](conf_lalr.py) - Demonstrates the power of LALR's contextual lexer on a toy configuration language | |||
| - [conf\_earley.py](conf_earley.py) - Demonstrates the power of Earley's dynamic lexer on a toy configuration language | |||
| - [custom\_lexer.py](custom_lexer.py) - Demonstrates using a custom lexer to parse a non-textual stream of data | |||
| - [reconstruct\_json.py](reconstruct_json.py) - Demonstrates the experimental text-reconstruction feature | |||
+ 0
- 0
examples/__init__.py
View File
+ 75
- 0
examples/calc.py
View File
| @@ -0,0 +1,75 @@ | |||
| # | |||
| # This example shows how to write a basic calculator with variables. | |||
| # | |||
| from lark import Lark, Transformer, v_args | |||
| try: | |||
| input = raw_input # For Python2 compatibility | |||
| except NameError: | |||
| pass | |||
| calc_grammar = """ | |||
| ?start: sum | |||
| | NAME "=" sum -> assign_var | |||
| ?sum: product | |||
| | sum "+" product -> add | |||
| | sum "-" product -> sub | |||
| ?product: atom | |||
| | product "*" atom -> mul | |||
| | product "/" atom -> div | |||
| ?atom: NUMBER -> number | |||
| | "-" atom -> neg | |||
| | NAME -> var | |||
| | "(" sum ")" | |||
| %import common.CNAME -> NAME | |||
| %import common.NUMBER | |||
| %import common.WS_INLINE | |||
| %ignore WS_INLINE | |||
| """ | |||
| @v_args(inline=True) # Affects the signatures of the methods | |||
| class CalculateTree(Transformer): | |||
| from operator import add, sub, mul, truediv as div, neg | |||
| number = float | |||
| def __init__(self): | |||
| self.vars = {} | |||
| def assign_var(self, name, value): | |||
| self.vars[name] = value | |||
| return value | |||
| def var(self, name): | |||
| return self.vars[name] | |||
| calc_parser = Lark(calc_grammar, parser='lalr', transformer=CalculateTree()) | |||
| calc = calc_parser.parse | |||
| def main(): | |||
| while True: | |||
| try: | |||
| s = input('> ') | |||
| except EOFError: | |||
| break | |||
| print(calc(s)) | |||
| def test(): | |||
| print(calc("a = 1+2")) | |||
| print(calc("1+a*-3")) | |||
| if __name__ == '__main__': | |||
| # test() | |||
| main() | |||
+ 42
- 0
examples/conf_earley.py
View File
| @@ -0,0 +1,42 @@ | |||
| # | |||
| # This example demonstrates parsing using the dynamic-lexer earley frontend | |||
| # | |||
| # Using a lexer for configuration files is tricky, because values don't | |||
| # have to be surrounded by delimiters. Using a standard lexer for this just won't work. | |||
| # | |||
| # In this example we use a dynamic lexer and let the Earley parser resolve the ambiguity. | |||
| # | |||
| # Another approach is to use the contextual lexer with LALR. It is less powerful than Earley, | |||
| # but it can handle some ambiguity when lexing and it's much faster. | |||
| # See examples/conf_lalr.py for an example of that approach. | |||
| # | |||
| from lark import Lark | |||
| parser = Lark(r""" | |||
| start: _NL? section+ | |||
| section: "[" NAME "]" _NL item+ | |||
| item: NAME "=" VALUE? _NL | |||
| VALUE: /./+ | |||
| %import common.CNAME -> NAME | |||
| %import common.NEWLINE -> _NL | |||
| %import common.WS_INLINE | |||
| %ignore WS_INLINE | |||
| """, parser="earley") | |||
| def test(): | |||
| sample_conf = """ | |||
| [bla] | |||
| a=Hello | |||
| this="that",4 | |||
| empty= | |||
| """ | |||
| r = parser.parse(sample_conf) | |||
| print (r.pretty()) | |||
| if __name__ == '__main__': | |||
| test() | |||
+ 38
- 0
examples/conf_lalr.py
View File
| @@ -0,0 +1,38 @@ | |||
| # | |||
| # This example demonstrates the power of the contextual lexer, by parsing a config file. | |||
| # | |||
| # The tokens NAME and VALUE match the same input. A standard lexer would arbitrarily | |||
| # choose one over the other, which would lead to a (confusing) parse error. | |||
| # However, due to the unambiguous structure of the grammar, Lark's LALR(1) algorithm knows | |||
| # which one of them to expect at each point during the parse. | |||
| # The lexer then only matches the tokens that the parser expects. | |||
| # The result is a correct parse, something that is impossible with a regular lexer. | |||
| # | |||
| # Another approach is to discard a lexer altogether and use the Earley algorithm. | |||
| # It will handle more cases than the contextual lexer, but at the cost of performance. | |||
| # See examples/conf_earley.py for an example of that approach. | |||
| # | |||
| from lark import Lark | |||
| parser = Lark(r""" | |||
| start: _NL? section+ | |||
| section: "[" NAME "]" _NL item+ | |||
| item: NAME "=" VALUE? _NL | |||
| VALUE: /./+ | |||
| %import common.CNAME -> NAME | |||
| %import common.NEWLINE -> _NL | |||
| %import common.WS_INLINE | |||
| %ignore WS_INLINE | |||
| """, parser="lalr") | |||
| sample_conf = """ | |||
| [bla] | |||
| a=Hello | |||
| this="that",4 | |||
| empty= | |||
| """ | |||
| print(parser.parse(sample_conf).pretty()) | |||
+ 56
- 0
examples/custom_lexer.py
View File
| @@ -0,0 +1,56 @@ | |||
| # | |||
| # This example demonstrates using Lark with a custom lexer. | |||
| # | |||
| # You can use a custom lexer to tokenize text when the lexers offered by Lark | |||
| # are too slow, or not flexible enough. | |||
| # | |||
| # You can also use it (as shown in this example) to tokenize streams of objects. | |||
| # | |||
| from lark import Lark, Transformer, v_args | |||
| from lark.lexer import Lexer, Token | |||
| class TypeLexer(Lexer): | |||
| def __init__(self, lexer_conf): | |||
| pass | |||
| def lex(self, data): | |||
| for obj in data: | |||
| if isinstance(obj, int): | |||
| yield Token('INT', obj) | |||
| elif isinstance(obj, (type(''), type(u''))): | |||
| yield Token('STR', obj) | |||
| else: | |||
| raise TypeError(obj) | |||
| parser = Lark(""" | |||
| start: data_item+ | |||
| data_item: STR INT* | |||
| %declare STR INT | |||
| """, parser='lalr', lexer=TypeLexer) | |||
| class ParseToDict(Transformer): | |||
| @v_args(inline=True) | |||
| def data_item(self, name, *numbers): | |||
| return name.value, [n.value for n in numbers] | |||
| start = dict | |||
| def test(): | |||
| data = ['alice', 1, 27, 3, 'bob', 4, 'carrie', 'dan', 8, 6] | |||
| print(data) | |||
| tree = parser.parse(data) | |||
| res = ParseToDict().transform(tree) | |||
| print('-->') | |||
| print(res) # prints {'alice': [1, 27, 3], 'bob': [4], 'carrie': [], 'dan': [8, 6]} | |||
| if __name__ == '__main__': | |||
| test() | |||
+ 76
- 0
examples/error_reporting_lalr.py
View File
| @@ -0,0 +1,76 @@ | |||
| # | |||
| # This demonstrates example-driven error reporting with the LALR parser | |||
| # | |||
| from lark import Lark, UnexpectedInput | |||
| from .json_parser import json_grammar # Using the grammar from the json_parser example | |||
| json_parser = Lark(json_grammar, parser='lalr') | |||
| class JsonSyntaxError(SyntaxError): | |||
| def __str__(self): | |||
| context, line, column = self.args | |||
| return '%s at line %s, column %s.\n\n%s' % (self.label, line, column, context) | |||
| class JsonMissingValue(JsonSyntaxError): | |||
| label = 'Missing Value' | |||
| class JsonMissingOpening(JsonSyntaxError): | |||
| label = 'Missing Opening' | |||
| class JsonMissingClosing(JsonSyntaxError): | |||
| label = 'Missing Closing' | |||
| class JsonMissingComma(JsonSyntaxError): | |||
| label = 'Missing Comma' | |||
| class JsonTrailingComma(JsonSyntaxError): | |||
| label = 'Trailing Comma' | |||
| def parse(json_text): | |||
| try: | |||
| j = json_parser.parse(json_text) | |||
| except UnexpectedInput as u: | |||
| exc_class = u.match_examples(json_parser.parse, { | |||
| JsonMissingOpening: ['{"foo": ]}', | |||
| '{"foor": }}', | |||
| '{"foo": }'], | |||
| JsonMissingClosing: ['{"foo": [}', | |||
| '{', | |||
| '{"a": 1', | |||
| '[1'], | |||
| JsonMissingComma: ['[1 2]', | |||
| '[false 1]', | |||
| '["b" 1]', | |||
| '{"a":true 1:4}', | |||
| '{"a":1 1:4}', | |||
| '{"a":"b" 1:4}'], | |||
| JsonTrailingComma: ['[,]', | |||
| '[1,]', | |||
| '[1,2,]', | |||
| '{"foo":1,}', | |||
| '{"foo":false,"bar":true,}'] | |||
| }) | |||
| if not exc_class: | |||
| raise | |||
| raise exc_class(u.get_context(json_text), u.line, u.column) | |||
| def test(): | |||
| try: | |||
| parse('{"example1": "value"') | |||
| except JsonMissingClosing as e: | |||
| print(e) | |||
| try: | |||
| parse('{"example2": ] ') | |||
| except JsonMissingOpening as e: | |||
| print(e) | |||
| if __name__ == '__main__': | |||
| test() | |||
BIN
examples/fruitflies.png
View File
{kind=link}
| Before | After |
|---|---|
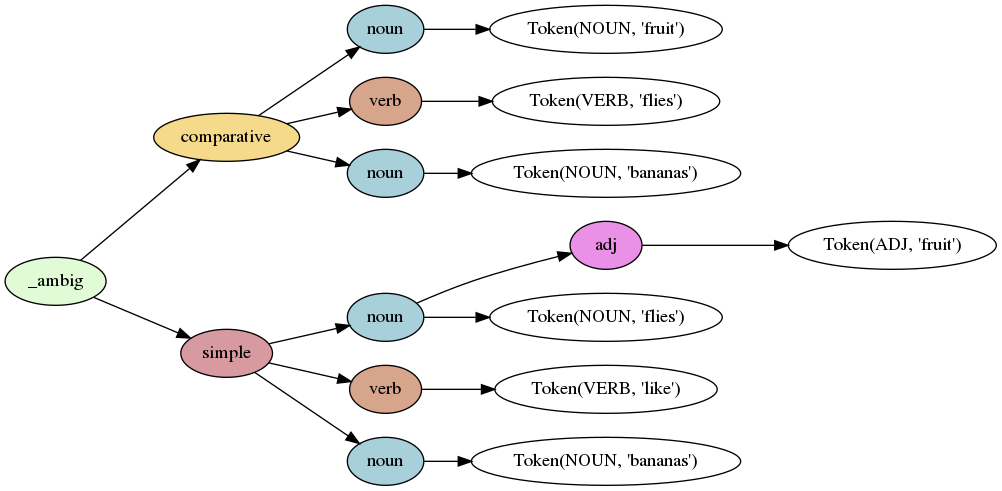
|
|
| Width: 1002 | Height: 491 | Size: 92 KiB |
+ 49
- 0
examples/fruitflies.py
View File
| @@ -0,0 +1,49 @@ | |||
| # | |||
| # This example shows how to use get explicit ambiguity from Lark's Earley parser. | |||
| # | |||
| import sys | |||
| from lark import Lark, tree | |||
| grammar = """ | |||
| sentence: noun verb noun -> simple | |||
| | noun verb "like" noun -> comparative | |||
| noun: adj? NOUN | |||
| verb: VERB | |||
| adj: ADJ | |||
| NOUN: "flies" | "bananas" | "fruit" | |||
| VERB: "like" | "flies" | |||
| ADJ: "fruit" | |||
| %import common.WS | |||
| %ignore WS | |||
| """ | |||
| parser = Lark(grammar, start='sentence', ambiguity='explicit') | |||
| sentence = 'fruit flies like bananas' | |||
| def make_png(filename): | |||
| tree.pydot__tree_to_png( parser.parse(sentence), filename) | |||
| if __name__ == '__main__': | |||
| print(parser.parse(sentence).pretty()) | |||
| # make_png(sys.argv[1]) | |||
| # Output: | |||
| # | |||
| # _ambig | |||
| # comparative | |||
| # noun fruit | |||
| # verb flies | |||
| # noun bananas | |||
| # simple | |||
| # noun | |||
| # fruit | |||
| # flies | |||
| # verb like | |||
| # noun bananas | |||
| # | |||
| # (or view a nicer version at "./fruitflies.png") | |||
+ 52
- 0
examples/indented_tree.py
View File
| @@ -0,0 +1,52 @@ | |||
| # | |||
| # This example demonstrates usage of the Indenter class. | |||
| # | |||
| # Since indentation is context-sensitive, a postlex stage is introduced to | |||
| # manufacture INDENT/DEDENT tokens. | |||
| # | |||
| # It is crucial for the indenter that the NL_type matches | |||
| # the spaces (and tabs) after the newline. | |||
| # | |||
| from lark import Lark | |||
| from lark.indenter import Indenter | |||
| tree_grammar = r""" | |||
| ?start: _NL* tree | |||
| tree: NAME _NL [_INDENT tree+ _DEDENT] | |||
| %import common.CNAME -> NAME | |||
| %import common.WS_INLINE | |||
| %declare _INDENT _DEDENT | |||
| %ignore WS_INLINE | |||
| _NL: /(\r?\n[\t ]*)+/ | |||
| """ | |||
| class TreeIndenter(Indenter): | |||
| NL_type = '_NL' | |||
| OPEN_PAREN_types = [] | |||
| CLOSE_PAREN_types = [] | |||
| INDENT_type = '_INDENT' | |||
| DEDENT_type = '_DEDENT' | |||
| tab_len = 8 | |||
| parser = Lark(tree_grammar, parser='lalr', postlex=TreeIndenter()) | |||
| test_tree = """ | |||
| a | |||
| b | |||
| c | |||
| d | |||
| e | |||
| f | |||
| g | |||
| """ | |||
| def test(): | |||
| print(parser.parse(test_tree).pretty()) | |||
| if __name__ == '__main__': | |||
| test() | |||
+ 81
- 0
examples/json_parser.py
View File
| @@ -0,0 +1,81 @@ | |||
| # | |||
| # This example shows how to write a basic JSON parser | |||
| # | |||
| # The code is short and clear, and outperforms every other parser (that's written in Python). | |||
| # For an explanation, check out the JSON parser tutorial at /docs/json_tutorial.md | |||
| # | |||
| import sys | |||
| from lark import Lark, Transformer, v_args | |||
| json_grammar = r""" | |||
| ?start: value | |||
| ?value: object | |||
| | array | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| array : "[" [value ("," value)*] "]" | |||
| object : "{" [pair ("," pair)*] "}" | |||
| pair : string ":" value | |||
| string : ESCAPED_STRING | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """ | |||
| class TreeToJson(Transformer): | |||
| @v_args(inline=True) | |||
| def string(self, s): | |||
| return s[1:-1].replace('\\"', '"') | |||
| array = list | |||
| pair = tuple | |||
| object = dict | |||
| number = v_args(inline=True)(float) | |||
| null = lambda self, _: None | |||
| true = lambda self, _: True | |||
| false = lambda self, _: False | |||
| # json_parser = Lark(json_grammar, parser='earley', lexer='standard') | |||
| # def parse(x): | |||
| # return TreeToJson().transform(json_parser.parse(x)) | |||
| json_parser = Lark(json_grammar, parser='lalr', lexer='standard', transformer=TreeToJson()) | |||
| parse = json_parser.parse | |||
| def test(): | |||
| test_json = ''' | |||
| { | |||
| "empty_object" : {}, | |||
| "empty_array" : [], | |||
| "booleans" : { "YES" : true, "NO" : false }, | |||
| "numbers" : [ 0, 1, -2, 3.3, 4.4e5, 6.6e-7 ], | |||
| "strings" : [ "This", [ "And" , "That", "And a \\"b" ] ], | |||
| "nothing" : null | |||
| } | |||
| ''' | |||
| j = parse(test_json) | |||
| print(j) | |||
| import json | |||
| assert j == json.loads(test_json) | |||
| if __name__ == '__main__': | |||
| # test() | |||
| with open(sys.argv[1]) as f: | |||
| print(parse(f.read())) | |||
+ 50
- 0
examples/lark.lark
View File
| @@ -0,0 +1,50 @@ | |||
| start: (_item | _NL)* | |||
| _item: rule | |||
| | token | |||
| | statement | |||
| rule: RULE priority? ":" expansions _NL | |||
| token: TOKEN priority? ":" expansions _NL | |||
| priority: "." NUMBER | |||
| statement: "%ignore" expansions _NL -> ignore | |||
| | "%import" import_args ["->" name] _NL -> import | |||
| | "%declare" name+ -> declare | |||
| import_args: "."? name ("." name)* | |||
| ?expansions: alias (_VBAR alias)* | |||
| ?alias: expansion ["->" RULE] | |||
| ?expansion: expr* | |||
| ?expr: atom [OP | "~" NUMBER [".." NUMBER]] | |||
| ?atom: "(" expansions ")" | |||
| | "[" expansions "]" -> maybe | |||
| | STRING ".." STRING -> literal_range | |||
| | name | |||
| | (REGEXP | STRING) -> literal | |||
| name: RULE | |||
| | TOKEN | |||
| _VBAR: _NL? "|" | |||
| OP: /[+*][?]?|[?](?![a-z])/ | |||
| RULE: /!?[_?]?[a-z][_a-z0-9]*/ | |||
| TOKEN: /_?[A-Z][_A-Z0-9]*/ | |||
| STRING: _STRING "i"? | |||
| REGEXP: /\/(?!\/)(\\\/|\\\\|[^\/\n])*?\/[imslux]*/ | |||
| _NL: /(\r?\n)+\s*/ | |||
| %import common.ESCAPED_STRING -> _STRING | |||
| %import common.INT -> NUMBER | |||
| %import common.WS_INLINE | |||
| COMMENT: "//" /[^\n]/* | |||
| %ignore WS_INLINE | |||
| %ignore COMMENT | |||
+ 21
- 0
examples/lark_grammar.py
View File
| @@ -0,0 +1,21 @@ | |||
| from lark import Lark | |||
| parser = Lark(open('examples/lark.lark'), parser="lalr") | |||
| grammar_files = [ | |||
| 'examples/python2.lark', | |||
| 'examples/python3.lark', | |||
| 'examples/lark.lark', | |||
| 'examples/relative-imports/multiples.lark', | |||
| 'examples/relative-imports/multiple2.lark', | |||
| 'examples/relative-imports/multiple3.lark', | |||
| 'lark/grammars/common.lark', | |||
| ] | |||
| def test(): | |||
| for grammar_file in grammar_files: | |||
| tree = parser.parse(open(grammar_file).read()) | |||
| print("All grammars parsed successfully") | |||
| if __name__ == '__main__': | |||
| test() | |||
+ 168
- 0
examples/python2.lark
View File
| @@ -0,0 +1,168 @@ | |||
| // Python 2 grammar for Lark | |||
| // NOTE: Work in progress!!! (XXX TODO) | |||
| // This grammar should parse all python 2.x code successfully, | |||
| // but the resulting parse-tree is still not well-organized. | |||
| // Adapted from: https://docs.python.org/2/reference/grammar.html | |||
| // Adapted by: Erez Shinan | |||
| // Start symbols for the grammar: | |||
| // single_input is a single interactive statement; | |||
| // file_input is a module or sequence of commands read from an input file; | |||
| // eval_input is the input for the eval() and input() functions. | |||
| // NB: compound_stmt in single_input is followed by extra _NEWLINE! | |||
| single_input: _NEWLINE | simple_stmt | compound_stmt _NEWLINE | |||
| ?file_input: (_NEWLINE | stmt)* | |||
| eval_input: testlist _NEWLINE? | |||
| decorator: "@" dotted_name [ "(" [arglist] ")" ] _NEWLINE | |||
| decorators: decorator+ | |||
| decorated: decorators (classdef | funcdef) | |||
| funcdef: "def" NAME "(" parameters ")" ":" suite | |||
| parameters: [paramlist] | |||
| paramlist: param ("," param)* ["," [star_params ["," kw_params] | kw_params]] | |||
| | star_params ["," kw_params] | |||
| | kw_params | |||
| star_params: "*" NAME | |||
| kw_params: "**" NAME | |||
| param: fpdef ["=" test] | |||
| fpdef: NAME | "(" fplist ")" | |||
| fplist: fpdef ("," fpdef)* [","] | |||
| ?stmt: simple_stmt | compound_stmt | |||
| ?simple_stmt: small_stmt (";" small_stmt)* [";"] _NEWLINE | |||
| ?small_stmt: (expr_stmt | print_stmt | del_stmt | pass_stmt | flow_stmt | |||
| | import_stmt | global_stmt | exec_stmt | assert_stmt) | |||
| expr_stmt: testlist augassign (yield_expr|testlist) -> augassign2 | |||
| | testlist ("=" (yield_expr|testlist))+ -> assign | |||
| | testlist | |||
| augassign: ("+=" | "-=" | "*=" | "/=" | "%=" | "&=" | "|=" | "^=" | "<<=" | ">>=" | "**=" | "//=") | |||
| // For normal assignments, additional restrictions enforced by the interpreter | |||
| print_stmt: "print" ( [ test ("," test)* [","] ] | ">>" test [ ("," test)+ [","] ] ) | |||
| del_stmt: "del" exprlist | |||
| pass_stmt: "pass" | |||
| ?flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt | |||
| break_stmt: "break" | |||
| continue_stmt: "continue" | |||
| return_stmt: "return" [testlist] | |||
| yield_stmt: yield_expr | |||
| raise_stmt: "raise" [test ["," test ["," test]]] | |||
| import_stmt: import_name | import_from | |||
| import_name: "import" dotted_as_names | |||
| import_from: "from" ("."* dotted_name | "."+) "import" ("*" | "(" import_as_names ")" | import_as_names) | |||
| ?import_as_name: NAME ["as" NAME] | |||
| ?dotted_as_name: dotted_name ["as" NAME] | |||
| import_as_names: import_as_name ("," import_as_name)* [","] | |||
| dotted_as_names: dotted_as_name ("," dotted_as_name)* | |||
| dotted_name: NAME ("." NAME)* | |||
| global_stmt: "global" NAME ("," NAME)* | |||
| exec_stmt: "exec" expr ["in" test ["," test]] | |||
| assert_stmt: "assert" test ["," test] | |||
| ?compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | |||
| if_stmt: "if" test ":" suite ("elif" test ":" suite)* ["else" ":" suite] | |||
| while_stmt: "while" test ":" suite ["else" ":" suite] | |||
| for_stmt: "for" exprlist "in" testlist ":" suite ["else" ":" suite] | |||
| try_stmt: ("try" ":" suite ((except_clause ":" suite)+ ["else" ":" suite] ["finally" ":" suite] | "finally" ":" suite)) | |||
| with_stmt: "with" with_item ("," with_item)* ":" suite | |||
| with_item: test ["as" expr] | |||
| // NB compile.c makes sure that the default except clause is last | |||
| except_clause: "except" [test [("as" | ",") test]] | |||
| suite: simple_stmt | _NEWLINE _INDENT _NEWLINE? stmt+ _DEDENT _NEWLINE? | |||
| // Backward compatibility cruft to support: | |||
| // [ x for x in lambda: True, lambda: False if x() ] | |||
| // even while also allowing: | |||
| // lambda x: 5 if x else 2 | |||
| // (But not a mix of the two) | |||
| testlist_safe: old_test [("," old_test)+ [","]] | |||
| old_test: or_test | old_lambdef | |||
| old_lambdef: "lambda" [paramlist] ":" old_test | |||
| ?test: or_test ["if" or_test "else" test] | lambdef | |||
| ?or_test: and_test ("or" and_test)* | |||
| ?and_test: not_test ("and" not_test)* | |||
| ?not_test: "not" not_test | comparison | |||
| ?comparison: expr (comp_op expr)* | |||
| comp_op: "<"|">"|"=="|">="|"<="|"<>"|"!="|"in"|"not" "in"|"is"|"is" "not" | |||
| ?expr: xor_expr ("|" xor_expr)* | |||
| ?xor_expr: and_expr ("^" and_expr)* | |||
| ?and_expr: shift_expr ("&" shift_expr)* | |||
| ?shift_expr: arith_expr (("<<"|">>") arith_expr)* | |||
| ?arith_expr: term (("+"|"-") term)* | |||
| ?term: factor (("*"|"/"|"%"|"//") factor)* | |||
| ?factor: ("+"|"-"|"~") factor | power | |||
| ?power: molecule ["**" factor] | |||
| // _trailer: "(" [arglist] ")" | "[" subscriptlist "]" | "." NAME | |||
| ?molecule: molecule "(" [arglist] ")" -> func_call | |||
| | molecule "[" [subscriptlist] "]" -> getitem | |||
| | molecule "." NAME -> getattr | |||
| | atom | |||
| ?atom: "(" [yield_expr|testlist_comp] ")" -> tuple | |||
| | "[" [listmaker] "]" | |||
| | "{" [dictorsetmaker] "}" | |||
| | "`" testlist1 "`" | |||
| | "(" test ")" | |||
| | NAME | number | string+ | |||
| listmaker: test ( list_for | ("," test)* [","] ) | |||
| ?testlist_comp: test ( comp_for | ("," test)+ [","] | ",") | |||
| lambdef: "lambda" [paramlist] ":" test | |||
| ?subscriptlist: subscript ("," subscript)* [","] | |||
| subscript: "." "." "." | test | [test] ":" [test] [sliceop] | |||
| sliceop: ":" [test] | |||
| ?exprlist: expr ("," expr)* [","] | |||
| ?testlist: test ("," test)* [","] | |||
| dictorsetmaker: ( (test ":" test (comp_for | ("," test ":" test)* [","])) | (test (comp_for | ("," test)* [","])) ) | |||
| classdef: "class" NAME ["(" [testlist] ")"] ":" suite | |||
| arglist: (argument ",")* (argument [","] | |||
| | star_args ["," kw_args] | |||
| | kw_args) | |||
| star_args: "*" test | |||
| kw_args: "**" test | |||
| // The reason that keywords are test nodes instead of NAME is that using NAME | |||
| // results in an ambiguity. ast.c makes sure it's a NAME. | |||
| argument: test [comp_for] | test "=" test | |||
| list_iter: list_for | list_if | |||
| list_for: "for" exprlist "in" testlist_safe [list_iter] | |||
| list_if: "if" old_test [list_iter] | |||
| comp_iter: comp_for | comp_if | |||
| comp_for: "for" exprlist "in" or_test [comp_iter] | |||
| comp_if: "if" old_test [comp_iter] | |||
| testlist1: test ("," test)* | |||
| yield_expr: "yield" [testlist] | |||
| number: DEC_NUMBER | HEX_NUMBER | OCT_NUMBER | FLOAT | IMAG_NUMBER | |||
| string: STRING | LONG_STRING | |||
| // Tokens | |||
| COMMENT: /#[^\n]*/ | |||
| _NEWLINE: ( /\r?\n[\t ]*/ | COMMENT )+ | |||
| STRING : /[ubf]?r?("(?!"").*?(?<!\\)(\\\\)*?"|'(?!'').*?(?<!\\)(\\\\)*?')/i | |||
| LONG_STRING.2: /[ubf]?r?(""".*?(?<!\\)(\\\\)*?"""|'''.*?(?<!\\)(\\\\)*?''')/is | |||
| DEC_NUMBER: /[1-9]\d*l?/i | |||
| HEX_NUMBER: /0x[\da-f]*l?/i | |||
| OCT_NUMBER: /0o?[0-7]*l?/i | |||
| %import common.FLOAT -> FLOAT | |||
| %import common.INT -> _INT | |||
| %import common.CNAME -> NAME | |||
| IMAG_NUMBER: (_INT | FLOAT) ("j"|"J") | |||
| %ignore /[\t \f]+/ // WS | |||
| %ignore /\\[\t \f]*\r?\n/ // LINE_CONT | |||
| %ignore COMMENT | |||
| %declare _INDENT _DEDENT | |||
+ 187
- 0
examples/python3.lark
View File
| @@ -0,0 +1,187 @@ | |||
| // Python 3 grammar for Lark | |||
| // NOTE: Work in progress!!! (XXX TODO) | |||
| // This grammar should parse all python 3.x code successfully, | |||
| // but the resulting parse-tree is still not well-organized. | |||
| // Adapted from: https://docs.python.org/3/reference/grammar.html | |||
| // Adapted by: Erez Shinan | |||
| // Start symbols for the grammar: | |||
| // single_input is a single interactive statement; | |||
| // file_input is a module or sequence of commands read from an input file; | |||
| // eval_input is the input for the eval() functions. | |||
| // NB: compound_stmt in single_input is followed by extra NEWLINE! | |||
| single_input: _NEWLINE | simple_stmt | compound_stmt _NEWLINE | |||
| file_input: (_NEWLINE | stmt)* | |||
| eval_input: testlist _NEWLINE* | |||
| decorator: "@" dotted_name [ "(" [arguments] ")" ] _NEWLINE | |||
| decorators: decorator+ | |||
| decorated: decorators (classdef | funcdef | async_funcdef) | |||
| async_funcdef: "async" funcdef | |||
| funcdef: "def" NAME "(" parameters? ")" ["->" test] ":" suite | |||
| parameters: paramvalue ("," paramvalue)* ["," [ starparams | kwparams]] | |||
| | starparams | |||
| | kwparams | |||
| starparams: "*" typedparam? ("," paramvalue)* ["," kwparams] | |||
| kwparams: "**" typedparam | |||
| ?paramvalue: typedparam ["=" test] | |||
| ?typedparam: NAME [":" test] | |||
| varargslist: (vfpdef ["=" test] ("," vfpdef ["=" test])* ["," [ "*" [vfpdef] ("," vfpdef ["=" test])* ["," ["**" vfpdef [","]]] | "**" vfpdef [","]]] | |||
| | "*" [vfpdef] ("," vfpdef ["=" test])* ["," ["**" vfpdef [","]]] | |||
| | "**" vfpdef [","]) | |||
| vfpdef: NAME | |||
| ?stmt: simple_stmt | compound_stmt | |||
| ?simple_stmt: small_stmt (";" small_stmt)* [";"] _NEWLINE | |||
| ?small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) | |||
| ?expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) | |||
| | ("=" (yield_expr|testlist_star_expr))*) | |||
| annassign: ":" test ["=" test] | |||
| ?testlist_star_expr: (test|star_expr) ("," (test|star_expr))* [","] | |||
| !augassign: ("+=" | "-=" | "*=" | "@=" | "/=" | "%=" | "&=" | "|=" | "^=" | "<<=" | ">>=" | "**=" | "//=") | |||
| // For normal and annotated assignments, additional restrictions enforced by the interpreter | |||
| del_stmt: "del" exprlist | |||
| pass_stmt: "pass" | |||
| ?flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt | |||
| break_stmt: "break" | |||
| continue_stmt: "continue" | |||
| return_stmt: "return" [testlist] | |||
| yield_stmt: yield_expr | |||
| raise_stmt: "raise" [test ["from" test]] | |||
| import_stmt: import_name | import_from | |||
| import_name: "import" dotted_as_names | |||
| // note below: the ("." | "...") is necessary because "..." is tokenized as ELLIPSIS | |||
| import_from: "from" (dots? dotted_name | dots) "import" ("*" | "(" import_as_names ")" | import_as_names) | |||
| !dots: "."+ | |||
| import_as_name: NAME ["as" NAME] | |||
| dotted_as_name: dotted_name ["as" NAME] | |||
| import_as_names: import_as_name ("," import_as_name)* [","] | |||
| dotted_as_names: dotted_as_name ("," dotted_as_name)* | |||
| dotted_name: NAME ("." NAME)* | |||
| global_stmt: "global" NAME ("," NAME)* | |||
| nonlocal_stmt: "nonlocal" NAME ("," NAME)* | |||
| assert_stmt: "assert" test ["," test] | |||
| compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt | |||
| async_stmt: "async" (funcdef | with_stmt | for_stmt) | |||
| if_stmt: "if" test ":" suite ("elif" test ":" suite)* ["else" ":" suite] | |||
| while_stmt: "while" test ":" suite ["else" ":" suite] | |||
| for_stmt: "for" exprlist "in" testlist ":" suite ["else" ":" suite] | |||
| try_stmt: ("try" ":" suite ((except_clause ":" suite)+ ["else" ":" suite] ["finally" ":" suite] | "finally" ":" suite)) | |||
| with_stmt: "with" with_item ("," with_item)* ":" suite | |||
| with_item: test ["as" expr] | |||
| // NB compile.c makes sure that the default except clause is last | |||
| except_clause: "except" [test ["as" NAME]] | |||
| suite: simple_stmt | _NEWLINE _INDENT stmt+ _DEDENT | |||
| ?test: or_test ["if" or_test "else" test] | lambdef | |||
| ?test_nocond: or_test | lambdef_nocond | |||
| lambdef: "lambda" [varargslist] ":" test | |||
| lambdef_nocond: "lambda" [varargslist] ":" test_nocond | |||
| ?or_test: and_test ("or" and_test)* | |||
| ?and_test: not_test ("and" not_test)* | |||
| ?not_test: "not" not_test -> not | |||
| | comparison | |||
| ?comparison: expr (_comp_op expr)* | |||
| star_expr: "*" expr | |||
| ?expr: xor_expr ("|" xor_expr)* | |||
| ?xor_expr: and_expr ("^" and_expr)* | |||
| ?and_expr: shift_expr ("&" shift_expr)* | |||
| ?shift_expr: arith_expr (_shift_op arith_expr)* | |||
| ?arith_expr: term (_add_op term)* | |||
| ?term: factor (_mul_op factor)* | |||
| ?factor: _factor_op factor | power | |||
| !_factor_op: "+"|"-"|"~" | |||
| !_add_op: "+"|"-" | |||
| !_shift_op: "<<"|">>" | |||
| !_mul_op: "*"|"@"|"/"|"%"|"//" | |||
| // <> isn't actually a valid comparison operator in Python. It's here for the | |||
| // sake of a __future__ import described in PEP 401 (which really works :-) | |||
| !_comp_op: "<"|">"|"=="|">="|"<="|"<>"|"!="|"in"|"not" "in"|"is"|"is" "not" | |||
| ?power: await_expr ["**" factor] | |||
| ?await_expr: AWAIT? atom_expr | |||
| AWAIT: "await" | |||
| ?atom_expr: atom_expr "(" [arguments] ")" -> funccall | |||
| | atom_expr "[" subscriptlist "]" -> getitem | |||
| | atom_expr "." NAME -> getattr | |||
| | atom | |||
| ?atom: "(" [yield_expr|testlist_comp] ")" -> tuple | |||
| | "[" [testlist_comp] "]" -> list | |||
| | "{" [dictorsetmaker] "}" -> dict | |||
| | NAME -> var | |||
| | number | string+ | |||
| | "(" test ")" | |||
| | "..." -> ellipsis | |||
| | "None" -> const_none | |||
| | "True" -> const_true | |||
| | "False" -> const_false | |||
| ?testlist_comp: (test|star_expr) [comp_for | ("," (test|star_expr))+ [","] | ","] | |||
| subscriptlist: subscript ("," subscript)* [","] | |||
| subscript: test | [test] ":" [test] [sliceop] | |||
| sliceop: ":" [test] | |||
| exprlist: (expr|star_expr) ("," (expr|star_expr))* [","] | |||
| testlist: test ("," test)* [","] | |||
| dictorsetmaker: ( ((test ":" test | "**" expr) (comp_for | ("," (test ":" test | "**" expr))* [","])) | ((test | star_expr) (comp_for | ("," (test | star_expr))* [","])) ) | |||
| classdef: "class" NAME ["(" [arguments] ")"] ":" suite | |||
| arguments: argvalue ("," argvalue)* ["," [ starargs | kwargs]] | |||
| | starargs | |||
| | kwargs | |||
| | test comp_for | |||
| starargs: "*" test ("," "*" test)* ("," argvalue)* ["," kwargs] | |||
| kwargs: "**" test | |||
| ?argvalue: test ["=" test] | |||
| comp_iter: comp_for | comp_if | async_for | |||
| async_for: "async" "for" exprlist "in" or_test [comp_iter] | |||
| comp_for: "for" exprlist "in" or_test [comp_iter] | |||
| comp_if: "if" test_nocond [comp_iter] | |||
| // not used in grammar, but may appear in "node" passed from Parser to Compiler | |||
| encoding_decl: NAME | |||
| yield_expr: "yield" [yield_arg] | |||
| yield_arg: "from" test | testlist | |||
| number: DEC_NUMBER | HEX_NUMBER | BIN_NUMBER | OCT_NUMBER | FLOAT_NUMBER | IMAG_NUMBER | |||
| string: STRING | LONG_STRING | |||
| // Tokens | |||
| NAME: /[a-zA-Z_]\w*/ | |||
| COMMENT: /#[^\n]*/ | |||
| _NEWLINE: ( /\r?\n[\t ]*/ | COMMENT )+ | |||
| STRING : /[ubf]?r?("(?!"").*?(?<!\\)(\\\\)*?"|'(?!'').*?(?<!\\)(\\\\)*?')/i | |||
| LONG_STRING: /[ubf]?r?(""".*?(?<!\\)(\\\\)*?"""|'''.*?(?<!\\)(\\\\)*?''')/is | |||
| DEC_NUMBER: /0|[1-9]\d*/i | |||
| HEX_NUMBER.2: /0x[\da-f]*/i | |||
| OCT_NUMBER.2: /0o[0-7]*/i | |||
| BIN_NUMBER.2 : /0b[0-1]*/i | |||
| FLOAT_NUMBER.2: /((\d+\.\d*|\.\d+)(e[-+]?\d+)?|\d+(e[-+]?\d+))/i | |||
| IMAG_NUMBER.2: /\d+j/i | FLOAT_NUMBER "j"i | |||
| %ignore /[\t \f]+/ // WS | |||
| %ignore /\\[\t \f]*\r?\n/ // LINE_CONT | |||
| %ignore COMMENT | |||
| %declare _INDENT _DEDENT | |||
+ 82
- 0
examples/python_parser.py
View File
| @@ -0,0 +1,82 @@ | |||
| # | |||
| # This example demonstrates usage of the included Python grammars | |||
| # | |||
| import sys | |||
| import os, os.path | |||
| from io import open | |||
| import glob, time | |||
| from lark import Lark | |||
| from lark.indenter import Indenter | |||
| # __path__ = os.path.dirname(__file__) | |||
| class PythonIndenter(Indenter): | |||
| NL_type = '_NEWLINE' | |||
| OPEN_PAREN_types = ['LPAR', 'LSQB', 'LBRACE'] | |||
| CLOSE_PAREN_types = ['RPAR', 'RSQB', 'RBRACE'] | |||
| INDENT_type = '_INDENT' | |||
| DEDENT_type = '_DEDENT' | |||
| tab_len = 8 | |||
| kwargs = dict(rel_to=__file__, postlex=PythonIndenter(), start='file_input') | |||
| python_parser2 = Lark.open('python2.lark', parser='lalr', **kwargs) | |||
| python_parser3 = Lark.open('python3.lark',parser='lalr', **kwargs) | |||
| python_parser2_earley = Lark.open('python2.lark', parser='earley', lexer='standard', **kwargs) | |||
| def _read(fn, *args): | |||
| kwargs = {'encoding': 'iso-8859-1'} | |||
| with open(fn, *args, **kwargs) as f: | |||
| return f.read() | |||
| def _get_lib_path(): | |||
| if os.name == 'nt': | |||
| if 'PyPy' in sys.version: | |||
| return os.path.join(sys.prefix, 'lib-python', sys.winver) | |||
| else: | |||
| return os.path.join(sys.prefix, 'Lib') | |||
| else: | |||
| return [x for x in sys.path if x.endswith('%s.%s' % sys.version_info[:2])][0] | |||
| def test_python_lib(): | |||
| path = _get_lib_path() | |||
| start = time.time() | |||
| files = glob.glob(path+'/*.py') | |||
| for f in files: | |||
| print( f ) | |||
| try: | |||
| # print list(python_parser.lex(_read(os.path.join(path, f)) + '\n')) | |||
| try: | |||
| xrange | |||
| except NameError: | |||
| python_parser3.parse(_read(os.path.join(path, f)) + '\n') | |||
| else: | |||
| python_parser2.parse(_read(os.path.join(path, f)) + '\n') | |||
| except: | |||
| print ('At %s' % f) | |||
| raise | |||
| end = time.time() | |||
| print( "test_python_lib (%d files), time: %s secs"%(len(files), end-start) ) | |||
| def test_earley_equals_lalr(): | |||
| path = _get_lib_path() | |||
| files = glob.glob(path+'/*.py') | |||
| for f in files: | |||
| print( f ) | |||
| tree1 = python_parser2.parse(_read(os.path.join(path, f)) + '\n') | |||
| tree2 = python_parser2_earley.parse(_read(os.path.join(path, f)) + '\n') | |||
| assert tree1 == tree2 | |||
| if __name__ == '__main__': | |||
| test_python_lib() | |||
| # test_earley_equals_lalr() | |||
| # python_parser3.parse(_read(sys.argv[1]) + '\n') | |||
+ 201
- 0
examples/qscintilla_json.py
View File
| @@ -0,0 +1,201 @@ | |||
| # | |||
| # This example shows how to write a syntax-highlighted editor with Qt and Lark | |||
| # | |||
| # Requirements: | |||
| # | |||
| # PyQt5==5.10.1 | |||
| # QScintilla==2.10.4 | |||
| import sys | |||
| import textwrap | |||
| from PyQt5.Qt import * # noqa | |||
| from PyQt5.Qsci import QsciScintilla | |||
| from PyQt5.Qsci import QsciLexerCustom | |||
| from lark import Lark | |||
| class LexerJson(QsciLexerCustom): | |||
| def __init__(self, parent=None): | |||
| super().__init__(parent) | |||
| self.create_parser() | |||
| self.create_styles() | |||
| def create_styles(self): | |||
| deeppink = QColor(249, 38, 114) | |||
| khaki = QColor(230, 219, 116) | |||
| mediumpurple = QColor(174, 129, 255) | |||
| mediumturquoise = QColor(81, 217, 205) | |||
| yellowgreen = QColor(166, 226, 46) | |||
| lightcyan = QColor(213, 248, 232) | |||
| darkslategrey = QColor(39, 40, 34) | |||
| styles = { | |||
| 0: mediumturquoise, | |||
| 1: mediumpurple, | |||
| 2: yellowgreen, | |||
| 3: deeppink, | |||
| 4: khaki, | |||
| 5: lightcyan | |||
| } | |||
| for style, color in styles.items(): | |||
| self.setColor(color, style) | |||
| self.setPaper(darkslategrey, style) | |||
| self.setFont(self.parent().font(), style) | |||
| self.token_styles = { | |||
| "COLON": 5, | |||
| "COMMA": 5, | |||
| "LBRACE": 5, | |||
| "LSQB": 5, | |||
| "RBRACE": 5, | |||
| "RSQB": 5, | |||
| "FALSE": 0, | |||
| "NULL": 0, | |||
| "TRUE": 0, | |||
| "STRING": 4, | |||
| "NUMBER": 1, | |||
| } | |||
| def create_parser(self): | |||
| grammar = ''' | |||
| anons: ":" "{" "}" "," "[" "]" | |||
| TRUE: "true" | |||
| FALSE: "false" | |||
| NULL: "NULL" | |||
| %import common.ESCAPED_STRING -> STRING | |||
| %import common.SIGNED_NUMBER -> NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| ''' | |||
| self.lark = Lark(grammar, parser=None, lexer='standard') | |||
| # All tokens: print([t.name for t in self.lark.parser.lexer.tokens]) | |||
| def defaultPaper(self, style): | |||
| return QColor(39, 40, 34) | |||
| def language(self): | |||
| return "Json" | |||
| def description(self, style): | |||
| return {v: k for k, v in self.token_styles.items()}.get(style, "") | |||
| def styleText(self, start, end): | |||
| self.startStyling(start) | |||
| text = self.parent().text()[start:end] | |||
| last_pos = 0 | |||
| try: | |||
| for token in self.lark.lex(text): | |||
| ws_len = token.pos_in_stream - last_pos | |||
| if ws_len: | |||
| self.setStyling(ws_len, 0) # whitespace | |||
| token_len = len(bytearray(token, "utf-8")) | |||
| self.setStyling( | |||
| token_len, self.token_styles.get(token.type, 0)) | |||
| last_pos = token.pos_in_stream + token_len | |||
| except Exception as e: | |||
| print(e) | |||
| class EditorAll(QsciScintilla): | |||
| def __init__(self, parent=None): | |||
| super().__init__(parent) | |||
| # Set font defaults | |||
| font = QFont() | |||
| font.setFamily('Consolas') | |||
| font.setFixedPitch(True) | |||
| font.setPointSize(8) | |||
| font.setBold(True) | |||
| self.setFont(font) | |||
| # Set margin defaults | |||
| fontmetrics = QFontMetrics(font) | |||
| self.setMarginsFont(font) | |||
| self.setMarginWidth(0, fontmetrics.width("000") + 6) | |||
| self.setMarginLineNumbers(0, True) | |||
| self.setMarginsForegroundColor(QColor(128, 128, 128)) | |||
| self.setMarginsBackgroundColor(QColor(39, 40, 34)) | |||
| self.setMarginType(1, self.SymbolMargin) | |||
| self.setMarginWidth(1, 12) | |||
| # Set indentation defaults | |||
| self.setIndentationsUseTabs(False) | |||
| self.setIndentationWidth(4) | |||
| self.setBackspaceUnindents(True) | |||
| self.setIndentationGuides(True) | |||
| # self.setFolding(QsciScintilla.CircledFoldStyle) | |||
| # Set caret defaults | |||
| self.setCaretForegroundColor(QColor(247, 247, 241)) | |||
| self.setCaretWidth(2) | |||
| # Set selection color defaults | |||
| self.setSelectionBackgroundColor(QColor(61, 61, 52)) | |||
| self.resetSelectionForegroundColor() | |||
| # Set multiselection defaults | |||
| self.SendScintilla(QsciScintilla.SCI_SETMULTIPLESELECTION, True) | |||
| self.SendScintilla(QsciScintilla.SCI_SETMULTIPASTE, 1) | |||
| self.SendScintilla( | |||
| QsciScintilla.SCI_SETADDITIONALSELECTIONTYPING, True) | |||
| lexer = LexerJson(self) | |||
| self.setLexer(lexer) | |||
| EXAMPLE_TEXT = textwrap.dedent("""\ | |||
| { | |||
| "_id": "5b05ffcbcf8e597939b3f5ca", | |||
| "about": "Excepteur consequat commodo esse voluptate aute aliquip ad sint deserunt commodo eiusmod irure. Sint aliquip sit magna duis eu est culpa aliqua excepteur ut tempor nulla. Aliqua ex pariatur id labore sit. Quis sit ex aliqua veniam exercitation laboris anim adipisicing. Lorem nisi reprehenderit ullamco labore qui sit ut aliqua tempor consequat pariatur proident.", | |||
| "address": "665 Malbone Street, Thornport, Louisiana, 243", | |||
| "age": 23, | |||
| "balance": "$3,216.91", | |||
| "company": "BULLJUICE", | |||
| "email": "elisekelley@bulljuice.com", | |||
| "eyeColor": "brown", | |||
| "gender": "female", | |||
| "guid": "d3a6d865-0f64-4042-8a78-4f53de9b0707", | |||
| "index": 0, | |||
| "isActive": false, | |||
| "isActive2": true, | |||
| "latitude": -18.660714, | |||
| "longitude": -85.378048, | |||
| "name": "Elise Kelley", | |||
| "phone": "+1 (808) 543-3966", | |||
| "picture": "http://placehold.it/32x32", | |||
| "registered": "2017-09-30T03:47:40 -02:00", | |||
| "tags": [ | |||
| "et", | |||
| "nostrud", | |||
| "in", | |||
| "fugiat", | |||
| "incididunt", | |||
| "labore", | |||
| "nostrud" | |||
| ] | |||
| }\ | |||
| """) | |||
| def main(): | |||
| app = QApplication(sys.argv) | |||
| ex = EditorAll() | |||
| ex.setWindowTitle(__file__) | |||
| ex.setText(EXAMPLE_TEXT) | |||
| ex.resize(800, 600) | |||
| ex.show() | |||
| sys.exit(app.exec_()) | |||
| if __name__ == "__main__": | |||
| main() | |||
+ 52
- 0
examples/reconstruct_json.py
View File
| @@ -0,0 +1,52 @@ | |||
| # | |||
| # This example demonstrates an experimental feature: Text reconstruction | |||
| # The Reconstructor takes a parse tree (already filtered from punctuation, of course), | |||
| # and reconstructs it into correct text, that can be parsed correctly. | |||
| # It can be useful for creating "hooks" to alter data before handing it to other parsers. You can also use it to generate samples from scratch. | |||
| # | |||
| import json | |||
| from lark import Lark | |||
| from lark.reconstruct import Reconstructor | |||
| from .json_parser import json_grammar | |||
| test_json = ''' | |||
| { | |||
| "empty_object" : {}, | |||
| "empty_array" : [], | |||
| "booleans" : { "YES" : true, "NO" : false }, | |||
| "numbers" : [ 0, 1, -2, 3.3, 4.4e5, 6.6e-7 ], | |||
| "strings" : [ "This", [ "And" , "That", "And a \\"b" ] ], | |||
| "nothing" : null | |||
| } | |||
| ''' | |||
| def test_earley(): | |||
| json_parser = Lark(json_grammar) | |||
| tree = json_parser.parse(test_json) | |||
| # print ('@@', tree.pretty()) | |||
| # for x in tree.find_data('true'): | |||
| # x.data = 'false' | |||
| # # x.children[0].value = '"HAHA"' | |||
| new_json = Reconstructor(json_parser).reconstruct(tree) | |||
| print (new_json) | |||
| print (json.loads(new_json) == json.loads(test_json)) | |||
| def test_lalr(): | |||
| json_parser = Lark(json_grammar, parser='lalr') | |||
| tree = json_parser.parse(test_json) | |||
| new_json = Reconstructor(json_parser).reconstruct(tree) | |||
| print (new_json) | |||
| print (json.loads(new_json) == json.loads(test_json)) | |||
| test_earley() | |||
| test_lalr() | |||
+ 1
- 0
examples/relative-imports/multiple2.lark
View File
| @@ -0,0 +1 @@ | |||
| start: ("0" | "1")* "0" | |||
+ 5
- 0
examples/relative-imports/multiple3.lark
View File
| @@ -0,0 +1,5 @@ | |||
| start: mod0mod0+ | |||
| mod0mod0: "0" | "1" mod1mod0 | |||
| mod1mod0: "1" | "0" mod2mod1 mod1mod0 | |||
| mod2mod1: "0" | "1" mod2mod1 | |||
+ 5
- 0
examples/relative-imports/multiples.lark
View File
| @@ -0,0 +1,5 @@ | |||
| start: "2:" multiple2 | |||
| | "3:" multiple3 | |||
| %import .multiple2.start -> multiple2 | |||
| %import .multiple3.start -> multiple3 | |||
+ 28
- 0
examples/relative-imports/multiples.py
View File
| @@ -0,0 +1,28 @@ | |||
| # | |||
| # This example demonstrates relative imports with rule rewrite | |||
| # see multiples.lark | |||
| # | |||
| # | |||
| # if b is a number written in binary, and m is either 2 or 3, | |||
| # the grammar aims to recognise m:b iif b is a multiple of m | |||
| # | |||
| # for example, 3:1001 is recognised | |||
| # because 9 (0b1001) is a multiple of 3 | |||
| # | |||
| from lark import Lark, UnexpectedInput | |||
| parser = Lark.open('multiples.lark', parser='lalr') | |||
| def is_in_grammar(data): | |||
| try: | |||
| parser.parse(data) | |||
| except UnexpectedInput: | |||
| return False | |||
| return True | |||
| for n_dec in range(100): | |||
| n_bin = bin(n_dec)[2:] | |||
| assert is_in_grammar('2:{}'.format(n_bin)) == (n_dec % 2 == 0) | |||
| assert is_in_grammar('3:{}'.format(n_bin)) == (n_dec % 3 == 0) | |||
+ 1
- 0
examples/standalone/create_standalone.sh
View File
| @@ -0,0 +1 @@ | |||
| PYTHONPATH=../.. python -m lark.tools.standalone json.lark > json_parser.py | |||
+ 21
- 0
examples/standalone/json.lark
View File
| @@ -0,0 +1,21 @@ | |||
| ?start: value | |||
| ?value: object | |||
| | array | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| array : "[" [value ("," value)*] "]" | |||
| object : "{" [pair ("," pair)*] "}" | |||
| pair : string ":" value | |||
| string : ESCAPED_STRING | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
+ 1838
- 0
examples/standalone/json_parser.py
File diff suppressed because it is too large
View File
+ 25
- 0
examples/standalone/json_parser_main.py
View File
| @@ -0,0 +1,25 @@ | |||
| import sys | |||
| from json_parser import Lark_StandAlone, Transformer, inline_args | |||
| class TreeToJson(Transformer): | |||
| @inline_args | |||
| def string(self, s): | |||
| return s[1:-1].replace('\\"', '"') | |||
| array = list | |||
| pair = tuple | |||
| object = dict | |||
| number = inline_args(float) | |||
| null = lambda self, _: None | |||
| true = lambda self, _: True | |||
| false = lambda self, _: False | |||
| parser = Lark_StandAlone(transformer=TreeToJson()) | |||
| if __name__ == '__main__': | |||
| with open(sys.argv[1]) as f: | |||
| print(parser.parse(f.read())) | |||
+ 85
- 0
examples/turtle_dsl.py
View File
| @@ -0,0 +1,85 @@ | |||
| # This example implements a LOGO-like toy language for Python's turtle, with interpreter. | |||
| try: | |||
| input = raw_input # For Python2 compatibility | |||
| except NameError: | |||
| pass | |||
| import turtle | |||
| from lark import Lark | |||
| turtle_grammar = """ | |||
| start: instruction+ | |||
| instruction: MOVEMENT NUMBER -> movement | |||
| | "c" COLOR [COLOR] -> change_color | |||
| | "fill" code_block -> fill | |||
| | "repeat" NUMBER code_block -> repeat | |||
| code_block: "{" instruction+ "}" | |||
| MOVEMENT: "f"|"b"|"l"|"r" | |||
| COLOR: LETTER+ | |||
| %import common.LETTER | |||
| %import common.INT -> NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """ | |||
| parser = Lark(turtle_grammar) | |||
| def run_instruction(t): | |||
| if t.data == 'change_color': | |||
| turtle.color(*t.children) # We just pass the color names as-is | |||
| elif t.data == 'movement': | |||
| name, number = t.children | |||
| { 'f': turtle.fd, | |||
| 'b': turtle.bk, | |||
| 'l': turtle.lt, | |||
| 'r': turtle.rt, }[name](int(number)) | |||
| elif t.data == 'repeat': | |||
| count, block = t.children | |||
| for i in range(int(count)): | |||
| run_instruction(block) | |||
| elif t.data == 'fill': | |||
| turtle.begin_fill() | |||
| run_instruction(t.children[0]) | |||
| turtle.end_fill() | |||
| elif t.data == 'code_block': | |||
| for cmd in t.children: | |||
| run_instruction(cmd) | |||
| else: | |||
| raise SyntaxError('Unknown instruction: %s' % t.data) | |||
| def run_turtle(program): | |||
| parse_tree = parser.parse(program) | |||
| for inst in parse_tree.children: | |||
| run_instruction(inst) | |||
| def main(): | |||
| while True: | |||
| code = input('> ') | |||
| try: | |||
| run_turtle(code) | |||
| except Exception as e: | |||
| print(e) | |||
| def test(): | |||
| text = """ | |||
| c red yellow | |||
| fill { repeat 36 { | |||
| f200 l170 | |||
| }} | |||
| """ | |||
| run_turtle(text) | |||
| if __name__ == '__main__': | |||
| # test() | |||
| main() | |||
+ 8
- 0
lark/__init__.py
View File
| @@ -0,0 +1,8 @@ | |||
| from .tree import Tree | |||
| from .visitors import Transformer, Visitor, v_args, Discard | |||
| from .visitors import InlineTransformer, inline_args # XXX Deprecated | |||
| from .exceptions import ParseError, LexError, GrammarError, UnexpectedToken, UnexpectedInput, UnexpectedCharacters | |||
| from .lexer import Token | |||
| from .lark import Lark | |||
| __version__ = "0.7.3" | |||
+ 28
- 0
lark/common.py
View File
| @@ -0,0 +1,28 @@ | |||
| from .utils import Serialize | |||
| from .lexer import TerminalDef | |||
| ###{standalone | |||
| class LexerConf(Serialize): | |||
| __serialize_fields__ = 'tokens', 'ignore' | |||
| __serialize_namespace__ = TerminalDef, | |||
| def __init__(self, tokens, ignore=(), postlex=None, callbacks=None): | |||
| self.tokens = tokens | |||
| self.ignore = ignore | |||
| self.postlex = postlex | |||
| self.callbacks = callbacks or {} | |||
| def _deserialize(self): | |||
| self.callbacks = {} # TODO | |||
| ###} | |||
| class ParserConf: | |||
| def __init__(self, rules, callbacks, start): | |||
| assert isinstance(start, list) | |||
| self.rules = rules | |||
| self.callbacks = callbacks | |||
| self.start = start | |||
+ 98
- 0
lark/exceptions.py
View File
| @@ -0,0 +1,98 @@ | |||
| from .utils import STRING_TYPE | |||
| ###{standalone | |||
| class LarkError(Exception): | |||
| pass | |||
| class GrammarError(LarkError): | |||
| pass | |||
| class ParseError(LarkError): | |||
| pass | |||
| class LexError(LarkError): | |||
| pass | |||
| class UnexpectedInput(LarkError): | |||
| pos_in_stream = None | |||
| def get_context(self, text, span=40): | |||
| pos = self.pos_in_stream | |||
| start = max(pos - span, 0) | |||
| end = pos + span | |||
| before = text[start:pos].rsplit('\n', 1)[-1] | |||
| after = text[pos:end].split('\n', 1)[0] | |||
| return before + after + '\n' + ' ' * len(before) + '^\n' | |||
| def match_examples(self, parse_fn, examples): | |||
| """ Given a parser instance and a dictionary mapping some label with | |||
| some malformed syntax examples, it'll return the label for the | |||
| example that bests matches the current error. | |||
| """ | |||
| assert self.state is not None, "Not supported for this exception" | |||
| candidate = None | |||
| for label, example in examples.items(): | |||
| assert not isinstance(example, STRING_TYPE) | |||
| for malformed in example: | |||
| try: | |||
| parse_fn(malformed) | |||
| except UnexpectedInput as ut: | |||
| if ut.state == self.state: | |||
| try: | |||
| if ut.token == self.token: # Try exact match first | |||
| return label | |||
| except AttributeError: | |||
| pass | |||
| if not candidate: | |||
| candidate = label | |||
| return candidate | |||
| class UnexpectedCharacters(LexError, UnexpectedInput): | |||
| def __init__(self, seq, lex_pos, line, column, allowed=None, considered_tokens=None, state=None, token_history=None): | |||
| message = "No terminal defined for '%s' at line %d col %d" % (seq[lex_pos], line, column) | |||
| self.line = line | |||
| self.column = column | |||
| self.allowed = allowed | |||
| self.considered_tokens = considered_tokens | |||
| self.pos_in_stream = lex_pos | |||
| self.state = state | |||
| message += '\n\n' + self.get_context(seq) | |||
| if allowed: | |||
| message += '\nExpecting: %s\n' % allowed | |||
| if token_history: | |||
| message += '\nPrevious tokens: %s\n' % ', '.join(repr(t) for t in token_history) | |||
| super(UnexpectedCharacters, self).__init__(message) | |||
| class UnexpectedToken(ParseError, UnexpectedInput): | |||
| def __init__(self, token, expected, considered_rules=None, state=None): | |||
| self.token = token | |||
| self.expected = expected # XXX str shouldn't necessary | |||
| self.line = getattr(token, 'line', '?') | |||
| self.column = getattr(token, 'column', '?') | |||
| self.considered_rules = considered_rules | |||
| self.state = state | |||
| self.pos_in_stream = getattr(token, 'pos_in_stream', None) | |||
| message = ("Unexpected token %r at line %s, column %s.\n" | |||
| "Expected one of: \n\t* %s\n" | |||
| % (token, self.line, self.column, '\n\t* '.join(self.expected))) | |||
| super(UnexpectedToken, self).__init__(message) | |||
| class VisitError(LarkError): | |||
| def __init__(self, tree, orig_exc): | |||
| self.tree = tree | |||
| self.orig_exc = orig_exc | |||
| message = 'Error trying to process rule "%s":\n\n%s' % (tree.data, orig_exc) | |||
| super(VisitError, self).__init__(message) | |||
| ###} | |||
+ 104
- 0
lark/grammar.py
View File
| @@ -0,0 +1,104 @@ | |||
| from .utils import Serialize | |||
| ###{standalone | |||
| class Symbol(Serialize): | |||
| is_term = NotImplemented | |||
| def __init__(self, name): | |||
| self.name = name | |||
| def __eq__(self, other): | |||
| assert isinstance(other, Symbol), other | |||
| return self.is_term == other.is_term and self.name == other.name | |||
| def __ne__(self, other): | |||
| return not (self == other) | |||
| def __hash__(self): | |||
| return hash(self.name) | |||
| def __repr__(self): | |||
| return '%s(%r)' % (type(self).__name__, self.name) | |||
| fullrepr = property(__repr__) | |||
| class Terminal(Symbol): | |||
| __serialize_fields__ = 'name', 'filter_out' | |||
| is_term = True | |||
| def __init__(self, name, filter_out=False): | |||
| self.name = name | |||
| self.filter_out = filter_out | |||
| @property | |||
| def fullrepr(self): | |||
| return '%s(%r, %r)' % (type(self).__name__, self.name, self.filter_out) | |||
| class NonTerminal(Symbol): | |||
| __serialize_fields__ = 'name', | |||
| is_term = False | |||
| class RuleOptions(Serialize): | |||
| __serialize_fields__ = 'keep_all_tokens', 'expand1', 'priority', 'empty_indices' | |||
| def __init__(self, keep_all_tokens=False, expand1=False, priority=None, empty_indices=()): | |||
| self.keep_all_tokens = keep_all_tokens | |||
| self.expand1 = expand1 | |||
| self.priority = priority | |||
| self.empty_indices = empty_indices | |||
| def __repr__(self): | |||
| return 'RuleOptions(%r, %r, %r)' % ( | |||
| self.keep_all_tokens, | |||
| self.expand1, | |||
| self.priority, | |||
| ) | |||
| class Rule(Serialize): | |||
| """ | |||
| origin : a symbol | |||
| expansion : a list of symbols | |||
| order : index of this expansion amongst all rules of the same name | |||
| """ | |||
| __slots__ = ('origin', 'expansion', 'alias', 'options', 'order', '_hash') | |||
| __serialize_fields__ = 'origin', 'expansion', 'order', 'alias', 'options' | |||
| __serialize_namespace__ = Terminal, NonTerminal, RuleOptions | |||
| def __init__(self, origin, expansion, order=0, alias=None, options=None): | |||
| self.origin = origin | |||
| self.expansion = expansion | |||
| self.alias = alias | |||
| self.order = order | |||
| self.options = options | |||
| self._hash = hash((self.origin, tuple(self.expansion))) | |||
| def _deserialize(self): | |||
| self._hash = hash((self.origin, tuple(self.expansion))) | |||
| def __str__(self): | |||
| return '<%s : %s>' % (self.origin.name, ' '.join(x.name for x in self.expansion)) | |||
| def __repr__(self): | |||
| return 'Rule(%r, %r, %r, %r)' % (self.origin, self.expansion, self.alias, self.options) | |||
| def __hash__(self): | |||
| return self._hash | |||
| def __eq__(self, other): | |||
| if not isinstance(other, Rule): | |||
| return False | |||
| return self.origin == other.origin and self.expansion == other.expansion | |||
| ###} | |||
+ 50
- 0
lark/grammars/common.lark
View File
| @@ -0,0 +1,50 @@ | |||
| // | |||
| // Numbers | |||
| // | |||
| DIGIT: "0".."9" | |||
| HEXDIGIT: "a".."f"|"A".."F"|DIGIT | |||
| INT: DIGIT+ | |||
| SIGNED_INT: ["+"|"-"] INT | |||
| DECIMAL: INT "." INT? | "." INT | |||
| // float = /-?\d+(\.\d+)?([eE][+-]?\d+)?/ | |||
| _EXP: ("e"|"E") SIGNED_INT | |||
| FLOAT: INT _EXP | DECIMAL _EXP? | |||
| SIGNED_FLOAT: ["+"|"-"] FLOAT | |||
| NUMBER: FLOAT | INT | |||
| SIGNED_NUMBER: ["+"|"-"] NUMBER | |||
| // | |||
| // Strings | |||
| // | |||
| _STRING_INNER: /.*?/ | |||
| _STRING_ESC_INNER: _STRING_INNER /(?<!\\)(\\\\)*?/ | |||
| ESCAPED_STRING : "\"" _STRING_ESC_INNER "\"" | |||
| // | |||
| // Names (Variables) | |||
| // | |||
| LCASE_LETTER: "a".."z" | |||
| UCASE_LETTER: "A".."Z" | |||
| LETTER: UCASE_LETTER | LCASE_LETTER | |||
| WORD: LETTER+ | |||
| CNAME: ("_"|LETTER) ("_"|LETTER|DIGIT)* | |||
| // | |||
| // Whitespace | |||
| // | |||
| WS_INLINE: (" "|/\t/)+ | |||
| WS: /[ \t\f\r\n]/+ | |||
| CR : /\r/ | |||
| LF : /\n/ | |||
| NEWLINE: (CR? LF)+ | |||
+ 61
- 0
lark/indenter.py
View File
| @@ -0,0 +1,61 @@ | |||
| "Provides Indentation services for languages with indentation similar to Python" | |||
| from .lexer import Token | |||
| ###{standalone | |||
| class Indenter: | |||
| def __init__(self): | |||
| self.paren_level = None | |||
| self.indent_level = None | |||
| assert self.tab_len > 0 | |||
| def handle_NL(self, token): | |||
| if self.paren_level > 0: | |||
| return | |||
| yield token | |||
| indent_str = token.rsplit('\n', 1)[1] # Tabs and spaces | |||
| indent = indent_str.count(' ') + indent_str.count('\t') * self.tab_len | |||
| if indent > self.indent_level[-1]: | |||
| self.indent_level.append(indent) | |||
| yield Token.new_borrow_pos(self.INDENT_type, indent_str, token) | |||
| else: | |||
| while indent < self.indent_level[-1]: | |||
| self.indent_level.pop() | |||
| yield Token.new_borrow_pos(self.DEDENT_type, indent_str, token) | |||
| assert indent == self.indent_level[-1], '%s != %s' % (indent, self.indent_level[-1]) | |||
| def _process(self, stream): | |||
| for token in stream: | |||
| if token.type == self.NL_type: | |||
| for t in self.handle_NL(token): | |||
| yield t | |||
| else: | |||
| yield token | |||
| if token.type in self.OPEN_PAREN_types: | |||
| self.paren_level += 1 | |||
| elif token.type in self.CLOSE_PAREN_types: | |||
| self.paren_level -= 1 | |||
| assert self.paren_level >= 0 | |||
| while len(self.indent_level) > 1: | |||
| self.indent_level.pop() | |||
| yield Token(self.DEDENT_type, '') | |||
| assert self.indent_level == [0], self.indent_level | |||
| def process(self, stream): | |||
| self.paren_level = 0 | |||
| self.indent_level = [0] | |||
| return self._process(stream) | |||
| # XXX Hack for ContextualLexer. Maybe there's a more elegant solution? | |||
| @property | |||
| def always_accept(self): | |||
| return (self.NL_type,) | |||
| ###} | |||
+ 308
- 0
lark/lark.py
View File
| @@ -0,0 +1,308 @@ | |||
| from __future__ import absolute_import | |||
| import os | |||
| import time | |||
| from collections import defaultdict | |||
| from io import open | |||
| from .utils import STRING_TYPE, Serialize, SerializeMemoizer | |||
| from .load_grammar import load_grammar | |||
| from .tree import Tree | |||
| from .common import LexerConf, ParserConf | |||
| from .lexer import Lexer, TraditionalLexer | |||
| from .parse_tree_builder import ParseTreeBuilder | |||
| from .parser_frontends import get_frontend | |||
| from .grammar import Rule | |||
| ###{standalone | |||
| class LarkOptions(Serialize): | |||
| """Specifies the options for Lark | |||
| """ | |||
| OPTIONS_DOC = """ | |||
| parser - Decides which parser engine to use, "earley" or "lalr". (Default: "earley") | |||
| Note: "lalr" requires a lexer | |||
| lexer - Decides whether or not to use a lexer stage | |||
| "standard": Use a standard lexer | |||
| "contextual": Stronger lexer (only works with parser="lalr") | |||
| "dynamic": Flexible and powerful (only with parser="earley") | |||
| "dynamic_complete": Same as dynamic, but tries *every* variation | |||
| of tokenizing possible. (only with parser="earley") | |||
| "auto" (default): Choose for me based on grammar and parser | |||
| ambiguity - Decides how to handle ambiguity in the parse. Only relevant if parser="earley" | |||
| "resolve": The parser will automatically choose the simplest derivation | |||
| (it chooses consistently: greedy for tokens, non-greedy for rules) | |||
| "explicit": The parser will return all derivations wrapped in "_ambig" tree nodes (i.e. a forest). | |||
| transformer - Applies the transformer to every parse tree | |||
| debug - Affects verbosity (default: False) | |||
| keep_all_tokens - Don't automagically remove "punctuation" tokens (default: False) | |||
| cache_grammar - Cache the Lark grammar (Default: False) | |||
| postlex - Lexer post-processing (Default: None) Only works with the standard and contextual lexers. | |||
| start - The start symbol, either a string, or a list of strings for multiple possible starts (Default: "start") | |||
| profile - Measure run-time usage in Lark. Read results from the profiler proprety (Default: False) | |||
| priority - How priorities should be evaluated - auto, none, normal, invert (Default: auto) | |||
| propagate_positions - Propagates [line, column, end_line, end_column] attributes into all tree branches. | |||
| lexer_callbacks - Dictionary of callbacks for the lexer. May alter tokens during lexing. Use with caution. | |||
| maybe_placeholders - Experimental feature. Instead of omitting optional rules (i.e. rule?), replace them with None | |||
| """ | |||
| if __doc__: | |||
| __doc__ += OPTIONS_DOC | |||
| _defaults = { | |||
| 'debug': False, | |||
| 'keep_all_tokens': False, | |||
| 'tree_class': None, | |||
| 'cache_grammar': False, | |||
| 'postlex': None, | |||
| 'parser': 'earley', | |||
| 'lexer': 'auto', | |||
| 'transformer': None, | |||
| 'start': 'start', | |||
| 'profile': False, | |||
| 'priority': 'auto', | |||
| 'ambiguity': 'auto', | |||
| 'propagate_positions': False, | |||
| 'lexer_callbacks': {}, | |||
| 'maybe_placeholders': False, | |||
| } | |||
| def __init__(self, options_dict): | |||
| o = dict(options_dict) | |||
| options = {} | |||
| for name, default in self._defaults.items(): | |||
| if name in o: | |||
| value = o.pop(name) | |||
| if isinstance(default, bool): | |||
| value = bool(value) | |||
| else: | |||
| value = default | |||
| options[name] = value | |||
| if isinstance(options['start'], str): | |||
| options['start'] = [options['start']] | |||
| self.__dict__['options'] = options | |||
| assert self.parser in ('earley', 'lalr', 'cyk', None) | |||
| if self.parser == 'earley' and self.transformer: | |||
| raise ValueError('Cannot specify an embedded transformer when using the Earley algorithm.' | |||
| 'Please use your transformer on the resulting parse tree, or use a different algorithm (i.e. LALR)') | |||
| if o: | |||
| raise ValueError("Unknown options: %s" % o.keys()) | |||
| def __getattr__(self, name): | |||
| return self.options[name] | |||
| def __setattr__(self, name, value): | |||
| assert name in self.options | |||
| self.options[name] = value | |||
| def serialize(self, memo): | |||
| return self.options | |||
| @classmethod | |||
| def deserialize(cls, data, memo): | |||
| return cls(data) | |||
| class Profiler: | |||
| def __init__(self): | |||
| self.total_time = defaultdict(float) | |||
| self.cur_section = '__init__' | |||
| self.last_enter_time = time.time() | |||
| def enter_section(self, name): | |||
| cur_time = time.time() | |||
| self.total_time[self.cur_section] += cur_time - self.last_enter_time | |||
| self.last_enter_time = cur_time | |||
| self.cur_section = name | |||
| def make_wrapper(self, name, f): | |||
| def wrapper(*args, **kwargs): | |||
| last_section = self.cur_section | |||
| self.enter_section(name) | |||
| try: | |||
| return f(*args, **kwargs) | |||
| finally: | |||
| self.enter_section(last_section) | |||
| return wrapper | |||
| class Lark(Serialize): | |||
| def __init__(self, grammar, **options): | |||
| """ | |||
| grammar : a string or file-object containing the grammar spec (using Lark's ebnf syntax) | |||
| options : a dictionary controlling various aspects of Lark. | |||
| """ | |||
| self.options = LarkOptions(options) | |||
| # Some, but not all file-like objects have a 'name' attribute | |||
| try: | |||
| self.source = grammar.name | |||
| except AttributeError: | |||
| self.source = '<string>' | |||
| # Drain file-like objects to get their contents | |||
| try: | |||
| read = grammar.read | |||
| except AttributeError: | |||
| pass | |||
| else: | |||
| grammar = read() | |||
| assert isinstance(grammar, STRING_TYPE) | |||
| if self.options.cache_grammar: | |||
| raise NotImplementedError("Not available yet") | |||
| assert not self.options.profile, "Feature temporarily disabled" | |||
| # self.profiler = Profiler() if self.options.profile else None | |||
| if self.options.lexer == 'auto': | |||
| if self.options.parser == 'lalr': | |||
| self.options.lexer = 'contextual' | |||
| elif self.options.parser == 'earley': | |||
| self.options.lexer = 'dynamic' | |||
| elif self.options.parser == 'cyk': | |||
| self.options.lexer = 'standard' | |||
| else: | |||
| assert False, self.options.parser | |||
| lexer = self.options.lexer | |||
| assert lexer in ('standard', 'contextual', 'dynamic', 'dynamic_complete') or issubclass(lexer, Lexer) | |||
| if self.options.ambiguity == 'auto': | |||
| if self.options.parser == 'earley': | |||
| self.options.ambiguity = 'resolve' | |||
| else: | |||
| disambig_parsers = ['earley', 'cyk'] | |||
| assert self.options.parser in disambig_parsers, ( | |||
| 'Only %s supports disambiguation right now') % ', '.join(disambig_parsers) | |||
| if self.options.priority == 'auto': | |||
| if self.options.parser in ('earley', 'cyk', ): | |||
| self.options.priority = 'normal' | |||
| elif self.options.parser in ('lalr', ): | |||
| self.options.priority = None | |||
| elif self.options.priority in ('invert', 'normal'): | |||
| assert self.options.parser in ('earley', 'cyk'), "priorities are not supported for LALR at this time" | |||
| assert self.options.priority in ('auto', None, 'normal', 'invert'), 'invalid priority option specified: {}. options are auto, none, normal, invert.'.format(self.options.priority) | |||
| assert self.options.ambiguity not in ('resolve__antiscore_sum', ), 'resolve__antiscore_sum has been replaced with the option priority="invert"' | |||
| assert self.options.ambiguity in ('resolve', 'explicit', 'auto', ) | |||
| # Parse the grammar file and compose the grammars (TODO) | |||
| self.grammar = load_grammar(grammar, self.source) | |||
| # Compile the EBNF grammar into BNF | |||
| self.terminals, self.rules, self.ignore_tokens = self.grammar.compile(self.options.start) | |||
| self._terminals_dict = {t.name:t for t in self.terminals} | |||
| # If the user asked to invert the priorities, negate them all here. | |||
| # This replaces the old 'resolve__antiscore_sum' option. | |||
| if self.options.priority == 'invert': | |||
| for rule in self.rules: | |||
| if rule.options and rule.options.priority is not None: | |||
| rule.options.priority = -rule.options.priority | |||
| # Else, if the user asked to disable priorities, strip them from the | |||
| # rules. This allows the Earley parsers to skip an extra forest walk | |||
| # for improved performance, if you don't need them (or didn't specify any). | |||
| elif self.options.priority == None: | |||
| for rule in self.rules: | |||
| if rule.options and rule.options.priority is not None: | |||
| rule.options.priority = None | |||
| self.lexer_conf = LexerConf(self.terminals, self.ignore_tokens, self.options.postlex, self.options.lexer_callbacks) | |||
| if self.options.parser: | |||
| self.parser = self._build_parser() | |||
| elif lexer: | |||
| self.lexer = self._build_lexer() | |||
| if __init__.__doc__: | |||
| __init__.__doc__ += "\nOPTIONS:" + LarkOptions.OPTIONS_DOC | |||
| __serialize_fields__ = 'parser', 'rules', 'options' | |||
| def _build_lexer(self): | |||
| return TraditionalLexer(self.lexer_conf.tokens, ignore=self.lexer_conf.ignore, user_callbacks=self.lexer_conf.callbacks) | |||
| def _prepare_callbacks(self): | |||
| self.parser_class = get_frontend(self.options.parser, self.options.lexer) | |||
| self._parse_tree_builder = ParseTreeBuilder(self.rules, self.options.tree_class or Tree, self.options.propagate_positions, self.options.keep_all_tokens, self.options.parser!='lalr' and self.options.ambiguity=='explicit', self.options.maybe_placeholders) | |||
| self._callbacks = self._parse_tree_builder.create_callback(self.options.transformer) | |||
| def _build_parser(self): | |||
| self._prepare_callbacks() | |||
| parser_conf = ParserConf(self.rules, self._callbacks, self.options.start) | |||
| return self.parser_class(self.lexer_conf, parser_conf, options=self.options) | |||
| @classmethod | |||
| def deserialize(cls, data, namespace, memo, transformer=None, postlex=None): | |||
| if memo: | |||
| memo = SerializeMemoizer.deserialize(memo, namespace, {}) | |||
| inst = cls.__new__(cls) | |||
| options = dict(data['options']) | |||
| options['transformer'] = transformer | |||
| options['postlex'] = postlex | |||
| inst.options = LarkOptions.deserialize(options, memo) | |||
| inst.rules = [Rule.deserialize(r, memo) for r in data['rules']] | |||
| inst.source = '<deserialized>' | |||
| inst._prepare_callbacks() | |||
| inst.parser = inst.parser_class.deserialize(data['parser'], memo, inst._callbacks, inst.options.postlex) | |||
| return inst | |||
| @classmethod | |||
| def open(cls, grammar_filename, rel_to=None, **options): | |||
| """Create an instance of Lark with the grammar given by its filename | |||
| If rel_to is provided, the function will find the grammar filename in relation to it. | |||
| Example: | |||
| >>> Lark.open("grammar_file.lark", rel_to=__file__, parser="lalr") | |||
| Lark(...) | |||
| """ | |||
| if rel_to: | |||
| basepath = os.path.dirname(rel_to) | |||
| grammar_filename = os.path.join(basepath, grammar_filename) | |||
| with open(grammar_filename, encoding='utf8') as f: | |||
| return cls(f, **options) | |||
| def __repr__(self): | |||
| return 'Lark(open(%r), parser=%r, lexer=%r, ...)' % (self.source, self.options.parser, self.options.lexer) | |||
| def lex(self, text): | |||
| "Only lex (and postlex) the text, without parsing it. Only relevant when lexer='standard'" | |||
| if not hasattr(self, 'lexer'): | |||
| self.lexer = self._build_lexer() | |||
| stream = self.lexer.lex(text) | |||
| if self.options.postlex: | |||
| return self.options.postlex.process(stream) | |||
| return stream | |||
| def get_terminal(self, name): | |||
| "Get information about a terminal" | |||
| return self._terminals_dict[name] | |||
| def parse(self, text, start=None): | |||
| """Parse the given text, according to the options provided. | |||
| The 'start' parameter is required if Lark was given multiple possible start symbols (using the start option). | |||
| Returns a tree, unless specified otherwise. | |||
| """ | |||
| return self.parser.parse(text, start=start) | |||
| ###} | |||
+ 375
- 0
lark/lexer.py
View File
| @@ -0,0 +1,375 @@ | |||
| ## Lexer Implementation | |||
| import re | |||
| from .utils import Str, classify, get_regexp_width, Py36, Serialize | |||
| from .exceptions import UnexpectedCharacters, LexError | |||
| ###{standalone | |||
| class Pattern(Serialize): | |||
| def __init__(self, value, flags=()): | |||
| self.value = value | |||
| self.flags = frozenset(flags) | |||
| def __repr__(self): | |||
| return repr(self.to_regexp()) | |||
| # Pattern Hashing assumes all subclasses have a different priority! | |||
| def __hash__(self): | |||
| return hash((type(self), self.value, self.flags)) | |||
| def __eq__(self, other): | |||
| return type(self) == type(other) and self.value == other.value and self.flags == other.flags | |||
| def to_regexp(self): | |||
| raise NotImplementedError() | |||
| if Py36: | |||
| # Python 3.6 changed syntax for flags in regular expression | |||
| def _get_flags(self, value): | |||
| for f in self.flags: | |||
| value = ('(?%s:%s)' % (f, value)) | |||
| return value | |||
| else: | |||
| def _get_flags(self, value): | |||
| for f in self.flags: | |||
| value = ('(?%s)' % f) + value | |||
| return value | |||
| class PatternStr(Pattern): | |||
| __serialize_fields__ = 'value', 'flags' | |||
| type = "str" | |||
| def to_regexp(self): | |||
| return self._get_flags(re.escape(self.value)) | |||
| @property | |||
| def min_width(self): | |||
| return len(self.value) | |||
| max_width = min_width | |||
| class PatternRE(Pattern): | |||
| __serialize_fields__ = 'value', 'flags', '_width' | |||
| type = "re" | |||
| def to_regexp(self): | |||
| return self._get_flags(self.value) | |||
| _width = None | |||
| def _get_width(self): | |||
| if self._width is None: | |||
| self._width = get_regexp_width(self.to_regexp()) | |||
| return self._width | |||
| @property | |||
| def min_width(self): | |||
| return self._get_width()[0] | |||
| @property | |||
| def max_width(self): | |||
| return self._get_width()[1] | |||
| class TerminalDef(Serialize): | |||
| __serialize_fields__ = 'name', 'pattern', 'priority' | |||
| __serialize_namespace__ = PatternStr, PatternRE | |||
| def __init__(self, name, pattern, priority=1): | |||
| assert isinstance(pattern, Pattern), pattern | |||
| self.name = name | |||
| self.pattern = pattern | |||
| self.priority = priority | |||
| def __repr__(self): | |||
| return '%s(%r, %r)' % (type(self).__name__, self.name, self.pattern) | |||
| class Token(Str): | |||
| __slots__ = ('type', 'pos_in_stream', 'value', 'line', 'column', 'end_line', 'end_column') | |||
| def __new__(cls, type_, value, pos_in_stream=None, line=None, column=None, end_line=None, end_column=None): | |||
| try: | |||
| self = super(Token, cls).__new__(cls, value) | |||
| except UnicodeDecodeError: | |||
| value = value.decode('latin1') | |||
| self = super(Token, cls).__new__(cls, value) | |||
| self.type = type_ | |||
| self.pos_in_stream = pos_in_stream | |||
| self.value = value | |||
| self.line = line | |||
| self.column = column | |||
| self.end_line = end_line | |||
| self.end_column = end_column | |||
| return self | |||
| @classmethod | |||
| def new_borrow_pos(cls, type_, value, borrow_t): | |||
| return cls(type_, value, borrow_t.pos_in_stream, borrow_t.line, borrow_t.column, borrow_t.end_line, borrow_t.end_column) | |||
| def __reduce__(self): | |||
| return (self.__class__, (self.type, self.value, self.pos_in_stream, self.line, self.column, )) | |||
| def __repr__(self): | |||
| return 'Token(%s, %r)' % (self.type, self.value) | |||
| def __deepcopy__(self, memo): | |||
| return Token(self.type, self.value, self.pos_in_stream, self.line, self.column) | |||
| def __eq__(self, other): | |||
| if isinstance(other, Token) and self.type != other.type: | |||
| return False | |||
| return Str.__eq__(self, other) | |||
| __hash__ = Str.__hash__ | |||
| class LineCounter: | |||
| def __init__(self): | |||
| self.newline_char = '\n' | |||
| self.char_pos = 0 | |||
| self.line = 1 | |||
| self.column = 1 | |||
| self.line_start_pos = 0 | |||
| def feed(self, token, test_newline=True): | |||
| """Consume a token and calculate the new line & column. | |||
| As an optional optimization, set test_newline=False is token doesn't contain a newline. | |||
| """ | |||
| if test_newline: | |||
| newlines = token.count(self.newline_char) | |||
| if newlines: | |||
| self.line += newlines | |||
| self.line_start_pos = self.char_pos + token.rindex(self.newline_char) + 1 | |||
| self.char_pos += len(token) | |||
| self.column = self.char_pos - self.line_start_pos + 1 | |||
| class _Lex: | |||
| "Built to serve both Lexer and ContextualLexer" | |||
| def __init__(self, lexer, state=None): | |||
| self.lexer = lexer | |||
| self.state = state | |||
| def lex(self, stream, newline_types, ignore_types): | |||
| newline_types = frozenset(newline_types) | |||
| ignore_types = frozenset(ignore_types) | |||
| line_ctr = LineCounter() | |||
| last_token = None | |||
| while line_ctr.char_pos < len(stream): | |||
| lexer = self.lexer | |||
| for mre, type_from_index in lexer.mres: | |||
| m = mre.match(stream, line_ctr.char_pos) | |||
| if not m: | |||
| continue | |||
| t = None | |||
| value = m.group(0) | |||
| type_ = type_from_index[m.lastindex] | |||
| if type_ not in ignore_types: | |||
| t = Token(type_, value, line_ctr.char_pos, line_ctr.line, line_ctr.column) | |||
| if t.type in lexer.callback: | |||
| t = lexer.callback[t.type](t) | |||
| if not isinstance(t, Token): | |||
| raise ValueError("Callbacks must return a token (returned %r)" % t) | |||
| last_token = t | |||
| yield t | |||
| else: | |||
| if type_ in lexer.callback: | |||
| t = Token(type_, value, line_ctr.char_pos, line_ctr.line, line_ctr.column) | |||
| lexer.callback[type_](t) | |||
| line_ctr.feed(value, type_ in newline_types) | |||
| if t: | |||
| t.end_line = line_ctr.line | |||
| t.end_column = line_ctr.column | |||
| break | |||
| else: | |||
| allowed = {v for m, tfi in lexer.mres for v in tfi.values()} | |||
| raise UnexpectedCharacters(stream, line_ctr.char_pos, line_ctr.line, line_ctr.column, allowed=allowed, state=self.state, token_history=last_token and [last_token]) | |||
| class UnlessCallback: | |||
| def __init__(self, mres): | |||
| self.mres = mres | |||
| def __call__(self, t): | |||
| for mre, type_from_index in self.mres: | |||
| m = mre.match(t.value) | |||
| if m: | |||
| t.type = type_from_index[m.lastindex] | |||
| break | |||
| return t | |||
| class CallChain: | |||
| def __init__(self, callback1, callback2, cond): | |||
| self.callback1 = callback1 | |||
| self.callback2 = callback2 | |||
| self.cond = cond | |||
| def __call__(self, t): | |||
| t2 = self.callback1(t) | |||
| return self.callback2(t) if self.cond(t2) else t2 | |||
| def _create_unless(terminals): | |||
| tokens_by_type = classify(terminals, lambda t: type(t.pattern)) | |||
| assert len(tokens_by_type) <= 2, tokens_by_type.keys() | |||
| embedded_strs = set() | |||
| callback = {} | |||
| for retok in tokens_by_type.get(PatternRE, []): | |||
| unless = [] # {} | |||
| for strtok in tokens_by_type.get(PatternStr, []): | |||
| if strtok.priority > retok.priority: | |||
| continue | |||
| s = strtok.pattern.value | |||
| m = re.match(retok.pattern.to_regexp(), s) | |||
| if m and m.group(0) == s: | |||
| unless.append(strtok) | |||
| if strtok.pattern.flags <= retok.pattern.flags: | |||
| embedded_strs.add(strtok) | |||
| if unless: | |||
| callback[retok.name] = UnlessCallback(build_mres(unless, match_whole=True)) | |||
| terminals = [t for t in terminals if t not in embedded_strs] | |||
| return terminals, callback | |||
| def _build_mres(terminals, max_size, match_whole): | |||
| # Python sets an unreasonable group limit (currently 100) in its re module | |||
| # Worse, the only way to know we reached it is by catching an AssertionError! | |||
| # This function recursively tries less and less groups until it's successful. | |||
| postfix = '$' if match_whole else '' | |||
| mres = [] | |||
| while terminals: | |||
| try: | |||
| mre = re.compile(u'|'.join(u'(?P<%s>%s)'%(t.name, t.pattern.to_regexp()+postfix) for t in terminals[:max_size])) | |||
| except AssertionError: # Yes, this is what Python provides us.. :/ | |||
| return _build_mres(terminals, max_size//2, match_whole) | |||
| # terms_from_name = {t.name: t for t in terminals[:max_size]} | |||
| mres.append((mre, {i:n for n,i in mre.groupindex.items()} )) | |||
| terminals = terminals[max_size:] | |||
| return mres | |||
| def build_mres(terminals, match_whole=False): | |||
| return _build_mres(terminals, len(terminals), match_whole) | |||
| def _regexp_has_newline(r): | |||
| """Expressions that may indicate newlines in a regexp: | |||
| - newlines (\n) | |||
| - escaped newline (\\n) | |||
| - anything but ([^...]) | |||
| - any-char (.) when the flag (?s) exists | |||
| - spaces (\s) | |||
| """ | |||
| return '\n' in r or '\\n' in r or '\\s' in r or '[^' in r or ('(?s' in r and '.' in r) | |||
| class Lexer(object): | |||
| """Lexer interface | |||
| Method Signatures: | |||
| lex(self, stream) -> Iterator[Token] | |||
| set_parser_state(self, state) # Optional | |||
| """ | |||
| set_parser_state = NotImplemented | |||
| lex = NotImplemented | |||
| class TraditionalLexer(Lexer): | |||
| def __init__(self, terminals, ignore=(), user_callbacks={}): | |||
| assert all(isinstance(t, TerminalDef) for t in terminals), terminals | |||
| terminals = list(terminals) | |||
| # Sanitization | |||
| for t in terminals: | |||
| try: | |||
| re.compile(t.pattern.to_regexp()) | |||
| except: | |||
| raise LexError("Cannot compile token %s: %s" % (t.name, t.pattern)) | |||
| if t.pattern.min_width == 0: | |||
| raise LexError("Lexer does not allow zero-width terminals. (%s: %s)" % (t.name, t.pattern)) | |||
| assert set(ignore) <= {t.name for t in terminals} | |||
| # Init | |||
| self.newline_types = [t.name for t in terminals if _regexp_has_newline(t.pattern.to_regexp())] | |||
| self.ignore_types = list(ignore) | |||
| terminals.sort(key=lambda x:(-x.priority, -x.pattern.max_width, -len(x.pattern.value), x.name)) | |||
| self.terminals = terminals | |||
| self.user_callbacks = user_callbacks | |||
| self.build() | |||
| def build(self): | |||
| terminals, self.callback = _create_unless(self.terminals) | |||
| assert all(self.callback.values()) | |||
| for type_, f in self.user_callbacks.items(): | |||
| if type_ in self.callback: | |||
| # Already a callback there, probably UnlessCallback | |||
| self.callback[type_] = CallChain(self.callback[type_], f, lambda t: t.type == type_) | |||
| else: | |||
| self.callback[type_] = f | |||
| self.mres = build_mres(terminals) | |||
| def lex(self, stream): | |||
| return _Lex(self).lex(stream, self.newline_types, self.ignore_types) | |||
| class ContextualLexer(Lexer): | |||
| def __init__(self, terminals, states, ignore=(), always_accept=(), user_callbacks={}): | |||
| tokens_by_name = {} | |||
| for t in terminals: | |||
| assert t.name not in tokens_by_name, t | |||
| tokens_by_name[t.name] = t | |||
| lexer_by_tokens = {} | |||
| self.lexers = {} | |||
| for state, accepts in states.items(): | |||
| key = frozenset(accepts) | |||
| try: | |||
| lexer = lexer_by_tokens[key] | |||
| except KeyError: | |||
| accepts = set(accepts) | set(ignore) | set(always_accept) | |||
| state_tokens = [tokens_by_name[n] for n in accepts if n and n in tokens_by_name] | |||
| lexer = TraditionalLexer(state_tokens, ignore=ignore, user_callbacks=user_callbacks) | |||
| lexer_by_tokens[key] = lexer | |||
| self.lexers[state] = lexer | |||
| self.root_lexer = TraditionalLexer(terminals, ignore=ignore, user_callbacks=user_callbacks) | |||
| self.set_parser_state(None) # Needs to be set on the outside | |||
| def set_parser_state(self, state): | |||
| self.parser_state = state | |||
| def lex(self, stream): | |||
| l = _Lex(self.lexers[self.parser_state], self.parser_state) | |||
| for x in l.lex(stream, self.root_lexer.newline_types, self.root_lexer.ignore_types): | |||
| yield x | |||
| l.lexer = self.lexers[self.parser_state] | |||
| l.state = self.parser_state | |||
| ###} | |||
+ 860
- 0
lark/load_grammar.py
View File
| @@ -0,0 +1,860 @@ | |||
| "Parses and creates Grammar objects" | |||
| import os.path | |||
| import sys | |||
| from ast import literal_eval | |||
| from copy import copy, deepcopy | |||
| from .utils import bfs | |||
| from .lexer import Token, TerminalDef, PatternStr, PatternRE | |||
| from .parse_tree_builder import ParseTreeBuilder | |||
| from .parser_frontends import LALR_TraditionalLexer | |||
| from .common import LexerConf, ParserConf | |||
| from .grammar import RuleOptions, Rule, Terminal, NonTerminal, Symbol | |||
| from .utils import classify, suppress, dedup_list, Str | |||
| from .exceptions import GrammarError, UnexpectedCharacters, UnexpectedToken | |||
| from .tree import Tree, SlottedTree as ST | |||
| from .visitors import Transformer, Visitor, v_args, Transformer_InPlace | |||
| inline_args = v_args(inline=True) | |||
| __path__ = os.path.dirname(__file__) | |||
| IMPORT_PATHS = [os.path.join(__path__, 'grammars')] | |||
| EXT = '.lark' | |||
| _RE_FLAGS = 'imslux' | |||
| _EMPTY = Symbol('__empty__') | |||
| _TERMINAL_NAMES = { | |||
| '.' : 'DOT', | |||
| ',' : 'COMMA', | |||
| ':' : 'COLON', | |||
| ';' : 'SEMICOLON', | |||
| '+' : 'PLUS', | |||
| '-' : 'MINUS', | |||
| '*' : 'STAR', | |||
| '/' : 'SLASH', | |||
| '\\' : 'BACKSLASH', | |||
| '|' : 'VBAR', | |||
| '?' : 'QMARK', | |||
| '!' : 'BANG', | |||
| '@' : 'AT', | |||
| '#' : 'HASH', | |||
| '$' : 'DOLLAR', | |||
| '%' : 'PERCENT', | |||
| '^' : 'CIRCUMFLEX', | |||
| '&' : 'AMPERSAND', | |||
| '_' : 'UNDERSCORE', | |||
| '<' : 'LESSTHAN', | |||
| '>' : 'MORETHAN', | |||
| '=' : 'EQUAL', | |||
| '"' : 'DBLQUOTE', | |||
| '\'' : 'QUOTE', | |||
| '`' : 'BACKQUOTE', | |||
| '~' : 'TILDE', | |||
| '(' : 'LPAR', | |||
| ')' : 'RPAR', | |||
| '{' : 'LBRACE', | |||
| '}' : 'RBRACE', | |||
| '[' : 'LSQB', | |||
| ']' : 'RSQB', | |||
| '\n' : 'NEWLINE', | |||
| '\r\n' : 'CRLF', | |||
| '\t' : 'TAB', | |||
| ' ' : 'SPACE', | |||
| } | |||
| # Grammar Parser | |||
| TERMINALS = { | |||
| '_LPAR': r'\(', | |||
| '_RPAR': r'\)', | |||
| '_LBRA': r'\[', | |||
| '_RBRA': r'\]', | |||
| 'OP': '[+*][?]?|[?](?![a-z])', | |||
| '_COLON': ':', | |||
| '_COMMA': ',', | |||
| '_OR': r'\|', | |||
| '_DOT': r'\.', | |||
| 'TILDE': '~', | |||
| 'RULE': '!?[_?]?[a-z][_a-z0-9]*', | |||
| 'TERMINAL': '_?[A-Z][_A-Z0-9]*', | |||
| 'STRING': r'"(\\"|\\\\|[^"\n])*?"i?', | |||
| 'REGEXP': r'/(?!/)(\\/|\\\\|[^/\n])*?/[%s]*' % _RE_FLAGS, | |||
| '_NL': r'(\r?\n)+\s*', | |||
| 'WS': r'[ \t]+', | |||
| 'COMMENT': r'//[^\n]*', | |||
| '_TO': '->', | |||
| '_IGNORE': r'%ignore', | |||
| '_DECLARE': r'%declare', | |||
| '_IMPORT': r'%import', | |||
| 'NUMBER': r'[+-]?\d+', | |||
| } | |||
| RULES = { | |||
| 'start': ['_list'], | |||
| '_list': ['_item', '_list _item'], | |||
| '_item': ['rule', 'term', 'statement', '_NL'], | |||
| 'rule': ['RULE _COLON expansions _NL', | |||
| 'RULE _DOT NUMBER _COLON expansions _NL'], | |||
| 'expansions': ['alias', | |||
| 'expansions _OR alias', | |||
| 'expansions _NL _OR alias'], | |||
| '?alias': ['expansion _TO RULE', 'expansion'], | |||
| 'expansion': ['_expansion'], | |||
| '_expansion': ['', '_expansion expr'], | |||
| '?expr': ['atom', | |||
| 'atom OP', | |||
| 'atom TILDE NUMBER', | |||
| 'atom TILDE NUMBER _DOT _DOT NUMBER', | |||
| ], | |||
| '?atom': ['_LPAR expansions _RPAR', | |||
| 'maybe', | |||
| 'value'], | |||
| 'value': ['terminal', | |||
| 'nonterminal', | |||
| 'literal', | |||
| 'range'], | |||
| 'terminal': ['TERMINAL'], | |||
| 'nonterminal': ['RULE'], | |||
| '?name': ['RULE', 'TERMINAL'], | |||
| 'maybe': ['_LBRA expansions _RBRA'], | |||
| 'range': ['STRING _DOT _DOT STRING'], | |||
| 'term': ['TERMINAL _COLON expansions _NL', | |||
| 'TERMINAL _DOT NUMBER _COLON expansions _NL'], | |||
| 'statement': ['ignore', 'import', 'declare'], | |||
| 'ignore': ['_IGNORE expansions _NL'], | |||
| 'declare': ['_DECLARE _declare_args _NL'], | |||
| 'import': ['_IMPORT _import_path _NL', | |||
| '_IMPORT _import_path _LPAR name_list _RPAR _NL', | |||
| '_IMPORT _import_path _TO name _NL'], | |||
| '_import_path': ['import_lib', 'import_rel'], | |||
| 'import_lib': ['_import_args'], | |||
| 'import_rel': ['_DOT _import_args'], | |||
| '_import_args': ['name', '_import_args _DOT name'], | |||
| 'name_list': ['_name_list'], | |||
| '_name_list': ['name', '_name_list _COMMA name'], | |||
| '_declare_args': ['name', '_declare_args name'], | |||
| 'literal': ['REGEXP', 'STRING'], | |||
| } | |||
| @inline_args | |||
| class EBNF_to_BNF(Transformer_InPlace): | |||
| def __init__(self): | |||
| self.new_rules = [] | |||
| self.rules_by_expr = {} | |||
| self.prefix = 'anon' | |||
| self.i = 0 | |||
| self.rule_options = None | |||
| def _add_recurse_rule(self, type_, expr): | |||
| if expr in self.rules_by_expr: | |||
| return self.rules_by_expr[expr] | |||
| new_name = '__%s_%s_%d' % (self.prefix, type_, self.i) | |||
| self.i += 1 | |||
| t = NonTerminal(new_name) | |||
| tree = ST('expansions', [ST('expansion', [expr]), ST('expansion', [t, expr])]) | |||
| self.new_rules.append((new_name, tree, self.rule_options)) | |||
| self.rules_by_expr[expr] = t | |||
| return t | |||
| def expr(self, rule, op, *args): | |||
| if op.value == '?': | |||
| empty = ST('expansion', []) | |||
| return ST('expansions', [rule, empty]) | |||
| elif op.value == '+': | |||
| # a : b c+ d | |||
| # --> | |||
| # a : b _c d | |||
| # _c : _c c | c; | |||
| return self._add_recurse_rule('plus', rule) | |||
| elif op.value == '*': | |||
| # a : b c* d | |||
| # --> | |||
| # a : b _c? d | |||
| # _c : _c c | c; | |||
| new_name = self._add_recurse_rule('star', rule) | |||
| return ST('expansions', [new_name, ST('expansion', [])]) | |||
| elif op.value == '~': | |||
| if len(args) == 1: | |||
| mn = mx = int(args[0]) | |||
| else: | |||
| mn, mx = map(int, args) | |||
| if mx < mn or mn < 0: | |||
| raise GrammarError("Bad Range for %s (%d..%d isn't allowed)" % (rule, mn, mx)) | |||
| return ST('expansions', [ST('expansion', [rule] * n) for n in range(mn, mx+1)]) | |||
| assert False, op | |||
| def maybe(self, rule): | |||
| keep_all_tokens = self.rule_options and self.rule_options.keep_all_tokens | |||
| def will_not_get_removed(sym): | |||
| if isinstance(sym, NonTerminal): | |||
| return not sym.name.startswith('_') | |||
| if isinstance(sym, Terminal): | |||
| return keep_all_tokens or not sym.filter_out | |||
| assert False | |||
| if any(rule.scan_values(will_not_get_removed)): | |||
| empty = _EMPTY | |||
| else: | |||
| empty = ST('expansion', []) | |||
| return ST('expansions', [rule, empty]) | |||
| class SimplifyRule_Visitor(Visitor): | |||
| @staticmethod | |||
| def _flatten(tree): | |||
| while True: | |||
| to_expand = [i for i, child in enumerate(tree.children) | |||
| if isinstance(child, Tree) and child.data == tree.data] | |||
| if not to_expand: | |||
| break | |||
| tree.expand_kids_by_index(*to_expand) | |||
| def expansion(self, tree): | |||
| # rules_list unpacking | |||
| # a : b (c|d) e | |||
| # --> | |||
| # a : b c e | b d e | |||
| # | |||
| # In AST terms: | |||
| # expansion(b, expansions(c, d), e) | |||
| # --> | |||
| # expansions( expansion(b, c, e), expansion(b, d, e) ) | |||
| self._flatten(tree) | |||
| for i, child in enumerate(tree.children): | |||
| if isinstance(child, Tree) and child.data == 'expansions': | |||
| tree.data = 'expansions' | |||
| tree.children = [self.visit(ST('expansion', [option if i==j else other | |||
| for j, other in enumerate(tree.children)])) | |||
| for option in dedup_list(child.children)] | |||
| self._flatten(tree) | |||
| break | |||
| def alias(self, tree): | |||
| rule, alias_name = tree.children | |||
| if rule.data == 'expansions': | |||
| aliases = [] | |||
| for child in tree.children[0].children: | |||
| aliases.append(ST('alias', [child, alias_name])) | |||
| tree.data = 'expansions' | |||
| tree.children = aliases | |||
| def expansions(self, tree): | |||
| self._flatten(tree) | |||
| tree.children = dedup_list(tree.children) | |||
| class RuleTreeToText(Transformer): | |||
| def expansions(self, x): | |||
| return x | |||
| def expansion(self, symbols): | |||
| return symbols, None | |||
| def alias(self, x): | |||
| (expansion, _alias), alias = x | |||
| assert _alias is None, (alias, expansion, '-', _alias) # Double alias not allowed | |||
| return expansion, alias.value | |||
| @inline_args | |||
| class CanonizeTree(Transformer_InPlace): | |||
| def tokenmods(self, *args): | |||
| if len(args) == 1: | |||
| return list(args) | |||
| tokenmods, value = args | |||
| return tokenmods + [value] | |||
| class PrepareAnonTerminals(Transformer_InPlace): | |||
| "Create a unique list of anonymous terminals. Attempt to give meaningful names to them when we add them" | |||
| def __init__(self, terminals): | |||
| self.terminals = terminals | |||
| self.term_set = {td.name for td in self.terminals} | |||
| self.term_reverse = {td.pattern: td for td in terminals} | |||
| self.i = 0 | |||
| @inline_args | |||
| def pattern(self, p): | |||
| value = p.value | |||
| if p in self.term_reverse and p.flags != self.term_reverse[p].pattern.flags: | |||
| raise GrammarError(u'Conflicting flags for the same terminal: %s' % p) | |||
| term_name = None | |||
| if isinstance(p, PatternStr): | |||
| try: | |||
| # If already defined, use the user-defined terminal name | |||
| term_name = self.term_reverse[p].name | |||
| except KeyError: | |||
| # Try to assign an indicative anon-terminal name | |||
| try: | |||
| term_name = _TERMINAL_NAMES[value] | |||
| except KeyError: | |||
| if value.isalnum() and value[0].isalpha() and value.upper() not in self.term_set: | |||
| with suppress(UnicodeEncodeError): | |||
| value.upper().encode('ascii') # Make sure we don't have unicode in our terminal names | |||
| term_name = value.upper() | |||
| if term_name in self.term_set: | |||
| term_name = None | |||
| elif isinstance(p, PatternRE): | |||
| if p in self.term_reverse: # Kind of a wierd placement.name | |||
| term_name = self.term_reverse[p].name | |||
| else: | |||
| assert False, p | |||
| if term_name is None: | |||
| term_name = '__ANON_%d' % self.i | |||
| self.i += 1 | |||
| if term_name not in self.term_set: | |||
| assert p not in self.term_reverse | |||
| self.term_set.add(term_name) | |||
| termdef = TerminalDef(term_name, p) | |||
| self.term_reverse[p] = termdef | |||
| self.terminals.append(termdef) | |||
| return Terminal(term_name, filter_out=isinstance(p, PatternStr)) | |||
| def _rfind(s, choices): | |||
| return max(s.rfind(c) for c in choices) | |||
| def _fix_escaping(s): | |||
| w = '' | |||
| i = iter(s) | |||
| for n in i: | |||
| w += n | |||
| if n == '\\': | |||
| n2 = next(i) | |||
| if n2 == '\\': | |||
| w += '\\\\' | |||
| elif n2 not in 'uxnftr': | |||
| w += '\\' | |||
| w += n2 | |||
| w = w.replace('\\"', '"').replace("'", "\\'") | |||
| to_eval = "u'''%s'''" % w | |||
| try: | |||
| s = literal_eval(to_eval) | |||
| except SyntaxError as e: | |||
| raise ValueError(s, e) | |||
| return s | |||
| def _literal_to_pattern(literal): | |||
| v = literal.value | |||
| flag_start = _rfind(v, '/"')+1 | |||
| assert flag_start > 0 | |||
| flags = v[flag_start:] | |||
| assert all(f in _RE_FLAGS for f in flags), flags | |||
| v = v[:flag_start] | |||
| assert v[0] == v[-1] and v[0] in '"/' | |||
| x = v[1:-1] | |||
| s = _fix_escaping(x) | |||
| if literal.type == 'STRING': | |||
| s = s.replace('\\\\', '\\') | |||
| return { 'STRING': PatternStr, | |||
| 'REGEXP': PatternRE }[literal.type](s, flags) | |||
| @inline_args | |||
| class PrepareLiterals(Transformer_InPlace): | |||
| def literal(self, literal): | |||
| return ST('pattern', [_literal_to_pattern(literal)]) | |||
| def range(self, start, end): | |||
| assert start.type == end.type == 'STRING' | |||
| start = start.value[1:-1] | |||
| end = end.value[1:-1] | |||
| assert len(_fix_escaping(start)) == len(_fix_escaping(end)) == 1, (start, end, len(_fix_escaping(start)), len(_fix_escaping(end))) | |||
| regexp = '[%s-%s]' % (start, end) | |||
| return ST('pattern', [PatternRE(regexp)]) | |||
| class TerminalTreeToPattern(Transformer): | |||
| def pattern(self, ps): | |||
| p ,= ps | |||
| return p | |||
| def expansion(self, items): | |||
| assert items | |||
| if len(items) == 1: | |||
| return items[0] | |||
| if len({i.flags for i in items}) > 1: | |||
| raise GrammarError("Lark doesn't support joining terminals with conflicting flags!") | |||
| return PatternRE(''.join(i.to_regexp() for i in items), items[0].flags if items else ()) | |||
| def expansions(self, exps): | |||
| if len(exps) == 1: | |||
| return exps[0] | |||
| if len({i.flags for i in exps}) > 1: | |||
| raise GrammarError("Lark doesn't support joining terminals with conflicting flags!") | |||
| return PatternRE('(?:%s)' % ('|'.join(i.to_regexp() for i in exps)), exps[0].flags) | |||
| def expr(self, args): | |||
| inner, op = args[:2] | |||
| if op == '~': | |||
| if len(args) == 3: | |||
| op = "{%d}" % int(args[2]) | |||
| else: | |||
| mn, mx = map(int, args[2:]) | |||
| if mx < mn: | |||
| raise GrammarError("Bad Range for %s (%d..%d isn't allowed)" % (inner, mn, mx)) | |||
| op = "{%d,%d}" % (mn, mx) | |||
| else: | |||
| assert len(args) == 2 | |||
| return PatternRE('(?:%s)%s' % (inner.to_regexp(), op), inner.flags) | |||
| def maybe(self, expr): | |||
| return self.expr(expr + ['?']) | |||
| def alias(self, t): | |||
| raise GrammarError("Aliasing not allowed in terminals (You used -> in the wrong place)") | |||
| def value(self, v): | |||
| return v[0] | |||
| class PrepareSymbols(Transformer_InPlace): | |||
| def value(self, v): | |||
| v ,= v | |||
| if isinstance(v, Tree): | |||
| return v | |||
| elif v.type == 'RULE': | |||
| return NonTerminal(Str(v.value)) | |||
| elif v.type == 'TERMINAL': | |||
| return Terminal(Str(v.value), filter_out=v.startswith('_')) | |||
| assert False | |||
| def _choice_of_rules(rules): | |||
| return ST('expansions', [ST('expansion', [Token('RULE', name)]) for name in rules]) | |||
| class Grammar: | |||
| def __init__(self, rule_defs, term_defs, ignore): | |||
| self.term_defs = term_defs | |||
| self.rule_defs = rule_defs | |||
| self.ignore = ignore | |||
| def compile(self, start): | |||
| # We change the trees in-place (to support huge grammars) | |||
| # So deepcopy allows calling compile more than once. | |||
| term_defs = deepcopy(list(self.term_defs)) | |||
| rule_defs = deepcopy(self.rule_defs) | |||
| # =================== | |||
| # Compile Terminals | |||
| # =================== | |||
| # Convert terminal-trees to strings/regexps | |||
| transformer = PrepareLiterals() * TerminalTreeToPattern() | |||
| for name, (term_tree, priority) in term_defs: | |||
| if term_tree is None: # Terminal added through %declare | |||
| continue | |||
| expansions = list(term_tree.find_data('expansion')) | |||
| if len(expansions) == 1 and not expansions[0].children: | |||
| raise GrammarError("Terminals cannot be empty (%s)" % name) | |||
| terminals = [TerminalDef(name, transformer.transform(term_tree), priority) | |||
| for name, (term_tree, priority) in term_defs if term_tree] | |||
| # ================= | |||
| # Compile Rules | |||
| # ================= | |||
| # 1. Pre-process terminals | |||
| transformer = PrepareLiterals() * PrepareSymbols() * PrepareAnonTerminals(terminals) # Adds to terminals | |||
| # 2. Convert EBNF to BNF (and apply step 1) | |||
| ebnf_to_bnf = EBNF_to_BNF() | |||
| rules = [] | |||
| for name, rule_tree, options in rule_defs: | |||
| ebnf_to_bnf.rule_options = RuleOptions(keep_all_tokens=True) if options and options.keep_all_tokens else None | |||
| tree = transformer.transform(rule_tree) | |||
| res = ebnf_to_bnf.transform(tree) | |||
| rules.append((name, res, options)) | |||
| rules += ebnf_to_bnf.new_rules | |||
| assert len(rules) == len({name for name, _t, _o in rules}), "Whoops, name collision" | |||
| # 3. Compile tree to Rule objects | |||
| rule_tree_to_text = RuleTreeToText() | |||
| simplify_rule = SimplifyRule_Visitor() | |||
| compiled_rules = [] | |||
| for rule_content in rules: | |||
| name, tree, options = rule_content | |||
| simplify_rule.visit(tree) | |||
| expansions = rule_tree_to_text.transform(tree) | |||
| for i, (expansion, alias) in enumerate(expansions): | |||
| if alias and name.startswith('_'): | |||
| raise GrammarError("Rule %s is marked for expansion (it starts with an underscore) and isn't allowed to have aliases (alias=%s)" % (name, alias)) | |||
| empty_indices = [x==_EMPTY for x in expansion] | |||
| if any(empty_indices): | |||
| exp_options = copy(options) if options else RuleOptions() | |||
| exp_options.empty_indices = empty_indices | |||
| expansion = [x for x in expansion if x!=_EMPTY] | |||
| else: | |||
| exp_options = options | |||
| assert all(isinstance(x, Symbol) for x in expansion), expansion | |||
| rule = Rule(NonTerminal(name), expansion, i, alias, exp_options) | |||
| compiled_rules.append(rule) | |||
| # Remove duplicates of empty rules, throw error for non-empty duplicates | |||
| if len(set(compiled_rules)) != len(compiled_rules): | |||
| duplicates = classify(compiled_rules, lambda x: x) | |||
| for dups in duplicates.values(): | |||
| if len(dups) > 1: | |||
| if dups[0].expansion: | |||
| raise GrammarError("Rules defined twice: %s\n\n(Might happen due to colliding expansion of optionals: [] or ?)" % ''.join('\n * %s' % i for i in dups)) | |||
| # Empty rule; assert all other attributes are equal | |||
| assert len({(r.alias, r.order, r.options) for r in dups}) == len(dups) | |||
| # Remove duplicates | |||
| compiled_rules = list(set(compiled_rules)) | |||
| # Filter out unused rules | |||
| while True: | |||
| c = len(compiled_rules) | |||
| used_rules = {s for r in compiled_rules | |||
| for s in r.expansion | |||
| if isinstance(s, NonTerminal) | |||
| and s != r.origin} | |||
| used_rules |= {NonTerminal(s) for s in start} | |||
| compiled_rules = [r for r in compiled_rules if r.origin in used_rules] | |||
| if len(compiled_rules) == c: | |||
| break | |||
| # Filter out unused terminals | |||
| used_terms = {t.name for r in compiled_rules | |||
| for t in r.expansion | |||
| if isinstance(t, Terminal)} | |||
| terminals = [t for t in terminals if t.name in used_terms or t.name in self.ignore] | |||
| return terminals, compiled_rules, self.ignore | |||
| _imported_grammars = {} | |||
| def import_grammar(grammar_path, base_paths=[]): | |||
| if grammar_path not in _imported_grammars: | |||
| import_paths = base_paths + IMPORT_PATHS | |||
| for import_path in import_paths: | |||
| with suppress(IOError): | |||
| joined_path = os.path.join(import_path, grammar_path) | |||
| with open(joined_path) as f: | |||
| text = f.read() | |||
| grammar = load_grammar(text, joined_path) | |||
| _imported_grammars[grammar_path] = grammar | |||
| break | |||
| else: | |||
| open(grammar_path) | |||
| assert False | |||
| return _imported_grammars[grammar_path] | |||
| def import_from_grammar_into_namespace(grammar, namespace, aliases): | |||
| """Returns all rules and terminals of grammar, prepended | |||
| with a 'namespace' prefix, except for those which are aliased. | |||
| """ | |||
| imported_terms = dict(grammar.term_defs) | |||
| imported_rules = {n:(n,deepcopy(t),o) for n,t,o in grammar.rule_defs} | |||
| term_defs = [] | |||
| rule_defs = [] | |||
| def rule_dependencies(symbol): | |||
| if symbol.type != 'RULE': | |||
| return [] | |||
| try: | |||
| _, tree, _ = imported_rules[symbol] | |||
| except KeyError: | |||
| raise GrammarError("Missing symbol '%s' in grammar %s" % (symbol, namespace)) | |||
| return tree.scan_values(lambda x: x.type in ('RULE', 'TERMINAL')) | |||
| def get_namespace_name(name): | |||
| try: | |||
| return aliases[name].value | |||
| except KeyError: | |||
| if name[0] == '_': | |||
| return '_%s__%s' % (namespace, name[1:]) | |||
| return '%s__%s' % (namespace, name) | |||
| to_import = list(bfs(aliases, rule_dependencies)) | |||
| for symbol in to_import: | |||
| if symbol.type == 'TERMINAL': | |||
| term_defs.append([get_namespace_name(symbol), imported_terms[symbol]]) | |||
| else: | |||
| assert symbol.type == 'RULE' | |||
| rule = imported_rules[symbol] | |||
| for t in rule[1].iter_subtrees(): | |||
| for i, c in enumerate(t.children): | |||
| if isinstance(c, Token) and c.type in ('RULE', 'TERMINAL'): | |||
| t.children[i] = Token(c.type, get_namespace_name(c)) | |||
| rule_defs.append((get_namespace_name(symbol), rule[1], rule[2])) | |||
| return term_defs, rule_defs | |||
| def resolve_term_references(term_defs): | |||
| # TODO Cycles detection | |||
| # TODO Solve with transitive closure (maybe) | |||
| token_dict = {k:t for k, (t,_p) in term_defs} | |||
| assert len(token_dict) == len(term_defs), "Same name defined twice?" | |||
| while True: | |||
| changed = False | |||
| for name, (token_tree, _p) in term_defs: | |||
| if token_tree is None: # Terminal added through %declare | |||
| continue | |||
| for exp in token_tree.find_data('value'): | |||
| item ,= exp.children | |||
| if isinstance(item, Token): | |||
| if item.type == 'RULE': | |||
| raise GrammarError("Rules aren't allowed inside terminals (%s in %s)" % (item, name)) | |||
| if item.type == 'TERMINAL': | |||
| exp.children[0] = token_dict[item] | |||
| changed = True | |||
| if not changed: | |||
| break | |||
| def options_from_rule(name, *x): | |||
| if len(x) > 1: | |||
| priority, expansions = x | |||
| priority = int(priority) | |||
| else: | |||
| expansions ,= x | |||
| priority = None | |||
| keep_all_tokens = name.startswith('!') | |||
| name = name.lstrip('!') | |||
| expand1 = name.startswith('?') | |||
| name = name.lstrip('?') | |||
| return name, expansions, RuleOptions(keep_all_tokens, expand1, priority=priority) | |||
| def symbols_from_strcase(expansion): | |||
| return [Terminal(x, filter_out=x.startswith('_')) if x.isupper() else NonTerminal(x) for x in expansion] | |||
| @inline_args | |||
| class PrepareGrammar(Transformer_InPlace): | |||
| def terminal(self, name): | |||
| return name | |||
| def nonterminal(self, name): | |||
| return name | |||
| class GrammarLoader: | |||
| def __init__(self): | |||
| terminals = [TerminalDef(name, PatternRE(value)) for name, value in TERMINALS.items()] | |||
| rules = [options_from_rule(name, x) for name, x in RULES.items()] | |||
| rules = [Rule(NonTerminal(r), symbols_from_strcase(x.split()), i, None, o) for r, xs, o in rules for i, x in enumerate(xs)] | |||
| callback = ParseTreeBuilder(rules, ST).create_callback() | |||
| lexer_conf = LexerConf(terminals, ['WS', 'COMMENT']) | |||
| parser_conf = ParserConf(rules, callback, ['start']) | |||
| self.parser = LALR_TraditionalLexer(lexer_conf, parser_conf) | |||
| self.canonize_tree = CanonizeTree() | |||
| def load_grammar(self, grammar_text, grammar_name='<?>'): | |||
| "Parse grammar_text, verify, and create Grammar object. Display nice messages on error." | |||
| try: | |||
| tree = self.canonize_tree.transform( self.parser.parse(grammar_text+'\n') ) | |||
| except UnexpectedCharacters as e: | |||
| context = e.get_context(grammar_text) | |||
| raise GrammarError("Unexpected input at line %d column %d in %s: \n\n%s" % | |||
| (e.line, e.column, grammar_name, context)) | |||
| except UnexpectedToken as e: | |||
| context = e.get_context(grammar_text) | |||
| error = e.match_examples(self.parser.parse, { | |||
| 'Unclosed parenthesis': ['a: (\n'], | |||
| 'Umatched closing parenthesis': ['a: )\n', 'a: [)\n', 'a: (]\n'], | |||
| 'Expecting rule or terminal definition (missing colon)': ['a\n', 'a->\n', 'A->\n', 'a A\n'], | |||
| 'Alias expects lowercase name': ['a: -> "a"\n'], | |||
| 'Unexpected colon': ['a::\n', 'a: b:\n', 'a: B:\n', 'a: "a":\n'], | |||
| 'Misplaced operator': ['a: b??', 'a: b(?)', 'a:+\n', 'a:?\n', 'a:*\n', 'a:|*\n'], | |||
| 'Expecting option ("|") or a new rule or terminal definition': ['a:a\n()\n'], | |||
| '%import expects a name': ['%import "a"\n'], | |||
| '%ignore expects a value': ['%ignore %import\n'], | |||
| }) | |||
| if error: | |||
| raise GrammarError("%s at line %s column %s\n\n%s" % (error, e.line, e.column, context)) | |||
| elif 'STRING' in e.expected: | |||
| raise GrammarError("Expecting a value at line %s column %s\n\n%s" % (e.line, e.column, context)) | |||
| raise | |||
| tree = PrepareGrammar().transform(tree) | |||
| # Extract grammar items | |||
| defs = classify(tree.children, lambda c: c.data, lambda c: c.children) | |||
| term_defs = defs.pop('term', []) | |||
| rule_defs = defs.pop('rule', []) | |||
| statements = defs.pop('statement', []) | |||
| assert not defs | |||
| term_defs = [td if len(td)==3 else (td[0], 1, td[1]) for td in term_defs] | |||
| term_defs = [(name.value, (t, int(p))) for name, p, t in term_defs] | |||
| rule_defs = [options_from_rule(*x) for x in rule_defs] | |||
| # Execute statements | |||
| ignore, imports = [], {} | |||
| for (stmt,) in statements: | |||
| if stmt.data == 'ignore': | |||
| t ,= stmt.children | |||
| ignore.append(t) | |||
| elif stmt.data == 'import': | |||
| if len(stmt.children) > 1: | |||
| path_node, arg1 = stmt.children | |||
| else: | |||
| path_node, = stmt.children | |||
| arg1 = None | |||
| if isinstance(arg1, Tree): # Multi import | |||
| dotted_path = tuple(path_node.children) | |||
| names = arg1.children | |||
| aliases = dict(zip(names, names)) # Can't have aliased multi import, so all aliases will be the same as names | |||
| else: # Single import | |||
| dotted_path = tuple(path_node.children[:-1]) | |||
| name = path_node.children[-1] # Get name from dotted path | |||
| aliases = {name: arg1 or name} # Aliases if exist | |||
| if path_node.data == 'import_lib': # Import from library | |||
| base_paths = [] | |||
| else: # Relative import | |||
| if grammar_name == '<string>': # Import relative to script file path if grammar is coded in script | |||
| try: | |||
| base_file = os.path.abspath(sys.modules['__main__'].__file__) | |||
| except AttributeError: | |||
| base_file = None | |||
| else: | |||
| base_file = grammar_name # Import relative to grammar file path if external grammar file | |||
| if base_file: | |||
| base_paths = [os.path.split(base_file)[0]] | |||
| else: | |||
| base_paths = [os.path.abspath(os.path.curdir)] | |||
| try: | |||
| import_base_paths, import_aliases = imports[dotted_path] | |||
| assert base_paths == import_base_paths, 'Inconsistent base_paths for %s.' % '.'.join(dotted_path) | |||
| import_aliases.update(aliases) | |||
| except KeyError: | |||
| imports[dotted_path] = base_paths, aliases | |||
| elif stmt.data == 'declare': | |||
| for t in stmt.children: | |||
| term_defs.append([t.value, (None, None)]) | |||
| else: | |||
| assert False, stmt | |||
| # import grammars | |||
| for dotted_path, (base_paths, aliases) in imports.items(): | |||
| grammar_path = os.path.join(*dotted_path) + EXT | |||
| g = import_grammar(grammar_path, base_paths=base_paths) | |||
| new_td, new_rd = import_from_grammar_into_namespace(g, '__'.join(dotted_path), aliases) | |||
| term_defs += new_td | |||
| rule_defs += new_rd | |||
| # Verify correctness 1 | |||
| for name, _ in term_defs: | |||
| if name.startswith('__'): | |||
| raise GrammarError('Names starting with double-underscore are reserved (Error at %s)' % name) | |||
| # Handle ignore tokens | |||
| # XXX A slightly hacky solution. Recognition of %ignore TERMINAL as separate comes from the lexer's | |||
| # inability to handle duplicate terminals (two names, one value) | |||
| ignore_names = [] | |||
| for t in ignore: | |||
| if t.data=='expansions' and len(t.children) == 1: | |||
| t2 ,= t.children | |||
| if t2.data=='expansion' and len(t2.children) == 1: | |||
| item ,= t2.children | |||
| if item.data == 'value': | |||
| item ,= item.children | |||
| if isinstance(item, Token) and item.type == 'TERMINAL': | |||
| ignore_names.append(item.value) | |||
| continue | |||
| name = '__IGNORE_%d'% len(ignore_names) | |||
| ignore_names.append(name) | |||
| term_defs.append((name, (t, 1))) | |||
| # Verify correctness 2 | |||
| terminal_names = set() | |||
| for name, _ in term_defs: | |||
| if name in terminal_names: | |||
| raise GrammarError("Terminal '%s' defined more than once" % name) | |||
| terminal_names.add(name) | |||
| if set(ignore_names) > terminal_names: | |||
| raise GrammarError("Terminals %s were marked to ignore but were not defined!" % (set(ignore_names) - terminal_names)) | |||
| resolve_term_references(term_defs) | |||
| rules = rule_defs | |||
| rule_names = set() | |||
| for name, _x, _o in rules: | |||
| if name.startswith('__'): | |||
| raise GrammarError('Names starting with double-underscore are reserved (Error at %s)' % name) | |||
| if name in rule_names: | |||
| raise GrammarError("Rule '%s' defined more than once" % name) | |||
| rule_names.add(name) | |||
| for name, expansions, _o in rules: | |||
| used_symbols = {t for x in expansions.find_data('expansion') | |||
| for t in x.scan_values(lambda t: t.type in ('RULE', 'TERMINAL'))} | |||
| for sym in used_symbols: | |||
| if sym.type == 'TERMINAL': | |||
| if sym not in terminal_names: | |||
| raise GrammarError("Token '%s' used but not defined (in rule %s)" % (sym, name)) | |||
| else: | |||
| if sym not in rule_names: | |||
| raise GrammarError("Rule '%s' used but not defined (in rule %s)" % (sym, name)) | |||
| return Grammar(rules, term_defs, ignore_names) | |||
| load_grammar = GrammarLoader().load_grammar | |||
+ 266
- 0
lark/parse_tree_builder.py
View File
| @@ -0,0 +1,266 @@ | |||
| from .exceptions import GrammarError | |||
| from .lexer import Token | |||
| from .tree import Tree | |||
| from .visitors import InlineTransformer # XXX Deprecated | |||
| from .visitors import Transformer_InPlace, Discard | |||
| ###{standalone | |||
| from functools import partial, wraps | |||
| from itertools import repeat, product | |||
| class ExpandSingleChild: | |||
| def __init__(self, node_builder): | |||
| self.node_builder = node_builder | |||
| def __call__(self, children): | |||
| if len(children) == 1: | |||
| return children[0] | |||
| else: | |||
| return self.node_builder(children) | |||
| class FilterDiscard: | |||
| def __init__(self, node_builder): | |||
| self.node_builder = node_builder | |||
| def __call__(self, children): | |||
| return self.node_builder([c for c in children if c is not Discard]) | |||
| class PropagatePositions: | |||
| def __init__(self, node_builder): | |||
| self.node_builder = node_builder | |||
| def __call__(self, children): | |||
| res = self.node_builder(children) | |||
| if isinstance(res, Tree): | |||
| for c in children: | |||
| if isinstance(c, Tree) and c.children and not c.meta.empty: | |||
| res.meta.line = c.meta.line | |||
| res.meta.column = c.meta.column | |||
| res.meta.start_pos = c.meta.start_pos | |||
| res.meta.empty = False | |||
| break | |||
| elif isinstance(c, Token): | |||
| res.meta.line = c.line | |||
| res.meta.column = c.column | |||
| res.meta.start_pos = c.pos_in_stream | |||
| res.meta.empty = False | |||
| break | |||
| for c in reversed(children): | |||
| if isinstance(c, Tree) and c.children and not c.meta.empty: | |||
| res.meta.end_line = c.meta.end_line | |||
| res.meta.end_column = c.meta.end_column | |||
| res.meta.end_pos = c.meta.end_pos | |||
| res.meta.empty = False | |||
| break | |||
| elif isinstance(c, Token): | |||
| res.meta.end_line = c.end_line | |||
| res.meta.end_column = c.end_column | |||
| res.meta.end_pos = c.pos_in_stream + len(c.value) | |||
| res.meta.empty = False | |||
| break | |||
| return res | |||
| class ChildFilter: | |||
| def __init__(self, to_include, append_none, node_builder): | |||
| self.node_builder = node_builder | |||
| self.to_include = to_include | |||
| self.append_none = append_none | |||
| def __call__(self, children): | |||
| filtered = [] | |||
| for i, to_expand, add_none in self.to_include: | |||
| if add_none: | |||
| filtered += [None] * add_none | |||
| if to_expand: | |||
| filtered += children[i].children | |||
| else: | |||
| filtered.append(children[i]) | |||
| if self.append_none: | |||
| filtered += [None] * self.append_none | |||
| return self.node_builder(filtered) | |||
| class ChildFilterLALR(ChildFilter): | |||
| "Optimized childfilter for LALR (assumes no duplication in parse tree, so it's safe to change it)" | |||
| def __call__(self, children): | |||
| filtered = [] | |||
| for i, to_expand, add_none in self.to_include: | |||
| if add_none: | |||
| filtered += [None] * add_none | |||
| if to_expand: | |||
| if filtered: | |||
| filtered += children[i].children | |||
| else: # Optimize for left-recursion | |||
| filtered = children[i].children | |||
| else: | |||
| filtered.append(children[i]) | |||
| if self.append_none: | |||
| filtered += [None] * self.append_none | |||
| return self.node_builder(filtered) | |||
| class ChildFilterLALR_NoPlaceholders(ChildFilter): | |||
| "Optimized childfilter for LALR (assumes no duplication in parse tree, so it's safe to change it)" | |||
| def __init__(self, to_include, node_builder): | |||
| self.node_builder = node_builder | |||
| self.to_include = to_include | |||
| def __call__(self, children): | |||
| filtered = [] | |||
| for i, to_expand in self.to_include: | |||
| if to_expand: | |||
| if filtered: | |||
| filtered += children[i].children | |||
| else: # Optimize for left-recursion | |||
| filtered = children[i].children | |||
| else: | |||
| filtered.append(children[i]) | |||
| return self.node_builder(filtered) | |||
| def _should_expand(sym): | |||
| return not sym.is_term and sym.name.startswith('_') | |||
| def maybe_create_child_filter(expansion, keep_all_tokens, ambiguous, _empty_indices): | |||
| # Prepare empty_indices as: How many Nones to insert at each index? | |||
| if _empty_indices: | |||
| assert _empty_indices.count(False) == len(expansion) | |||
| s = ''.join(str(int(b)) for b in _empty_indices) | |||
| empty_indices = [len(ones) for ones in s.split('0')] | |||
| assert len(empty_indices) == len(expansion)+1, (empty_indices, len(expansion)) | |||
| else: | |||
| empty_indices = [0] * (len(expansion)+1) | |||
| to_include = [] | |||
| nones_to_add = 0 | |||
| for i, sym in enumerate(expansion): | |||
| nones_to_add += empty_indices[i] | |||
| if keep_all_tokens or not (sym.is_term and sym.filter_out): | |||
| to_include.append((i, _should_expand(sym), nones_to_add)) | |||
| nones_to_add = 0 | |||
| nones_to_add += empty_indices[len(expansion)] | |||
| if _empty_indices or len(to_include) < len(expansion) or any(to_expand for i, to_expand,_ in to_include): | |||
| if _empty_indices or ambiguous: | |||
| return partial(ChildFilter if ambiguous else ChildFilterLALR, to_include, nones_to_add) | |||
| else: | |||
| # LALR without placeholders | |||
| return partial(ChildFilterLALR_NoPlaceholders, [(i, x) for i,x,_ in to_include]) | |||
| class AmbiguousExpander: | |||
| """Deal with the case where we're expanding children ('_rule') into a parent but the children | |||
| are ambiguous. i.e. (parent->_ambig->_expand_this_rule). In this case, make the parent itself | |||
| ambiguous with as many copies as their are ambiguous children, and then copy the ambiguous children | |||
| into the right parents in the right places, essentially shifting the ambiguiuty up the tree.""" | |||
| def __init__(self, to_expand, tree_class, node_builder): | |||
| self.node_builder = node_builder | |||
| self.tree_class = tree_class | |||
| self.to_expand = to_expand | |||
| def __call__(self, children): | |||
| def _is_ambig_tree(child): | |||
| return hasattr(child, 'data') and child.data == '_ambig' | |||
| #### When we're repeatedly expanding ambiguities we can end up with nested ambiguities. | |||
| # All children of an _ambig node should be a derivation of that ambig node, hence | |||
| # it is safe to assume that if we see an _ambig node nested within an ambig node | |||
| # it is safe to simply expand it into the parent _ambig node as an alternative derivation. | |||
| ambiguous = [] | |||
| for i, child in enumerate(children): | |||
| if _is_ambig_tree(child): | |||
| if i in self.to_expand: | |||
| ambiguous.append(i) | |||
| to_expand = [j for j, grandchild in enumerate(child.children) if _is_ambig_tree(grandchild)] | |||
| child.expand_kids_by_index(*to_expand) | |||
| if not ambiguous: | |||
| return self.node_builder(children) | |||
| expand = [ iter(child.children) if i in ambiguous else repeat(child) for i, child in enumerate(children) ] | |||
| return self.tree_class('_ambig', [self.node_builder(list(f[0])) for f in product(zip(*expand))]) | |||
| def maybe_create_ambiguous_expander(tree_class, expansion, keep_all_tokens): | |||
| to_expand = [i for i, sym in enumerate(expansion) | |||
| if keep_all_tokens or ((not (sym.is_term and sym.filter_out)) and _should_expand(sym))] | |||
| if to_expand: | |||
| return partial(AmbiguousExpander, to_expand, tree_class) | |||
| def ptb_inline_args(func): | |||
| @wraps(func) | |||
| def f(children): | |||
| return func(*children) | |||
| return f | |||
| def inplace_transformer(func): | |||
| @wraps(func) | |||
| def f(children): | |||
| # function name in a Transformer is a rule name. | |||
| tree = Tree(func.__name__, children) | |||
| return func(tree) | |||
| return f | |||
| class ParseTreeBuilder: | |||
| def __init__(self, rules, tree_class, propagate_positions=False, keep_all_tokens=False, ambiguous=False, maybe_placeholders=False): | |||
| self.tree_class = tree_class | |||
| self.propagate_positions = propagate_positions | |||
| self.always_keep_all_tokens = keep_all_tokens | |||
| self.ambiguous = ambiguous | |||
| self.maybe_placeholders = maybe_placeholders | |||
| self.rule_builders = list(self._init_builders(rules)) | |||
| def _init_builders(self, rules): | |||
| for rule in rules: | |||
| options = rule.options | |||
| keep_all_tokens = self.always_keep_all_tokens or (options.keep_all_tokens if options else False) | |||
| expand_single_child = options.expand1 if options else False | |||
| wrapper_chain = list(filter(None, [ | |||
| FilterDiscard, | |||
| (expand_single_child and not rule.alias) and ExpandSingleChild, | |||
| maybe_create_child_filter(rule.expansion, keep_all_tokens, self.ambiguous, options.empty_indices if self.maybe_placeholders and options else None), | |||
| self.propagate_positions and PropagatePositions, | |||
| self.ambiguous and maybe_create_ambiguous_expander(self.tree_class, rule.expansion, keep_all_tokens), | |||
| ])) | |||
| yield rule, wrapper_chain | |||
| def create_callback(self, transformer=None): | |||
| callbacks = {} | |||
| for rule, wrapper_chain in self.rule_builders: | |||
| user_callback_name = rule.alias or rule.origin.name | |||
| try: | |||
| f = getattr(transformer, user_callback_name) | |||
| assert not getattr(f, 'meta', False), "Meta args not supported for internal transformer" | |||
| # XXX InlineTransformer is deprecated! | |||
| if getattr(f, 'inline', False) or isinstance(transformer, InlineTransformer): | |||
| f = ptb_inline_args(f) | |||
| elif hasattr(f, 'whole_tree') or isinstance(transformer, Transformer_InPlace): | |||
| f = inplace_transformer(f) | |||
| except AttributeError: | |||
| f = partial(self.tree_class, user_callback_name) | |||
| for w in wrapper_chain: | |||
| f = w(f) | |||
| if rule in callbacks: | |||
| raise GrammarError("Rule '%s' already exists" % (rule,)) | |||
| callbacks[rule] = f | |||
| return callbacks | |||
| ###} | |||
+ 219
- 0
lark/parser_frontends.py
View File
| @@ -0,0 +1,219 @@ | |||
| import re | |||
| from functools import partial | |||
| from .utils import get_regexp_width, Serialize | |||
| from .parsers.grammar_analysis import GrammarAnalyzer | |||
| from .lexer import TraditionalLexer, ContextualLexer, Lexer, Token | |||
| from .parsers import earley, xearley, cyk | |||
| from .parsers.lalr_parser import LALR_Parser | |||
| from .grammar import Rule | |||
| from .tree import Tree | |||
| from .common import LexerConf | |||
| ###{standalone | |||
| def get_frontend(parser, lexer): | |||
| if parser=='lalr': | |||
| if lexer is None: | |||
| raise ValueError('The LALR parser requires use of a lexer') | |||
| elif lexer == 'standard': | |||
| return LALR_TraditionalLexer | |||
| elif lexer == 'contextual': | |||
| return LALR_ContextualLexer | |||
| elif issubclass(lexer, Lexer): | |||
| return partial(LALR_CustomLexer, lexer) | |||
| else: | |||
| raise ValueError('Unknown lexer: %s' % lexer) | |||
| elif parser=='earley': | |||
| if lexer=='standard': | |||
| return Earley | |||
| elif lexer=='dynamic': | |||
| return XEarley | |||
| elif lexer=='dynamic_complete': | |||
| return XEarley_CompleteLex | |||
| elif lexer=='contextual': | |||
| raise ValueError('The Earley parser does not support the contextual parser') | |||
| else: | |||
| raise ValueError('Unknown lexer: %s' % lexer) | |||
| elif parser == 'cyk': | |||
| if lexer == 'standard': | |||
| return CYK | |||
| else: | |||
| raise ValueError('CYK parser requires using standard parser.') | |||
| else: | |||
| raise ValueError('Unknown parser: %s' % parser) | |||
| class _ParserFrontend(Serialize): | |||
| def _parse(self, input, start, *args): | |||
| if start is None: | |||
| start = self.start | |||
| if len(start) > 1: | |||
| raise ValueError("Lark initialized with more than 1 possible start rule. Must specify which start rule to parse", start) | |||
| start ,= start | |||
| return self.parser.parse(input, start, *args) | |||
| class WithLexer(_ParserFrontend): | |||
| lexer = None | |||
| parser = None | |||
| lexer_conf = None | |||
| start = None | |||
| __serialize_fields__ = 'parser', 'lexer_conf', 'start' | |||
| __serialize_namespace__ = LexerConf, | |||
| def __init__(self, lexer_conf, parser_conf, options=None): | |||
| self.lexer_conf = lexer_conf | |||
| self.start = parser_conf.start | |||
| self.postlex = lexer_conf.postlex | |||
| @classmethod | |||
| def deserialize(cls, data, memo, callbacks, postlex): | |||
| inst = super(WithLexer, cls).deserialize(data, memo) | |||
| inst.postlex = postlex | |||
| inst.parser = LALR_Parser.deserialize(inst.parser, memo, callbacks) | |||
| inst.init_lexer() | |||
| return inst | |||
| def _serialize(self, data, memo): | |||
| data['parser'] = data['parser'].serialize(memo) | |||
| def lex(self, text): | |||
| stream = self.lexer.lex(text) | |||
| return self.postlex.process(stream) if self.postlex else stream | |||
| def parse(self, text, start=None): | |||
| token_stream = self.lex(text) | |||
| sps = self.lexer.set_parser_state | |||
| return self._parse(token_stream, start, *[sps] if sps is not NotImplemented else []) | |||
| def init_traditional_lexer(self): | |||
| self.lexer = TraditionalLexer(self.lexer_conf.tokens, ignore=self.lexer_conf.ignore, user_callbacks=self.lexer_conf.callbacks) | |||
| class LALR_WithLexer(WithLexer): | |||
| def __init__(self, lexer_conf, parser_conf, options=None): | |||
| debug = options.debug if options else False | |||
| self.parser = LALR_Parser(parser_conf, debug=debug) | |||
| WithLexer.__init__(self, lexer_conf, parser_conf, options) | |||
| self.init_lexer() | |||
| def init_lexer(self): | |||
| raise NotImplementedError() | |||
| class LALR_TraditionalLexer(LALR_WithLexer): | |||
| def init_lexer(self): | |||
| self.init_traditional_lexer() | |||
| class LALR_ContextualLexer(LALR_WithLexer): | |||
| def init_lexer(self): | |||
| states = {idx:list(t.keys()) for idx, t in self.parser._parse_table.states.items()} | |||
| always_accept = self.postlex.always_accept if self.postlex else () | |||
| self.lexer = ContextualLexer(self.lexer_conf.tokens, states, | |||
| ignore=self.lexer_conf.ignore, | |||
| always_accept=always_accept, | |||
| user_callbacks=self.lexer_conf.callbacks) | |||
| ###} | |||
| class LALR_CustomLexer(LALR_WithLexer): | |||
| def __init__(self, lexer_cls, lexer_conf, parser_conf, options=None): | |||
| self.lexer = lexer_cls(lexer_conf) | |||
| debug = options.debug if options else False | |||
| self.parser = LALR_Parser(parser_conf, debug=debug) | |||
| WithLexer.__init__(self, lexer_conf, parser_conf, options) | |||
| def tokenize_text(text): | |||
| line = 1 | |||
| col_start_pos = 0 | |||
| for i, ch in enumerate(text): | |||
| if '\n' in ch: | |||
| line += ch.count('\n') | |||
| col_start_pos = i + ch.rindex('\n') | |||
| yield Token('CHAR', ch, line=line, column=i - col_start_pos) | |||
| class Earley(WithLexer): | |||
| def __init__(self, lexer_conf, parser_conf, options=None): | |||
| WithLexer.__init__(self, lexer_conf, parser_conf, options) | |||
| self.init_traditional_lexer() | |||
| resolve_ambiguity = options.ambiguity == 'resolve' | |||
| debug = options.debug if options else False | |||
| self.parser = earley.Parser(parser_conf, self.match, resolve_ambiguity=resolve_ambiguity, debug=debug) | |||
| def match(self, term, token): | |||
| return term.name == token.type | |||
| class XEarley(_ParserFrontend): | |||
| def __init__(self, lexer_conf, parser_conf, options=None, **kw): | |||
| self.token_by_name = {t.name:t for t in lexer_conf.tokens} | |||
| self.start = parser_conf.start | |||
| self._prepare_match(lexer_conf) | |||
| resolve_ambiguity = options.ambiguity == 'resolve' | |||
| debug = options.debug if options else False | |||
| self.parser = xearley.Parser(parser_conf, | |||
| self.match, | |||
| ignore=lexer_conf.ignore, | |||
| resolve_ambiguity=resolve_ambiguity, | |||
| debug=debug, | |||
| **kw | |||
| ) | |||
| def match(self, term, text, index=0): | |||
| return self.regexps[term.name].match(text, index) | |||
| def _prepare_match(self, lexer_conf): | |||
| self.regexps = {} | |||
| for t in lexer_conf.tokens: | |||
| if t.priority != 1: | |||
| raise ValueError("Dynamic Earley doesn't support weights on terminals", t, t.priority) | |||
| regexp = t.pattern.to_regexp() | |||
| try: | |||
| width = get_regexp_width(regexp)[0] | |||
| except ValueError: | |||
| raise ValueError("Bad regexp in token %s: %s" % (t.name, regexp)) | |||
| else: | |||
| if width == 0: | |||
| raise ValueError("Dynamic Earley doesn't allow zero-width regexps", t) | |||
| self.regexps[t.name] = re.compile(regexp) | |||
| def parse(self, text, start): | |||
| return self._parse(text, start) | |||
| class XEarley_CompleteLex(XEarley): | |||
| def __init__(self, *args, **kw): | |||
| XEarley.__init__(self, *args, complete_lex=True, **kw) | |||
| class CYK(WithLexer): | |||
| def __init__(self, lexer_conf, parser_conf, options=None): | |||
| WithLexer.__init__(self, lexer_conf, parser_conf, options) | |||
| self.init_traditional_lexer() | |||
| self._analysis = GrammarAnalyzer(parser_conf) | |||
| self.parser = cyk.Parser(parser_conf.rules) | |||
| self.callbacks = parser_conf.callbacks | |||
| def parse(self, text, start): | |||
| tokens = list(self.lex(text)) | |||
| parse = self._parse(tokens, start) | |||
| parse = self._transform(parse) | |||
| return parse | |||
| def _transform(self, tree): | |||
| subtrees = list(tree.iter_subtrees()) | |||
| for subtree in subtrees: | |||
| subtree.children = [self._apply_callback(c) if isinstance(c, Tree) else c for c in subtree.children] | |||
| return self._apply_callback(tree) | |||
| def _apply_callback(self, tree): | |||
| return self.callbacks[tree.rule](tree.children) | |||
+ 0
- 0
lark/parsers/__init__.py
View File
+ 345
- 0
lark/parsers/cyk.py
View File
| @@ -0,0 +1,345 @@ | |||
| """This module implements a CYK parser.""" | |||
| # Author: https://github.com/ehudt (2018) | |||
| # | |||
| # Adapted by Erez | |||
| from collections import defaultdict | |||
| import itertools | |||
| from ..exceptions import ParseError | |||
| from ..lexer import Token | |||
| from ..tree import Tree | |||
| from ..grammar import Terminal as T, NonTerminal as NT, Symbol | |||
| try: | |||
| xrange | |||
| except NameError: | |||
| xrange = range | |||
| def match(t, s): | |||
| assert isinstance(t, T) | |||
| return t.name == s.type | |||
| class Rule(object): | |||
| """Context-free grammar rule.""" | |||
| def __init__(self, lhs, rhs, weight, alias): | |||
| super(Rule, self).__init__() | |||
| assert isinstance(lhs, NT), lhs | |||
| assert all(isinstance(x, NT) or isinstance(x, T) for x in rhs), rhs | |||
| self.lhs = lhs | |||
| self.rhs = rhs | |||
| self.weight = weight | |||
| self.alias = alias | |||
| def __str__(self): | |||
| return '%s -> %s' % (str(self.lhs), ' '.join(str(x) for x in self.rhs)) | |||
| def __repr__(self): | |||
| return str(self) | |||
| def __hash__(self): | |||
| return hash((self.lhs, tuple(self.rhs))) | |||
| def __eq__(self, other): | |||
| return self.lhs == other.lhs and self.rhs == other.rhs | |||
| def __ne__(self, other): | |||
| return not (self == other) | |||
| class Grammar(object): | |||
| """Context-free grammar.""" | |||
| def __init__(self, rules): | |||
| self.rules = frozenset(rules) | |||
| def __eq__(self, other): | |||
| return self.rules == other.rules | |||
| def __str__(self): | |||
| return '\n' + '\n'.join(sorted(repr(x) for x in self.rules)) + '\n' | |||
| def __repr__(self): | |||
| return str(self) | |||
| # Parse tree data structures | |||
| class RuleNode(object): | |||
| """A node in the parse tree, which also contains the full rhs rule.""" | |||
| def __init__(self, rule, children, weight=0): | |||
| self.rule = rule | |||
| self.children = children | |||
| self.weight = weight | |||
| def __repr__(self): | |||
| return 'RuleNode(%s, [%s])' % (repr(self.rule.lhs), ', '.join(str(x) for x in self.children)) | |||
| class Parser(object): | |||
| """Parser wrapper.""" | |||
| def __init__(self, rules): | |||
| super(Parser, self).__init__() | |||
| self.orig_rules = {rule: rule for rule in rules} | |||
| rules = [self._to_rule(rule) for rule in rules] | |||
| self.grammar = to_cnf(Grammar(rules)) | |||
| def _to_rule(self, lark_rule): | |||
| """Converts a lark rule, (lhs, rhs, callback, options), to a Rule.""" | |||
| assert isinstance(lark_rule.origin, NT) | |||
| assert all(isinstance(x, Symbol) for x in lark_rule.expansion) | |||
| return Rule( | |||
| lark_rule.origin, lark_rule.expansion, | |||
| weight=lark_rule.options.priority if lark_rule.options and lark_rule.options.priority else 0, | |||
| alias=lark_rule) | |||
| def parse(self, tokenized, start): # pylint: disable=invalid-name | |||
| """Parses input, which is a list of tokens.""" | |||
| assert start | |||
| start = NT(start) | |||
| table, trees = _parse(tokenized, self.grammar) | |||
| # Check if the parse succeeded. | |||
| if all(r.lhs != start for r in table[(0, len(tokenized) - 1)]): | |||
| raise ParseError('Parsing failed.') | |||
| parse = trees[(0, len(tokenized) - 1)][start] | |||
| return self._to_tree(revert_cnf(parse)) | |||
| def _to_tree(self, rule_node): | |||
| """Converts a RuleNode parse tree to a lark Tree.""" | |||
| orig_rule = self.orig_rules[rule_node.rule.alias] | |||
| children = [] | |||
| for child in rule_node.children: | |||
| if isinstance(child, RuleNode): | |||
| children.append(self._to_tree(child)) | |||
| else: | |||
| assert isinstance(child.name, Token) | |||
| children.append(child.name) | |||
| t = Tree(orig_rule.origin, children) | |||
| t.rule=orig_rule | |||
| return t | |||
| def print_parse(node, indent=0): | |||
| if isinstance(node, RuleNode): | |||
| print(' ' * (indent * 2) + str(node.rule.lhs)) | |||
| for child in node.children: | |||
| print_parse(child, indent + 1) | |||
| else: | |||
| print(' ' * (indent * 2) + str(node.s)) | |||
| def _parse(s, g): | |||
| """Parses sentence 's' using CNF grammar 'g'.""" | |||
| # The CYK table. Indexed with a 2-tuple: (start pos, end pos) | |||
| table = defaultdict(set) | |||
| # Top-level structure is similar to the CYK table. Each cell is a dict from | |||
| # rule name to the best (lightest) tree for that rule. | |||
| trees = defaultdict(dict) | |||
| # Populate base case with existing terminal production rules | |||
| for i, w in enumerate(s): | |||
| for terminal, rules in g.terminal_rules.items(): | |||
| if match(terminal, w): | |||
| for rule in rules: | |||
| table[(i, i)].add(rule) | |||
| if (rule.lhs not in trees[(i, i)] or | |||
| rule.weight < trees[(i, i)][rule.lhs].weight): | |||
| trees[(i, i)][rule.lhs] = RuleNode(rule, [T(w)], weight=rule.weight) | |||
| # Iterate over lengths of sub-sentences | |||
| for l in xrange(2, len(s) + 1): | |||
| # Iterate over sub-sentences with the given length | |||
| for i in xrange(len(s) - l + 1): | |||
| # Choose partition of the sub-sentence in [1, l) | |||
| for p in xrange(i + 1, i + l): | |||
| span1 = (i, p - 1) | |||
| span2 = (p, i + l - 1) | |||
| for r1, r2 in itertools.product(table[span1], table[span2]): | |||
| for rule in g.nonterminal_rules.get((r1.lhs, r2.lhs), []): | |||
| table[(i, i + l - 1)].add(rule) | |||
| r1_tree = trees[span1][r1.lhs] | |||
| r2_tree = trees[span2][r2.lhs] | |||
| rule_total_weight = rule.weight + r1_tree.weight + r2_tree.weight | |||
| if (rule.lhs not in trees[(i, i + l - 1)] | |||
| or rule_total_weight < trees[(i, i + l - 1)][rule.lhs].weight): | |||
| trees[(i, i + l - 1)][rule.lhs] = RuleNode(rule, [r1_tree, r2_tree], weight=rule_total_weight) | |||
| return table, trees | |||
| # This section implements context-free grammar converter to Chomsky normal form. | |||
| # It also implements a conversion of parse trees from its CNF to the original | |||
| # grammar. | |||
| # Overview: | |||
| # Applies the following operations in this order: | |||
| # * TERM: Eliminates non-solitary terminals from all rules | |||
| # * BIN: Eliminates rules with more than 2 symbols on their right-hand-side. | |||
| # * UNIT: Eliminates non-terminal unit rules | |||
| # | |||
| # The following grammar characteristics aren't featured: | |||
| # * Start symbol appears on RHS | |||
| # * Empty rules (epsilon rules) | |||
| class CnfWrapper(object): | |||
| """CNF wrapper for grammar. | |||
| Validates that the input grammar is CNF and provides helper data structures. | |||
| """ | |||
| def __init__(self, grammar): | |||
| super(CnfWrapper, self).__init__() | |||
| self.grammar = grammar | |||
| self.rules = grammar.rules | |||
| self.terminal_rules = defaultdict(list) | |||
| self.nonterminal_rules = defaultdict(list) | |||
| for r in self.rules: | |||
| # Validate that the grammar is CNF and populate auxiliary data structures. | |||
| assert isinstance(r.lhs, NT), r | |||
| if len(r.rhs) not in [1, 2]: | |||
| raise ParseError("CYK doesn't support empty rules") | |||
| if len(r.rhs) == 1 and isinstance(r.rhs[0], T): | |||
| self.terminal_rules[r.rhs[0]].append(r) | |||
| elif len(r.rhs) == 2 and all(isinstance(x, NT) for x in r.rhs): | |||
| self.nonterminal_rules[tuple(r.rhs)].append(r) | |||
| else: | |||
| assert False, r | |||
| def __eq__(self, other): | |||
| return self.grammar == other.grammar | |||
| def __repr__(self): | |||
| return repr(self.grammar) | |||
| class UnitSkipRule(Rule): | |||
| """A rule that records NTs that were skipped during transformation.""" | |||
| def __init__(self, lhs, rhs, skipped_rules, weight, alias): | |||
| super(UnitSkipRule, self).__init__(lhs, rhs, weight, alias) | |||
| self.skipped_rules = skipped_rules | |||
| def __eq__(self, other): | |||
| return isinstance(other, type(self)) and self.skipped_rules == other.skipped_rules | |||
| __hash__ = Rule.__hash__ | |||
| def build_unit_skiprule(unit_rule, target_rule): | |||
| skipped_rules = [] | |||
| if isinstance(unit_rule, UnitSkipRule): | |||
| skipped_rules += unit_rule.skipped_rules | |||
| skipped_rules.append(target_rule) | |||
| if isinstance(target_rule, UnitSkipRule): | |||
| skipped_rules += target_rule.skipped_rules | |||
| return UnitSkipRule(unit_rule.lhs, target_rule.rhs, skipped_rules, | |||
| weight=unit_rule.weight + target_rule.weight, alias=unit_rule.alias) | |||
| def get_any_nt_unit_rule(g): | |||
| """Returns a non-terminal unit rule from 'g', or None if there is none.""" | |||
| for rule in g.rules: | |||
| if len(rule.rhs) == 1 and isinstance(rule.rhs[0], NT): | |||
| return rule | |||
| return None | |||
| def _remove_unit_rule(g, rule): | |||
| """Removes 'rule' from 'g' without changing the langugage produced by 'g'.""" | |||
| new_rules = [x for x in g.rules if x != rule] | |||
| refs = [x for x in g.rules if x.lhs == rule.rhs[0]] | |||
| new_rules += [build_unit_skiprule(rule, ref) for ref in refs] | |||
| return Grammar(new_rules) | |||
| def _split(rule): | |||
| """Splits a rule whose len(rhs) > 2 into shorter rules.""" | |||
| rule_str = str(rule.lhs) + '__' + '_'.join(str(x) for x in rule.rhs) | |||
| rule_name = '__SP_%s' % (rule_str) + '_%d' | |||
| yield Rule(rule.lhs, [rule.rhs[0], NT(rule_name % 1)], weight=rule.weight, alias=rule.alias) | |||
| for i in xrange(1, len(rule.rhs) - 2): | |||
| yield Rule(NT(rule_name % i), [rule.rhs[i], NT(rule_name % (i + 1))], weight=0, alias='Split') | |||
| yield Rule(NT(rule_name % (len(rule.rhs) - 2)), rule.rhs[-2:], weight=0, alias='Split') | |||
| def _term(g): | |||
| """Applies the TERM rule on 'g' (see top comment).""" | |||
| all_t = {x for rule in g.rules for x in rule.rhs if isinstance(x, T)} | |||
| t_rules = {t: Rule(NT('__T_%s' % str(t)), [t], weight=0, alias='Term') for t in all_t} | |||
| new_rules = [] | |||
| for rule in g.rules: | |||
| if len(rule.rhs) > 1 and any(isinstance(x, T) for x in rule.rhs): | |||
| new_rhs = [t_rules[x].lhs if isinstance(x, T) else x for x in rule.rhs] | |||
| new_rules.append(Rule(rule.lhs, new_rhs, weight=rule.weight, alias=rule.alias)) | |||
| new_rules.extend(v for k, v in t_rules.items() if k in rule.rhs) | |||
| else: | |||
| new_rules.append(rule) | |||
| return Grammar(new_rules) | |||
| def _bin(g): | |||
| """Applies the BIN rule to 'g' (see top comment).""" | |||
| new_rules = [] | |||
| for rule in g.rules: | |||
| if len(rule.rhs) > 2: | |||
| new_rules += _split(rule) | |||
| else: | |||
| new_rules.append(rule) | |||
| return Grammar(new_rules) | |||
| def _unit(g): | |||
| """Applies the UNIT rule to 'g' (see top comment).""" | |||
| nt_unit_rule = get_any_nt_unit_rule(g) | |||
| while nt_unit_rule: | |||
| g = _remove_unit_rule(g, nt_unit_rule) | |||
| nt_unit_rule = get_any_nt_unit_rule(g) | |||
| return g | |||
| def to_cnf(g): | |||
| """Creates a CNF grammar from a general context-free grammar 'g'.""" | |||
| g = _unit(_bin(_term(g))) | |||
| return CnfWrapper(g) | |||
| def unroll_unit_skiprule(lhs, orig_rhs, skipped_rules, children, weight, alias): | |||
| if not skipped_rules: | |||
| return RuleNode(Rule(lhs, orig_rhs, weight=weight, alias=alias), children, weight=weight) | |||
| else: | |||
| weight = weight - skipped_rules[0].weight | |||
| return RuleNode( | |||
| Rule(lhs, [skipped_rules[0].lhs], weight=weight, alias=alias), [ | |||
| unroll_unit_skiprule(skipped_rules[0].lhs, orig_rhs, | |||
| skipped_rules[1:], children, | |||
| skipped_rules[0].weight, skipped_rules[0].alias) | |||
| ], weight=weight) | |||
| def revert_cnf(node): | |||
| """Reverts a parse tree (RuleNode) to its original non-CNF form (Node).""" | |||
| if isinstance(node, T): | |||
| return node | |||
| # Reverts TERM rule. | |||
| if node.rule.lhs.name.startswith('__T_'): | |||
| return node.children[0] | |||
| else: | |||
| children = [] | |||
| for child in map(revert_cnf, node.children): | |||
| # Reverts BIN rule. | |||
| if isinstance(child, RuleNode) and child.rule.lhs.name.startswith('__SP_'): | |||
| children += child.children | |||
| else: | |||
| children.append(child) | |||
| # Reverts UNIT rule. | |||
| if isinstance(node.rule, UnitSkipRule): | |||
| return unroll_unit_skiprule(node.rule.lhs, node.rule.rhs, | |||
| node.rule.skipped_rules, children, | |||
| node.rule.weight, node.rule.alias) | |||
| else: | |||
| return RuleNode(node.rule, children) | |||
+ 322
- 0
lark/parsers/earley.py
View File
| @@ -0,0 +1,322 @@ | |||
| """This module implements an scanerless Earley parser. | |||
| The core Earley algorithm used here is based on Elizabeth Scott's implementation, here: | |||
| https://www.sciencedirect.com/science/article/pii/S1571066108001497 | |||
| That is probably the best reference for understanding the algorithm here. | |||
| The Earley parser outputs an SPPF-tree as per that document. The SPPF tree format | |||
| is better documented here: | |||
| http://www.bramvandersanden.com/post/2014/06/shared-packed-parse-forest/ | |||
| """ | |||
| from collections import deque | |||
| from ..visitors import Transformer_InPlace, v_args | |||
| from ..exceptions import ParseError, UnexpectedToken | |||
| from .grammar_analysis import GrammarAnalyzer | |||
| from ..grammar import NonTerminal | |||
| from .earley_common import Item, TransitiveItem | |||
| from .earley_forest import ForestToTreeVisitor, ForestSumVisitor, SymbolNode, ForestToAmbiguousTreeVisitor | |||
| class Parser: | |||
| def __init__(self, parser_conf, term_matcher, resolve_ambiguity=True, debug=False): | |||
| analysis = GrammarAnalyzer(parser_conf) | |||
| self.parser_conf = parser_conf | |||
| self.resolve_ambiguity = resolve_ambiguity | |||
| self.debug = debug | |||
| self.FIRST = analysis.FIRST | |||
| self.NULLABLE = analysis.NULLABLE | |||
| self.callbacks = parser_conf.callbacks | |||
| self.predictions = {} | |||
| ## These could be moved to the grammar analyzer. Pre-computing these is *much* faster than | |||
| # the slow 'isupper' in is_terminal. | |||
| self.TERMINALS = { sym for r in parser_conf.rules for sym in r.expansion if sym.is_term } | |||
| self.NON_TERMINALS = { sym for r in parser_conf.rules for sym in r.expansion if not sym.is_term } | |||
| self.forest_sum_visitor = None | |||
| for rule in parser_conf.rules: | |||
| self.predictions[rule.origin] = [x.rule for x in analysis.expand_rule(rule.origin)] | |||
| ## Detect if any rules have priorities set. If the user specified priority = "none" then | |||
| # the priorities will be stripped from all rules before they reach us, allowing us to | |||
| # skip the extra tree walk. We'll also skip this if the user just didn't specify priorities | |||
| # on any rules. | |||
| if self.forest_sum_visitor is None and rule.options and rule.options.priority is not None: | |||
| self.forest_sum_visitor = ForestSumVisitor() | |||
| if resolve_ambiguity: | |||
| self.forest_tree_visitor = ForestToTreeVisitor(self.callbacks, self.forest_sum_visitor) | |||
| else: | |||
| self.forest_tree_visitor = ForestToAmbiguousTreeVisitor(self.callbacks, self.forest_sum_visitor) | |||
| self.term_matcher = term_matcher | |||
| def predict_and_complete(self, i, to_scan, columns, transitives): | |||
| """The core Earley Predictor and Completer. | |||
| At each stage of the input, we handling any completed items (things | |||
| that matched on the last cycle) and use those to predict what should | |||
| come next in the input stream. The completions and any predicted | |||
| non-terminals are recursively processed until we reach a set of, | |||
| which can be added to the scan list for the next scanner cycle.""" | |||
| # Held Completions (H in E.Scotts paper). | |||
| node_cache = {} | |||
| held_completions = {} | |||
| column = columns[i] | |||
| # R (items) = Ei (column.items) | |||
| items = deque(column) | |||
| while items: | |||
| item = items.pop() # remove an element, A say, from R | |||
| ### The Earley completer | |||
| if item.is_complete: ### (item.s == string) | |||
| if item.node is None: | |||
| label = (item.s, item.start, i) | |||
| item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| item.node.add_family(item.s, item.rule, item.start, None, None) | |||
| # create_leo_transitives(item.rule.origin, item.start) | |||
| ###R Joop Leo right recursion Completer | |||
| if item.rule.origin in transitives[item.start]: | |||
| transitive = transitives[item.start][item.s] | |||
| if transitive.previous in transitives[transitive.column]: | |||
| root_transitive = transitives[transitive.column][transitive.previous] | |||
| else: | |||
| root_transitive = transitive | |||
| new_item = Item(transitive.rule, transitive.ptr, transitive.start) | |||
| label = (root_transitive.s, root_transitive.start, i) | |||
| new_item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| new_item.node.add_path(root_transitive, item.node) | |||
| if new_item.expect in self.TERMINALS: | |||
| # Add (B :: aC.B, h, y) to Q | |||
| to_scan.add(new_item) | |||
| elif new_item not in column: | |||
| # Add (B :: aC.B, h, y) to Ei and R | |||
| column.add(new_item) | |||
| items.append(new_item) | |||
| ###R Regular Earley completer | |||
| else: | |||
| # Empty has 0 length. If we complete an empty symbol in a particular | |||
| # parse step, we need to be able to use that same empty symbol to complete | |||
| # any predictions that result, that themselves require empty. Avoids | |||
| # infinite recursion on empty symbols. | |||
| # held_completions is 'H' in E.Scott's paper. | |||
| is_empty_item = item.start == i | |||
| if is_empty_item: | |||
| held_completions[item.rule.origin] = item.node | |||
| originators = [originator for originator in columns[item.start] if originator.expect is not None and originator.expect == item.s] | |||
| for originator in originators: | |||
| new_item = originator.advance() | |||
| label = (new_item.s, originator.start, i) | |||
| new_item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| new_item.node.add_family(new_item.s, new_item.rule, i, originator.node, item.node) | |||
| if new_item.expect in self.TERMINALS: | |||
| # Add (B :: aC.B, h, y) to Q | |||
| to_scan.add(new_item) | |||
| elif new_item not in column: | |||
| # Add (B :: aC.B, h, y) to Ei and R | |||
| column.add(new_item) | |||
| items.append(new_item) | |||
| ### The Earley predictor | |||
| elif item.expect in self.NON_TERMINALS: ### (item.s == lr0) | |||
| new_items = [] | |||
| for rule in self.predictions[item.expect]: | |||
| new_item = Item(rule, 0, i) | |||
| new_items.append(new_item) | |||
| # Process any held completions (H). | |||
| if item.expect in held_completions: | |||
| new_item = item.advance() | |||
| label = (new_item.s, item.start, i) | |||
| new_item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| new_item.node.add_family(new_item.s, new_item.rule, new_item.start, item.node, held_completions[item.expect]) | |||
| new_items.append(new_item) | |||
| for new_item in new_items: | |||
| if new_item.expect in self.TERMINALS: | |||
| to_scan.add(new_item) | |||
| elif new_item not in column: | |||
| column.add(new_item) | |||
| items.append(new_item) | |||
| def _parse(self, stream, columns, to_scan, start_symbol=None): | |||
| def is_quasi_complete(item): | |||
| if item.is_complete: | |||
| return True | |||
| quasi = item.advance() | |||
| while not quasi.is_complete: | |||
| if quasi.expect not in self.NULLABLE: | |||
| return False | |||
| if quasi.rule.origin == start_symbol and quasi.expect == start_symbol: | |||
| return False | |||
| quasi = quasi.advance() | |||
| return True | |||
| def create_leo_transitives(origin, start): | |||
| visited = set() | |||
| to_create = [] | |||
| trule = None | |||
| previous = None | |||
| ### Recursively walk backwards through the Earley sets until we find the | |||
| # first transitive candidate. If this is done continuously, we shouldn't | |||
| # have to walk more than 1 hop. | |||
| while True: | |||
| if origin in transitives[start]: | |||
| previous = trule = transitives[start][origin] | |||
| break | |||
| is_empty_rule = not self.FIRST[origin] | |||
| if is_empty_rule: | |||
| break | |||
| candidates = [ candidate for candidate in columns[start] if candidate.expect is not None and origin == candidate.expect ] | |||
| if len(candidates) != 1: | |||
| break | |||
| originator = next(iter(candidates)) | |||
| if originator is None or originator in visited: | |||
| break | |||
| visited.add(originator) | |||
| if not is_quasi_complete(originator): | |||
| break | |||
| trule = originator.advance() | |||
| if originator.start != start: | |||
| visited.clear() | |||
| to_create.append((origin, start, originator)) | |||
| origin = originator.rule.origin | |||
| start = originator.start | |||
| # If a suitable Transitive candidate is not found, bail. | |||
| if trule is None: | |||
| return | |||
| #### Now walk forwards and create Transitive Items in each set we walked through; and link | |||
| # each transitive item to the next set forwards. | |||
| while to_create: | |||
| origin, start, originator = to_create.pop() | |||
| titem = None | |||
| if previous is not None: | |||
| titem = previous.next_titem = TransitiveItem(origin, trule, originator, previous.column) | |||
| else: | |||
| titem = TransitiveItem(origin, trule, originator, start) | |||
| previous = transitives[start][origin] = titem | |||
| def scan(i, token, to_scan): | |||
| """The core Earley Scanner. | |||
| This is a custom implementation of the scanner that uses the | |||
| Lark lexer to match tokens. The scan list is built by the | |||
| Earley predictor, based on the previously completed tokens. | |||
| This ensures that at each phase of the parse we have a custom | |||
| lexer context, allowing for more complex ambiguities.""" | |||
| next_to_scan = set() | |||
| next_set = set() | |||
| columns.append(next_set) | |||
| transitives.append({}) | |||
| node_cache = {} | |||
| for item in set(to_scan): | |||
| if match(item.expect, token): | |||
| new_item = item.advance() | |||
| label = (new_item.s, new_item.start, i) | |||
| new_item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| new_item.node.add_family(new_item.s, item.rule, new_item.start, item.node, token) | |||
| if new_item.expect in self.TERMINALS: | |||
| # add (B ::= Aai+1.B, h, y) to Q' | |||
| next_to_scan.add(new_item) | |||
| else: | |||
| # add (B ::= Aa+1.B, h, y) to Ei+1 | |||
| next_set.add(new_item) | |||
| if not next_set and not next_to_scan: | |||
| expect = {i.expect.name for i in to_scan} | |||
| raise UnexpectedToken(token, expect, considered_rules = set(to_scan)) | |||
| return next_to_scan | |||
| # Define parser functions | |||
| match = self.term_matcher | |||
| # Cache for nodes & tokens created in a particular parse step. | |||
| transitives = [{}] | |||
| ## The main Earley loop. | |||
| # Run the Prediction/Completion cycle for any Items in the current Earley set. | |||
| # Completions will be added to the SPPF tree, and predictions will be recursively | |||
| # processed down to terminals/empty nodes to be added to the scanner for the next | |||
| # step. | |||
| i = 0 | |||
| for token in stream: | |||
| self.predict_and_complete(i, to_scan, columns, transitives) | |||
| to_scan = scan(i, token, to_scan) | |||
| i += 1 | |||
| self.predict_and_complete(i, to_scan, columns, transitives) | |||
| ## Column is now the final column in the parse. | |||
| assert i == len(columns)-1 | |||
| def parse(self, stream, start): | |||
| assert start, start | |||
| start_symbol = NonTerminal(start) | |||
| columns = [set()] | |||
| to_scan = set() # The scan buffer. 'Q' in E.Scott's paper. | |||
| ## Predict for the start_symbol. | |||
| # Add predicted items to the first Earley set (for the predictor) if they | |||
| # result in a non-terminal, or the scanner if they result in a terminal. | |||
| for rule in self.predictions[start_symbol]: | |||
| item = Item(rule, 0, 0) | |||
| if item.expect in self.TERMINALS: | |||
| to_scan.add(item) | |||
| else: | |||
| columns[0].add(item) | |||
| self._parse(stream, columns, to_scan, start_symbol) | |||
| # If the parse was successful, the start | |||
| # symbol should have been completed in the last step of the Earley cycle, and will be in | |||
| # this column. Find the item for the start_symbol, which is the root of the SPPF tree. | |||
| solutions = [n.node for n in columns[-1] if n.is_complete and n.node is not None and n.s == start_symbol and n.start == 0] | |||
| if self.debug: | |||
| from .earley_forest import ForestToPyDotVisitor | |||
| debug_walker = ForestToPyDotVisitor() | |||
| debug_walker.visit(solutions[0], "sppf.png") | |||
| if not solutions: | |||
| expected_tokens = [t.expect for t in to_scan] | |||
| # raise ParseError('Incomplete parse: Could not find a solution to input') | |||
| raise ParseError('Unexpected end of input! Expecting a terminal of: %s' % expected_tokens) | |||
| elif len(solutions) > 1: | |||
| assert False, 'Earley should not generate multiple start symbol items!' | |||
| # Perform our SPPF -> AST conversion using the right ForestVisitor. | |||
| return self.forest_tree_visitor.visit(solutions[0]) | |||
| class ApplyCallbacks(Transformer_InPlace): | |||
| def __init__(self, postprocess): | |||
| self.postprocess = postprocess | |||
| @v_args(meta=True) | |||
| def drv(self, children, meta): | |||
| return self.postprocess[meta.rule](children) | |||
+ 75
- 0
lark/parsers/earley_common.py
View File
| @@ -0,0 +1,75 @@ | |||
| "This module implements an Earley Parser" | |||
| # The parser uses a parse-forest to keep track of derivations and ambiguations. | |||
| # When the parse ends successfully, a disambiguation stage resolves all ambiguity | |||
| # (right now ambiguity resolution is not developed beyond the needs of lark) | |||
| # Afterwards the parse tree is reduced (transformed) according to user callbacks. | |||
| # I use the no-recursion version of Transformer, because the tree might be | |||
| # deeper than Python's recursion limit (a bit absurd, but that's life) | |||
| # | |||
| # The algorithm keeps track of each state set, using a corresponding Column instance. | |||
| # Column keeps track of new items using NewsList instances. | |||
| # | |||
| # Author: Erez Shinan (2017) | |||
| # Email : erezshin@gmail.com | |||
| from ..grammar import NonTerminal, Terminal | |||
| class Item(object): | |||
| "An Earley Item, the atom of the algorithm." | |||
| __slots__ = ('s', 'rule', 'ptr', 'start', 'is_complete', 'expect', 'previous', 'node', '_hash') | |||
| def __init__(self, rule, ptr, start): | |||
| self.is_complete = len(rule.expansion) == ptr | |||
| self.rule = rule # rule | |||
| self.ptr = ptr # ptr | |||
| self.start = start # j | |||
| self.node = None # w | |||
| if self.is_complete: | |||
| self.s = rule.origin | |||
| self.expect = None | |||
| self.previous = rule.expansion[ptr - 1] if ptr > 0 and len(rule.expansion) else None | |||
| else: | |||
| self.s = (rule, ptr) | |||
| self.expect = rule.expansion[ptr] | |||
| self.previous = rule.expansion[ptr - 1] if ptr > 0 and len(rule.expansion) else None | |||
| self._hash = hash((self.s, self.start)) | |||
| def advance(self): | |||
| return Item(self.rule, self.ptr + 1, self.start) | |||
| def __eq__(self, other): | |||
| return self is other or (self.s == other.s and self.start == other.start) | |||
| def __hash__(self): | |||
| return self._hash | |||
| def __repr__(self): | |||
| before = ( expansion.name for expansion in self.rule.expansion[:self.ptr] ) | |||
| after = ( expansion.name for expansion in self.rule.expansion[self.ptr:] ) | |||
| symbol = "{} ::= {}* {}".format(self.rule.origin.name, ' '.join(before), ' '.join(after)) | |||
| return '%s (%d)' % (symbol, self.start) | |||
| class TransitiveItem(Item): | |||
| __slots__ = ('recognized', 'reduction', 'column', 'next_titem') | |||
| def __init__(self, recognized, trule, originator, start): | |||
| super(TransitiveItem, self).__init__(trule.rule, trule.ptr, trule.start) | |||
| self.recognized = recognized | |||
| self.reduction = originator | |||
| self.column = start | |||
| self.next_titem = None | |||
| self._hash = hash((self.s, self.start, self.recognized)) | |||
| def __eq__(self, other): | |||
| if not isinstance(other, TransitiveItem): | |||
| return False | |||
| return self is other or (type(self.s) == type(other.s) and self.s == other.s and self.start == other.start and self.recognized == other.recognized) | |||
| def __hash__(self): | |||
| return self._hash | |||
| def __repr__(self): | |||
| before = ( expansion.name for expansion in self.rule.expansion[:self.ptr] ) | |||
| after = ( expansion.name for expansion in self.rule.expansion[self.ptr:] ) | |||
| return '{} : {} -> {}* {} ({}, {})'.format(self.recognized.name, self.rule.origin.name, ' '.join(before), ' '.join(after), self.column, self.start) | |||
+ 430
- 0
lark/parsers/earley_forest.py
View File
| @@ -0,0 +1,430 @@ | |||
| """"This module implements an SPPF implementation | |||
| This is used as the primary output mechanism for the Earley parser | |||
| in order to store complex ambiguities. | |||
| Full reference and more details is here: | |||
| http://www.bramvandersanden.com/post/2014/06/shared-packed-parse-forest/ | |||
| """ | |||
| from random import randint | |||
| from math import isinf | |||
| from collections import deque | |||
| from operator import attrgetter | |||
| from importlib import import_module | |||
| from ..tree import Tree | |||
| from ..exceptions import ParseError | |||
| class ForestNode(object): | |||
| pass | |||
| class SymbolNode(ForestNode): | |||
| """ | |||
| A Symbol Node represents a symbol (or Intermediate LR0). | |||
| Symbol nodes are keyed by the symbol (s). For intermediate nodes | |||
| s will be an LR0, stored as a tuple of (rule, ptr). For completed symbol | |||
| nodes, s will be a string representing the non-terminal origin (i.e. | |||
| the left hand side of the rule). | |||
| The children of a Symbol or Intermediate Node will always be Packed Nodes; | |||
| with each Packed Node child representing a single derivation of a production. | |||
| Hence a Symbol Node with a single child is unambiguous. | |||
| """ | |||
| __slots__ = ('s', 'start', 'end', '_children', 'paths', 'paths_loaded', 'priority', 'is_intermediate', '_hash') | |||
| def __init__(self, s, start, end): | |||
| self.s = s | |||
| self.start = start | |||
| self.end = end | |||
| self._children = set() | |||
| self.paths = set() | |||
| self.paths_loaded = False | |||
| ### We use inf here as it can be safely negated without resorting to conditionals, | |||
| # unlike None or float('NaN'), and sorts appropriately. | |||
| self.priority = float('-inf') | |||
| self.is_intermediate = isinstance(s, tuple) | |||
| self._hash = hash((self.s, self.start, self.end)) | |||
| def add_family(self, lr0, rule, start, left, right): | |||
| self._children.add(PackedNode(self, lr0, rule, start, left, right)) | |||
| def add_path(self, transitive, node): | |||
| self.paths.add((transitive, node)) | |||
| def load_paths(self): | |||
| for transitive, node in self.paths: | |||
| if transitive.next_titem is not None: | |||
| vn = SymbolNode(transitive.next_titem.s, transitive.next_titem.start, self.end) | |||
| vn.add_path(transitive.next_titem, node) | |||
| self.add_family(transitive.reduction.rule.origin, transitive.reduction.rule, transitive.reduction.start, transitive.reduction.node, vn) | |||
| else: | |||
| self.add_family(transitive.reduction.rule.origin, transitive.reduction.rule, transitive.reduction.start, transitive.reduction.node, node) | |||
| self.paths_loaded = True | |||
| @property | |||
| def is_ambiguous(self): | |||
| return len(self.children) > 1 | |||
| @property | |||
| def children(self): | |||
| if not self.paths_loaded: self.load_paths() | |||
| return sorted(self._children, key=attrgetter('sort_key')) | |||
| def __iter__(self): | |||
| return iter(self._children) | |||
| def __eq__(self, other): | |||
| if not isinstance(other, SymbolNode): | |||
| return False | |||
| return self is other or (type(self.s) == type(other.s) and self.s == other.s and self.start == other.start and self.end is other.end) | |||
| def __hash__(self): | |||
| return self._hash | |||
| def __repr__(self): | |||
| if self.is_intermediate: | |||
| rule = self.s[0] | |||
| ptr = self.s[1] | |||
| before = ( expansion.name for expansion in rule.expansion[:ptr] ) | |||
| after = ( expansion.name for expansion in rule.expansion[ptr:] ) | |||
| symbol = "{} ::= {}* {}".format(rule.origin.name, ' '.join(before), ' '.join(after)) | |||
| else: | |||
| symbol = self.s.name | |||
| return "({}, {}, {}, {})".format(symbol, self.start, self.end, self.priority) | |||
| class PackedNode(ForestNode): | |||
| """ | |||
| A Packed Node represents a single derivation in a symbol node. | |||
| """ | |||
| __slots__ = ('parent', 's', 'rule', 'start', 'left', 'right', 'priority', '_hash') | |||
| def __init__(self, parent, s, rule, start, left, right): | |||
| self.parent = parent | |||
| self.s = s | |||
| self.start = start | |||
| self.rule = rule | |||
| self.left = left | |||
| self.right = right | |||
| self.priority = float('-inf') | |||
| self._hash = hash((self.left, self.right)) | |||
| @property | |||
| def is_empty(self): | |||
| return self.left is None and self.right is None | |||
| @property | |||
| def sort_key(self): | |||
| """ | |||
| Used to sort PackedNode children of SymbolNodes. | |||
| A SymbolNode has multiple PackedNodes if it matched | |||
| ambiguously. Hence, we use the sort order to identify | |||
| the order in which ambiguous children should be considered. | |||
| """ | |||
| return self.is_empty, -self.priority, self.rule.order | |||
| def __iter__(self): | |||
| return iter([self.left, self.right]) | |||
| def __eq__(self, other): | |||
| if not isinstance(other, PackedNode): | |||
| return False | |||
| return self is other or (self.left == other.left and self.right == other.right) | |||
| def __hash__(self): | |||
| return self._hash | |||
| def __repr__(self): | |||
| if isinstance(self.s, tuple): | |||
| rule = self.s[0] | |||
| ptr = self.s[1] | |||
| before = ( expansion.name for expansion in rule.expansion[:ptr] ) | |||
| after = ( expansion.name for expansion in rule.expansion[ptr:] ) | |||
| symbol = "{} ::= {}* {}".format(rule.origin.name, ' '.join(before), ' '.join(after)) | |||
| else: | |||
| symbol = self.s.name | |||
| return "({}, {}, {}, {})".format(symbol, self.start, self.priority, self.rule.order) | |||
| class ForestVisitor(object): | |||
| """ | |||
| An abstract base class for building forest visitors. | |||
| Use this as a base when you need to walk the forest. | |||
| """ | |||
| __slots__ = ['result'] | |||
| def visit_token_node(self, node): pass | |||
| def visit_symbol_node_in(self, node): pass | |||
| def visit_symbol_node_out(self, node): pass | |||
| def visit_packed_node_in(self, node): pass | |||
| def visit_packed_node_out(self, node): pass | |||
| def visit(self, root): | |||
| self.result = None | |||
| # Visiting is a list of IDs of all symbol/intermediate nodes currently in | |||
| # the stack. It serves two purposes: to detect when we 'recurse' in and out | |||
| # of a symbol/intermediate so that we can process both up and down. Also, | |||
| # since the SPPF can have cycles it allows us to detect if we're trying | |||
| # to recurse into a node that's already on the stack (infinite recursion). | |||
| visiting = set() | |||
| # We do not use recursion here to walk the Forest due to the limited | |||
| # stack size in python. Therefore input_stack is essentially our stack. | |||
| input_stack = deque([root]) | |||
| # It is much faster to cache these as locals since they are called | |||
| # many times in large parses. | |||
| vpno = getattr(self, 'visit_packed_node_out') | |||
| vpni = getattr(self, 'visit_packed_node_in') | |||
| vsno = getattr(self, 'visit_symbol_node_out') | |||
| vsni = getattr(self, 'visit_symbol_node_in') | |||
| vtn = getattr(self, 'visit_token_node') | |||
| while input_stack: | |||
| current = next(reversed(input_stack)) | |||
| try: | |||
| next_node = next(current) | |||
| except StopIteration: | |||
| input_stack.pop() | |||
| continue | |||
| except TypeError: | |||
| ### If the current object is not an iterator, pass through to Token/SymbolNode | |||
| pass | |||
| else: | |||
| if next_node is None: | |||
| continue | |||
| if id(next_node) in visiting: | |||
| raise ParseError("Infinite recursion in grammar!") | |||
| input_stack.append(next_node) | |||
| continue | |||
| if not isinstance(current, ForestNode): | |||
| vtn(current) | |||
| input_stack.pop() | |||
| continue | |||
| current_id = id(current) | |||
| if current_id in visiting: | |||
| if isinstance(current, PackedNode): vpno(current) | |||
| else: vsno(current) | |||
| input_stack.pop() | |||
| visiting.remove(current_id) | |||
| continue | |||
| else: | |||
| visiting.add(current_id) | |||
| if isinstance(current, PackedNode): next_node = vpni(current) | |||
| else: next_node = vsni(current) | |||
| if next_node is None: | |||
| continue | |||
| if id(next_node) in visiting: | |||
| raise ParseError("Infinite recursion in grammar!") | |||
| input_stack.append(next_node) | |||
| continue | |||
| return self.result | |||
| class ForestSumVisitor(ForestVisitor): | |||
| """ | |||
| A visitor for prioritizing ambiguous parts of the Forest. | |||
| This visitor is used when support for explicit priorities on | |||
| rules is requested (whether normal, or invert). It walks the | |||
| forest (or subsets thereof) and cascades properties upwards | |||
| from the leaves. | |||
| It would be ideal to do this during parsing, however this would | |||
| require processing each Earley item multiple times. That's | |||
| a big performance drawback; so running a forest walk is the | |||
| lesser of two evils: there can be significantly more Earley | |||
| items created during parsing than there are SPPF nodes in the | |||
| final tree. | |||
| """ | |||
| def visit_packed_node_in(self, node): | |||
| return iter([node.left, node.right]) | |||
| def visit_symbol_node_in(self, node): | |||
| return iter(node.children) | |||
| def visit_packed_node_out(self, node): | |||
| priority = node.rule.options.priority if not node.parent.is_intermediate and node.rule.options and node.rule.options.priority else 0 | |||
| priority += getattr(node.right, 'priority', 0) | |||
| priority += getattr(node.left, 'priority', 0) | |||
| node.priority = priority | |||
| def visit_symbol_node_out(self, node): | |||
| node.priority = max(child.priority for child in node.children) | |||
| class ForestToTreeVisitor(ForestVisitor): | |||
| """ | |||
| A Forest visitor which converts an SPPF forest to an unambiguous AST. | |||
| The implementation in this visitor walks only the first ambiguous child | |||
| of each symbol node. When it finds an ambiguous symbol node it first | |||
| calls the forest_sum_visitor implementation to sort the children | |||
| into preference order using the algorithms defined there; so the first | |||
| child should always be the highest preference. The forest_sum_visitor | |||
| implementation should be another ForestVisitor which sorts the children | |||
| according to some priority mechanism. | |||
| """ | |||
| __slots__ = ['forest_sum_visitor', 'callbacks', 'output_stack'] | |||
| def __init__(self, callbacks, forest_sum_visitor = None): | |||
| assert callbacks | |||
| self.forest_sum_visitor = forest_sum_visitor | |||
| self.callbacks = callbacks | |||
| def visit(self, root): | |||
| self.output_stack = deque() | |||
| return super(ForestToTreeVisitor, self).visit(root) | |||
| def visit_token_node(self, node): | |||
| self.output_stack[-1].append(node) | |||
| def visit_symbol_node_in(self, node): | |||
| if self.forest_sum_visitor and node.is_ambiguous and isinf(node.priority): | |||
| self.forest_sum_visitor.visit(node) | |||
| return next(iter(node.children)) | |||
| def visit_packed_node_in(self, node): | |||
| if not node.parent.is_intermediate: | |||
| self.output_stack.append([]) | |||
| return iter([node.left, node.right]) | |||
| def visit_packed_node_out(self, node): | |||
| if not node.parent.is_intermediate: | |||
| result = self.callbacks[node.rule](self.output_stack.pop()) | |||
| if self.output_stack: | |||
| self.output_stack[-1].append(result) | |||
| else: | |||
| self.result = result | |||
| class ForestToAmbiguousTreeVisitor(ForestToTreeVisitor): | |||
| """ | |||
| A Forest visitor which converts an SPPF forest to an ambiguous AST. | |||
| Because of the fundamental disparity between what can be stored in | |||
| an SPPF and what can be stored in a Tree; this implementation is not | |||
| complete. It correctly deals with ambiguities that occur on symbol nodes only, | |||
| and cannot deal with ambiguities that occur on intermediate nodes. | |||
| Usually, most parsers can be rewritten to avoid intermediate node | |||
| ambiguities. Also, this implementation could be fixed, however | |||
| the code to handle intermediate node ambiguities is messy and | |||
| would not be performant. It is much better not to use this and | |||
| instead to correctly disambiguate the forest and only store unambiguous | |||
| parses in Trees. It is here just to provide some parity with the | |||
| old ambiguity='explicit'. | |||
| This is mainly used by the test framework, to make it simpler to write | |||
| tests ensuring the SPPF contains the right results. | |||
| """ | |||
| def __init__(self, callbacks, forest_sum_visitor = ForestSumVisitor): | |||
| super(ForestToAmbiguousTreeVisitor, self).__init__(callbacks, forest_sum_visitor) | |||
| def visit_token_node(self, node): | |||
| self.output_stack[-1].children.append(node) | |||
| def visit_symbol_node_in(self, node): | |||
| if self.forest_sum_visitor and node.is_ambiguous and isinf(node.priority): | |||
| self.forest_sum_visitor.visit(node) | |||
| if not node.is_intermediate and node.is_ambiguous: | |||
| self.output_stack.append(Tree('_ambig', [])) | |||
| return iter(node.children) | |||
| def visit_symbol_node_out(self, node): | |||
| if not node.is_intermediate and node.is_ambiguous: | |||
| result = self.output_stack.pop() | |||
| if self.output_stack: | |||
| self.output_stack[-1].children.append(result) | |||
| else: | |||
| self.result = result | |||
| def visit_packed_node_in(self, node): | |||
| if not node.parent.is_intermediate: | |||
| self.output_stack.append(Tree('drv', [])) | |||
| return iter([node.left, node.right]) | |||
| def visit_packed_node_out(self, node): | |||
| if not node.parent.is_intermediate: | |||
| result = self.callbacks[node.rule](self.output_stack.pop().children) | |||
| if self.output_stack: | |||
| self.output_stack[-1].children.append(result) | |||
| else: | |||
| self.result = result | |||
| class ForestToPyDotVisitor(ForestVisitor): | |||
| """ | |||
| A Forest visitor which writes the SPPF to a PNG. | |||
| The SPPF can get really large, really quickly because | |||
| of the amount of meta-data it stores, so this is probably | |||
| only useful for trivial trees and learning how the SPPF | |||
| is structured. | |||
| """ | |||
| def __init__(self, rankdir="TB"): | |||
| self.pydot = import_module('pydot') | |||
| self.graph = self.pydot.Dot(graph_type='digraph', rankdir=rankdir) | |||
| def visit(self, root, filename): | |||
| super(ForestToPyDotVisitor, self).visit(root) | |||
| self.graph.write_png(filename) | |||
| def visit_token_node(self, node): | |||
| graph_node_id = str(id(node)) | |||
| graph_node_label = "\"{}\"".format(node.value.replace('"', '\\"')) | |||
| graph_node_color = 0x808080 | |||
| graph_node_style = "\"filled,rounded\"" | |||
| graph_node_shape = "diamond" | |||
| graph_node = self.pydot.Node(graph_node_id, style=graph_node_style, fillcolor="#{:06x}".format(graph_node_color), shape=graph_node_shape, label=graph_node_label) | |||
| self.graph.add_node(graph_node) | |||
| def visit_packed_node_in(self, node): | |||
| graph_node_id = str(id(node)) | |||
| graph_node_label = repr(node) | |||
| graph_node_color = 0x808080 | |||
| graph_node_style = "filled" | |||
| graph_node_shape = "diamond" | |||
| graph_node = self.pydot.Node(graph_node_id, style=graph_node_style, fillcolor="#{:06x}".format(graph_node_color), shape=graph_node_shape, label=graph_node_label) | |||
| self.graph.add_node(graph_node) | |||
| return iter([node.left, node.right]) | |||
| def visit_packed_node_out(self, node): | |||
| graph_node_id = str(id(node)) | |||
| graph_node = self.graph.get_node(graph_node_id)[0] | |||
| for child in [node.left, node.right]: | |||
| if child is not None: | |||
| child_graph_node_id = str(id(child)) | |||
| child_graph_node = self.graph.get_node(child_graph_node_id)[0] | |||
| self.graph.add_edge(self.pydot.Edge(graph_node, child_graph_node)) | |||
| else: | |||
| #### Try and be above the Python object ID range; probably impl. specific, but maybe this is okay. | |||
| child_graph_node_id = str(randint(100000000000000000000000000000,123456789012345678901234567890)) | |||
| child_graph_node_style = "invis" | |||
| child_graph_node = self.pydot.Node(child_graph_node_id, style=child_graph_node_style, label="None") | |||
| child_edge_style = "invis" | |||
| self.graph.add_node(child_graph_node) | |||
| self.graph.add_edge(self.pydot.Edge(graph_node, child_graph_node, style=child_edge_style)) | |||
| def visit_symbol_node_in(self, node): | |||
| graph_node_id = str(id(node)) | |||
| graph_node_label = repr(node) | |||
| graph_node_color = 0x808080 | |||
| graph_node_style = "\"filled\"" | |||
| if node.is_intermediate: | |||
| graph_node_shape = "ellipse" | |||
| else: | |||
| graph_node_shape = "rectangle" | |||
| graph_node = self.pydot.Node(graph_node_id, style=graph_node_style, fillcolor="#{:06x}".format(graph_node_color), shape=graph_node_shape, label=graph_node_label) | |||
| self.graph.add_node(graph_node) | |||
| return iter(node.children) | |||
| def visit_symbol_node_out(self, node): | |||
| graph_node_id = str(id(node)) | |||
| graph_node = self.graph.get_node(graph_node_id)[0] | |||
| for child in node.children: | |||
| child_graph_node_id = str(id(child)) | |||
| child_graph_node = self.graph.get_node(child_graph_node_id)[0] | |||
| self.graph.add_edge(self.pydot.Edge(graph_node, child_graph_node)) | |||
+ 155
- 0
lark/parsers/grammar_analysis.py
View File
| @@ -0,0 +1,155 @@ | |||
| from collections import Counter | |||
| from ..utils import bfs, fzset, classify | |||
| from ..exceptions import GrammarError | |||
| from ..grammar import Rule, Terminal, NonTerminal | |||
| class RulePtr(object): | |||
| __slots__ = ('rule', 'index') | |||
| def __init__(self, rule, index): | |||
| assert isinstance(rule, Rule) | |||
| assert index <= len(rule.expansion) | |||
| self.rule = rule | |||
| self.index = index | |||
| def __repr__(self): | |||
| before = [x.name for x in self.rule.expansion[:self.index]] | |||
| after = [x.name for x in self.rule.expansion[self.index:]] | |||
| return '<%s : %s * %s>' % (self.rule.origin.name, ' '.join(before), ' '.join(after)) | |||
| @property | |||
| def next(self): | |||
| return self.rule.expansion[self.index] | |||
| def advance(self, sym): | |||
| assert self.next == sym | |||
| return RulePtr(self.rule, self.index+1) | |||
| @property | |||
| def is_satisfied(self): | |||
| return self.index == len(self.rule.expansion) | |||
| def __eq__(self, other): | |||
| return self.rule == other.rule and self.index == other.index | |||
| def __hash__(self): | |||
| return hash((self.rule, self.index)) | |||
| def update_set(set1, set2): | |||
| if not set2 or set1 > set2: | |||
| return False | |||
| copy = set(set1) | |||
| set1 |= set2 | |||
| return set1 != copy | |||
| def calculate_sets(rules): | |||
| """Calculate FOLLOW sets. | |||
| Adapted from: http://lara.epfl.ch/w/cc09:algorithm_for_first_and_follow_sets""" | |||
| symbols = {sym for rule in rules for sym in rule.expansion} | {rule.origin for rule in rules} | |||
| # foreach grammar rule X ::= Y(1) ... Y(k) | |||
| # if k=0 or {Y(1),...,Y(k)} subset of NULLABLE then | |||
| # NULLABLE = NULLABLE union {X} | |||
| # for i = 1 to k | |||
| # if i=1 or {Y(1),...,Y(i-1)} subset of NULLABLE then | |||
| # FIRST(X) = FIRST(X) union FIRST(Y(i)) | |||
| # for j = i+1 to k | |||
| # if i=k or {Y(i+1),...Y(k)} subset of NULLABLE then | |||
| # FOLLOW(Y(i)) = FOLLOW(Y(i)) union FOLLOW(X) | |||
| # if i+1=j or {Y(i+1),...,Y(j-1)} subset of NULLABLE then | |||
| # FOLLOW(Y(i)) = FOLLOW(Y(i)) union FIRST(Y(j)) | |||
| # until none of NULLABLE,FIRST,FOLLOW changed in last iteration | |||
| NULLABLE = set() | |||
| FIRST = {} | |||
| FOLLOW = {} | |||
| for sym in symbols: | |||
| FIRST[sym]={sym} if sym.is_term else set() | |||
| FOLLOW[sym]=set() | |||
| # Calculate NULLABLE and FIRST | |||
| changed = True | |||
| while changed: | |||
| changed = False | |||
| for rule in rules: | |||
| if set(rule.expansion) <= NULLABLE: | |||
| if update_set(NULLABLE, {rule.origin}): | |||
| changed = True | |||
| for i, sym in enumerate(rule.expansion): | |||
| if set(rule.expansion[:i]) <= NULLABLE: | |||
| if update_set(FIRST[rule.origin], FIRST[sym]): | |||
| changed = True | |||
| else: | |||
| break | |||
| # Calculate FOLLOW | |||
| changed = True | |||
| while changed: | |||
| changed = False | |||
| for rule in rules: | |||
| for i, sym in enumerate(rule.expansion): | |||
| if i==len(rule.expansion)-1 or set(rule.expansion[i+1:]) <= NULLABLE: | |||
| if update_set(FOLLOW[sym], FOLLOW[rule.origin]): | |||
| changed = True | |||
| for j in range(i+1, len(rule.expansion)): | |||
| if set(rule.expansion[i+1:j]) <= NULLABLE: | |||
| if update_set(FOLLOW[sym], FIRST[rule.expansion[j]]): | |||
| changed = True | |||
| return FIRST, FOLLOW, NULLABLE | |||
| class GrammarAnalyzer(object): | |||
| def __init__(self, parser_conf, debug=False): | |||
| self.debug = debug | |||
| root_rules = {start: Rule(NonTerminal('$root_' + start), [NonTerminal(start), Terminal('$END')]) | |||
| for start in parser_conf.start} | |||
| rules = parser_conf.rules + list(root_rules.values()) | |||
| self.rules_by_origin = classify(rules, lambda r: r.origin) | |||
| if len(rules) != len(set(rules)): | |||
| duplicates = [item for item, count in Counter(rules).items() if count > 1] | |||
| raise GrammarError("Rules defined twice: %s" % ', '.join(str(i) for i in duplicates)) | |||
| for r in rules: | |||
| for sym in r.expansion: | |||
| if not (sym.is_term or sym in self.rules_by_origin): | |||
| raise GrammarError("Using an undefined rule: %s" % sym) # TODO test validation | |||
| self.start_states = {start: self.expand_rule(root_rule.origin) | |||
| for start, root_rule in root_rules.items()} | |||
| self.end_states = {start: fzset({RulePtr(root_rule, len(root_rule.expansion))}) | |||
| for start, root_rule in root_rules.items()} | |||
| self.FIRST, self.FOLLOW, self.NULLABLE = calculate_sets(rules) | |||
| def expand_rule(self, source_rule): | |||
| "Returns all init_ptrs accessible by rule (recursive)" | |||
| init_ptrs = set() | |||
| def _expand_rule(rule): | |||
| assert not rule.is_term, rule | |||
| for r in self.rules_by_origin[rule]: | |||
| init_ptr = RulePtr(r, 0) | |||
| init_ptrs.add(init_ptr) | |||
| if r.expansion: # if not empty rule | |||
| new_r = init_ptr.next | |||
| if not new_r.is_term: | |||
| yield new_r | |||
| for _ in bfs([source_rule], _expand_rule): | |||
| pass | |||
| return fzset(init_ptrs) | |||
+ 136
- 0
lark/parsers/lalr_analysis.py
View File
| @@ -0,0 +1,136 @@ | |||
| """This module builds a LALR(1) transition-table for lalr_parser.py | |||
| For now, shift/reduce conflicts are automatically resolved as shifts. | |||
| """ | |||
| # Author: Erez Shinan (2017) | |||
| # Email : erezshin@gmail.com | |||
| import logging | |||
| from collections import defaultdict | |||
| from ..utils import classify, classify_bool, bfs, fzset, Serialize, Enumerator | |||
| from ..exceptions import GrammarError | |||
| from .grammar_analysis import GrammarAnalyzer, Terminal | |||
| from ..grammar import Rule | |||
| ###{standalone | |||
| class Action: | |||
| def __init__(self, name): | |||
| self.name = name | |||
| def __str__(self): | |||
| return self.name | |||
| def __repr__(self): | |||
| return str(self) | |||
| Shift = Action('Shift') | |||
| Reduce = Action('Reduce') | |||
| class ParseTable: | |||
| def __init__(self, states, start_states, end_states): | |||
| self.states = states | |||
| self.start_states = start_states | |||
| self.end_states = end_states | |||
| def serialize(self, memo): | |||
| tokens = Enumerator() | |||
| rules = Enumerator() | |||
| states = { | |||
| state: {tokens.get(token): ((1, arg.serialize(memo)) if action is Reduce else (0, arg)) | |||
| for token, (action, arg) in actions.items()} | |||
| for state, actions in self.states.items() | |||
| } | |||
| return { | |||
| 'tokens': tokens.reversed(), | |||
| 'states': states, | |||
| 'start_states': self.start_states, | |||
| 'end_states': self.end_states, | |||
| } | |||
| @classmethod | |||
| def deserialize(cls, data, memo): | |||
| tokens = data['tokens'] | |||
| states = { | |||
| state: {tokens[token]: ((Reduce, Rule.deserialize(arg, memo)) if action==1 else (Shift, arg)) | |||
| for token, (action, arg) in actions.items()} | |||
| for state, actions in data['states'].items() | |||
| } | |||
| return cls(states, data['start_states'], data['end_states']) | |||
| class IntParseTable(ParseTable): | |||
| @classmethod | |||
| def from_ParseTable(cls, parse_table): | |||
| enum = list(parse_table.states) | |||
| state_to_idx = {s:i for i,s in enumerate(enum)} | |||
| int_states = {} | |||
| for s, la in parse_table.states.items(): | |||
| la = {k:(v[0], state_to_idx[v[1]]) if v[0] is Shift else v | |||
| for k,v in la.items()} | |||
| int_states[ state_to_idx[s] ] = la | |||
| start_states = {start:state_to_idx[s] for start, s in parse_table.start_states.items()} | |||
| end_states = {start:state_to_idx[s] for start, s in parse_table.end_states.items()} | |||
| return cls(int_states, start_states, end_states) | |||
| ###} | |||
| class LALR_Analyzer(GrammarAnalyzer): | |||
| def compute_lookahead(self): | |||
| self.states = {} | |||
| def step(state): | |||
| lookahead = defaultdict(list) | |||
| sat, unsat = classify_bool(state, lambda rp: rp.is_satisfied) | |||
| for rp in sat: | |||
| for term in self.FOLLOW.get(rp.rule.origin, ()): | |||
| lookahead[term].append((Reduce, rp.rule)) | |||
| d = classify(unsat, lambda rp: rp.next) | |||
| for sym, rps in d.items(): | |||
| rps = {rp.advance(sym) for rp in rps} | |||
| for rp in set(rps): | |||
| if not rp.is_satisfied and not rp.next.is_term: | |||
| rps |= self.expand_rule(rp.next) | |||
| new_state = fzset(rps) | |||
| lookahead[sym].append((Shift, new_state)) | |||
| yield new_state | |||
| for k, v in lookahead.items(): | |||
| if len(v) > 1: | |||
| if self.debug: | |||
| logging.warning("Shift/reduce conflict for terminal %s: (resolving as shift)", k.name) | |||
| for act, arg in v: | |||
| logging.warning(' * %s: %s', act, arg) | |||
| for x in v: | |||
| # XXX resolving shift/reduce into shift, like PLY | |||
| # Give a proper warning | |||
| if x[0] is Shift: | |||
| lookahead[k] = [x] | |||
| for k, v in lookahead.items(): | |||
| if not len(v) == 1: | |||
| raise GrammarError("Collision in %s: %s" %(k, ', '.join(['\n * %s: %s' % x for x in v]))) | |||
| self.states[state] = {k.name:v[0] for k, v in lookahead.items()} | |||
| for _ in bfs(self.start_states.values(), step): | |||
| pass | |||
| self._parse_table = ParseTable(self.states, self.start_states, self.end_states) | |||
| if self.debug: | |||
| self.parse_table = self._parse_table | |||
| else: | |||
| self.parse_table = IntParseTable.from_ParseTable(self._parse_table) | |||
+ 107
- 0
lark/parsers/lalr_parser.py
View File
| @@ -0,0 +1,107 @@ | |||
| """This module implements a LALR(1) Parser | |||
| """ | |||
| # Author: Erez Shinan (2017) | |||
| # Email : erezshin@gmail.com | |||
| from ..exceptions import UnexpectedToken | |||
| from ..lexer import Token | |||
| from ..utils import Enumerator, Serialize | |||
| from .lalr_analysis import LALR_Analyzer, Shift, IntParseTable | |||
| ###{standalone | |||
| class LALR_Parser(object): | |||
| def __init__(self, parser_conf, debug=False): | |||
| assert all(r.options is None or r.options.priority is None | |||
| for r in parser_conf.rules), "LALR doesn't yet support prioritization" | |||
| analysis = LALR_Analyzer(parser_conf, debug=debug) | |||
| analysis.compute_lookahead() | |||
| callbacks = parser_conf.callbacks | |||
| self._parse_table = analysis.parse_table | |||
| self.parser_conf = parser_conf | |||
| self.parser = _Parser(analysis.parse_table, callbacks) | |||
| @classmethod | |||
| def deserialize(cls, data, memo, callbacks): | |||
| inst = cls.__new__(cls) | |||
| inst._parse_table = IntParseTable.deserialize(data, memo) | |||
| inst.parser = _Parser(inst._parse_table, callbacks) | |||
| return inst | |||
| def serialize(self, memo): | |||
| return self._parse_table.serialize(memo) | |||
| def parse(self, *args): | |||
| return self.parser.parse(*args) | |||
| class _Parser: | |||
| def __init__(self, parse_table, callbacks): | |||
| self.states = parse_table.states | |||
| self.start_states = parse_table.start_states | |||
| self.end_states = parse_table.end_states | |||
| self.callbacks = callbacks | |||
| def parse(self, seq, start, set_state=None): | |||
| token = None | |||
| stream = iter(seq) | |||
| states = self.states | |||
| start_state = self.start_states[start] | |||
| end_state = self.end_states[start] | |||
| state_stack = [start_state] | |||
| value_stack = [] | |||
| if set_state: set_state(start_state) | |||
| def get_action(token): | |||
| state = state_stack[-1] | |||
| try: | |||
| return states[state][token.type] | |||
| except KeyError: | |||
| expected = [s for s in states[state].keys() if s.isupper()] | |||
| raise UnexpectedToken(token, expected, state=state) | |||
| def reduce(rule): | |||
| size = len(rule.expansion) | |||
| if size: | |||
| s = value_stack[-size:] | |||
| del state_stack[-size:] | |||
| del value_stack[-size:] | |||
| else: | |||
| s = [] | |||
| value = self.callbacks[rule](s) | |||
| _action, new_state = states[state_stack[-1]][rule.origin.name] | |||
| assert _action is Shift | |||
| state_stack.append(new_state) | |||
| value_stack.append(value) | |||
| # Main LALR-parser loop | |||
| for token in stream: | |||
| while True: | |||
| action, arg = get_action(token) | |||
| assert arg != end_state | |||
| if action is Shift: | |||
| state_stack.append(arg) | |||
| value_stack.append(token) | |||
| if set_state: set_state(arg) | |||
| break # next token | |||
| else: | |||
| reduce(arg) | |||
| token = Token.new_borrow_pos('$END', '', token) if token else Token('$END', '', 0, 1, 1) | |||
| while True: | |||
| _action, arg = get_action(token) | |||
| if _action is Shift: | |||
| assert arg == end_state | |||
| val ,= value_stack | |||
| return val | |||
| else: | |||
| reduce(arg) | |||
| ###} | |||
+ 149
- 0
lark/parsers/xearley.py
View File
| @@ -0,0 +1,149 @@ | |||
| """This module implements an experimental Earley parser with a dynamic lexer | |||
| The core Earley algorithm used here is based on Elizabeth Scott's implementation, here: | |||
| https://www.sciencedirect.com/science/article/pii/S1571066108001497 | |||
| That is probably the best reference for understanding the algorithm here. | |||
| The Earley parser outputs an SPPF-tree as per that document. The SPPF tree format | |||
| is better documented here: | |||
| http://www.bramvandersanden.com/post/2014/06/shared-packed-parse-forest/ | |||
| Instead of running a lexer beforehand, or using a costy char-by-char method, this parser | |||
| uses regular expressions by necessity, achieving high-performance while maintaining all of | |||
| Earley's power in parsing any CFG. | |||
| """ | |||
| from collections import defaultdict | |||
| from ..exceptions import UnexpectedCharacters | |||
| from ..lexer import Token | |||
| from ..grammar import Terminal | |||
| from .earley import Parser as BaseParser | |||
| from .earley_forest import SymbolNode | |||
| class Parser(BaseParser): | |||
| def __init__(self, parser_conf, term_matcher, resolve_ambiguity=True, ignore = (), complete_lex = False, debug=False): | |||
| BaseParser.__init__(self, parser_conf, term_matcher, resolve_ambiguity, debug) | |||
| self.ignore = [Terminal(t) for t in ignore] | |||
| self.complete_lex = complete_lex | |||
| def _parse(self, stream, columns, to_scan, start_symbol=None): | |||
| def scan(i, to_scan): | |||
| """The core Earley Scanner. | |||
| This is a custom implementation of the scanner that uses the | |||
| Lark lexer to match tokens. The scan list is built by the | |||
| Earley predictor, based on the previously completed tokens. | |||
| This ensures that at each phase of the parse we have a custom | |||
| lexer context, allowing for more complex ambiguities.""" | |||
| node_cache = {} | |||
| # 1) Loop the expectations and ask the lexer to match. | |||
| # Since regexp is forward looking on the input stream, and we only | |||
| # want to process tokens when we hit the point in the stream at which | |||
| # they complete, we push all tokens into a buffer (delayed_matches), to | |||
| # be held possibly for a later parse step when we reach the point in the | |||
| # input stream at which they complete. | |||
| for item in set(to_scan): | |||
| m = match(item.expect, stream, i) | |||
| if m: | |||
| t = Token(item.expect.name, m.group(0), i, text_line, text_column) | |||
| delayed_matches[m.end()].append( (item, i, t) ) | |||
| if self.complete_lex: | |||
| s = m.group(0) | |||
| for j in range(1, len(s)): | |||
| m = match(item.expect, s[:-j]) | |||
| if m: | |||
| t = Token(item.expect.name, m.group(0), i, text_line, text_column) | |||
| delayed_matches[i+m.end()].append( (item, i, t) ) | |||
| # Remove any items that successfully matched in this pass from the to_scan buffer. | |||
| # This ensures we don't carry over tokens that already matched, if we're ignoring below. | |||
| to_scan.remove(item) | |||
| # 3) Process any ignores. This is typically used for e.g. whitespace. | |||
| # We carry over any unmatched items from the to_scan buffer to be matched again after | |||
| # the ignore. This should allow us to use ignored symbols in non-terminals to implement | |||
| # e.g. mandatory spacing. | |||
| for x in self.ignore: | |||
| m = match(x, stream, i) | |||
| if m: | |||
| # Carry over any items still in the scan buffer, to past the end of the ignored items. | |||
| delayed_matches[m.end()].extend([(item, i, None) for item in to_scan ]) | |||
| # If we're ignoring up to the end of the file, # carry over the start symbol if it already completed. | |||
| delayed_matches[m.end()].extend([(item, i, None) for item in columns[i] if item.is_complete and item.s == start_symbol]) | |||
| next_to_scan = set() | |||
| next_set = set() | |||
| columns.append(next_set) | |||
| transitives.append({}) | |||
| ## 4) Process Tokens from delayed_matches. | |||
| # This is the core of the Earley scanner. Create an SPPF node for each Token, | |||
| # and create the symbol node in the SPPF tree. Advance the item that completed, | |||
| # and add the resulting new item to either the Earley set (for processing by the | |||
| # completer/predictor) or the to_scan buffer for the next parse step. | |||
| for item, start, token in delayed_matches[i+1]: | |||
| if token is not None: | |||
| token.end_line = text_line | |||
| token.end_column = text_column + 1 | |||
| new_item = item.advance() | |||
| label = (new_item.s, new_item.start, i) | |||
| new_item.node = node_cache[label] if label in node_cache else node_cache.setdefault(label, SymbolNode(*label)) | |||
| new_item.node.add_family(new_item.s, item.rule, new_item.start, item.node, token) | |||
| else: | |||
| new_item = item | |||
| if new_item.expect in self.TERMINALS: | |||
| # add (B ::= Aai+1.B, h, y) to Q' | |||
| next_to_scan.add(new_item) | |||
| else: | |||
| # add (B ::= Aa+1.B, h, y) to Ei+1 | |||
| next_set.add(new_item) | |||
| del delayed_matches[i+1] # No longer needed, so unburden memory | |||
| if not next_set and not delayed_matches and not next_to_scan: | |||
| raise UnexpectedCharacters(stream, i, text_line, text_column, {item.expect.name for item in to_scan}, set(to_scan)) | |||
| return next_to_scan | |||
| delayed_matches = defaultdict(list) | |||
| match = self.term_matcher | |||
| # Cache for nodes & tokens created in a particular parse step. | |||
| transitives = [{}] | |||
| text_line = 1 | |||
| text_column = 1 | |||
| ## The main Earley loop. | |||
| # Run the Prediction/Completion cycle for any Items in the current Earley set. | |||
| # Completions will be added to the SPPF tree, and predictions will be recursively | |||
| # processed down to terminals/empty nodes to be added to the scanner for the next | |||
| # step. | |||
| i = 0 | |||
| for token in stream: | |||
| self.predict_and_complete(i, to_scan, columns, transitives) | |||
| to_scan = scan(i, to_scan) | |||
| if token == '\n': | |||
| text_line += 1 | |||
| text_column = 1 | |||
| else: | |||
| text_column += 1 | |||
| i += 1 | |||
| self.predict_and_complete(i, to_scan, columns, transitives) | |||
| ## Column is now the final column in the parse. | |||
| assert i == len(columns)-1 | |||
+ 129
- 0
lark/reconstruct.py
View File
| @@ -0,0 +1,129 @@ | |||
| from collections import defaultdict | |||
| from .tree import Tree | |||
| from .visitors import Transformer_InPlace | |||
| from .common import ParserConf | |||
| from .lexer import Token, PatternStr | |||
| from .parsers import earley | |||
| from .grammar import Rule, Terminal, NonTerminal | |||
| def is_discarded_terminal(t): | |||
| return t.is_term and t.filter_out | |||
| def is_iter_empty(i): | |||
| try: | |||
| _ = next(i) | |||
| return False | |||
| except StopIteration: | |||
| return True | |||
| class WriteTokensTransformer(Transformer_InPlace): | |||
| def __init__(self, tokens): | |||
| self.tokens = tokens | |||
| def __default__(self, data, children, meta): | |||
| # if not isinstance(t, MatchTree): | |||
| # return t | |||
| if not getattr(meta, 'match_tree', False): | |||
| return Tree(data, children) | |||
| iter_args = iter(children) | |||
| to_write = [] | |||
| for sym in meta.orig_expansion: | |||
| if is_discarded_terminal(sym): | |||
| t = self.tokens[sym.name] | |||
| if not isinstance(t.pattern, PatternStr): | |||
| raise NotImplementedError("Reconstructing regexps not supported yet: %s" % t) | |||
| to_write.append(t.pattern.value) | |||
| else: | |||
| x = next(iter_args) | |||
| if isinstance(x, list): | |||
| to_write += x | |||
| else: | |||
| if isinstance(x, Token): | |||
| assert Terminal(x.type) == sym, x | |||
| else: | |||
| assert NonTerminal(x.data) == sym, (sym, x) | |||
| to_write.append(x) | |||
| assert is_iter_empty(iter_args) | |||
| return to_write | |||
| class MatchTree(Tree): | |||
| pass | |||
| class MakeMatchTree: | |||
| def __init__(self, name, expansion): | |||
| self.name = name | |||
| self.expansion = expansion | |||
| def __call__(self, args): | |||
| t = MatchTree(self.name, args) | |||
| t.meta.match_tree = True | |||
| t.meta.orig_expansion = self.expansion | |||
| return t | |||
| class Reconstructor: | |||
| def __init__(self, parser): | |||
| # XXX TODO calling compile twice returns different results! | |||
| tokens, rules, _grammar_extra = parser.grammar.compile(parser.options.start) | |||
| self.write_tokens = WriteTokensTransformer({t.name:t for t in tokens}) | |||
| self.rules = list(self._build_recons_rules(rules)) | |||
| callbacks = {rule: rule.alias for rule in self.rules} # TODO pass callbacks through dict, instead of alias? | |||
| self.parser = earley.Parser(ParserConf(self.rules, callbacks, parser.options.start), | |||
| self._match, resolve_ambiguity=True) | |||
| def _build_recons_rules(self, rules): | |||
| expand1s = {r.origin for r in rules if r.options and r.options.expand1} | |||
| aliases = defaultdict(list) | |||
| for r in rules: | |||
| if r.alias: | |||
| aliases[r.origin].append( r.alias ) | |||
| rule_names = {r.origin for r in rules} | |||
| nonterminals = {sym for sym in rule_names | |||
| if sym.name.startswith('_') or sym in expand1s or sym in aliases } | |||
| for r in rules: | |||
| recons_exp = [sym if sym in nonterminals else Terminal(sym.name) | |||
| for sym in r.expansion if not is_discarded_terminal(sym)] | |||
| # Skip self-recursive constructs | |||
| if recons_exp == [r.origin]: | |||
| continue | |||
| sym = NonTerminal(r.alias) if r.alias else r.origin | |||
| yield Rule(sym, recons_exp, alias=MakeMatchTree(sym.name, r.expansion)) | |||
| for origin, rule_aliases in aliases.items(): | |||
| for alias in rule_aliases: | |||
| yield Rule(origin, [Terminal(alias)], alias=MakeMatchTree(origin.name, [NonTerminal(alias)])) | |||
| yield Rule(origin, [Terminal(origin.name)], alias=MakeMatchTree(origin.name, [origin])) | |||
| def _match(self, term, token): | |||
| if isinstance(token, Tree): | |||
| return Terminal(token.data) == term | |||
| elif isinstance(token, Token): | |||
| return term == Terminal(token.type) | |||
| assert False | |||
| def _reconstruct(self, tree): | |||
| # TODO: ambiguity? | |||
| unreduced_tree = self.parser.parse(tree.children, tree.data) # find a full derivation | |||
| assert unreduced_tree.data == tree.data | |||
| res = self.write_tokens.transform(unreduced_tree) | |||
| for item in res: | |||
| if isinstance(item, Tree): | |||
| for x in self._reconstruct(item): | |||
| yield x | |||
| else: | |||
| yield item | |||
| def reconstruct(self, tree): | |||
| return ''.join(self._reconstruct(tree)) | |||
+ 0
- 0
lark/tools/__init__.py
View File
+ 190
- 0
lark/tools/nearley.py
View File
| @@ -0,0 +1,190 @@ | |||
| "Converts between Lark and Nearley grammars. Work in progress!" | |||
| import os.path | |||
| import sys | |||
| import codecs | |||
| from lark import Lark, InlineTransformer | |||
| nearley_grammar = r""" | |||
| start: (ruledef|directive)+ | |||
| directive: "@" NAME (STRING|NAME) | |||
| | "@" JS -> js_code | |||
| ruledef: NAME "->" expansions | |||
| | NAME REGEXP "->" expansions -> macro | |||
| expansions: expansion ("|" expansion)* | |||
| expansion: expr+ js | |||
| ?expr: item [":" /[+*?]/] | |||
| ?item: rule|string|regexp|null | |||
| | "(" expansions ")" | |||
| rule: NAME | |||
| string: STRING | |||
| regexp: REGEXP | |||
| null: "null" | |||
| JS: /{%.*?%}/s | |||
| js: JS? | |||
| NAME: /[a-zA-Z_$]\w*/ | |||
| COMMENT: /#[^\n]*/ | |||
| REGEXP: /\[.*?\]/ | |||
| %import common.ESCAPED_STRING -> STRING | |||
| %import common.WS | |||
| %ignore WS | |||
| %ignore COMMENT | |||
| """ | |||
| nearley_grammar_parser = Lark(nearley_grammar, parser='earley', lexer='standard') | |||
| def _get_rulename(name): | |||
| name = {'_': '_ws_maybe', '__':'_ws'}.get(name, name) | |||
| return 'n_' + name.replace('$', '__DOLLAR__').lower() | |||
| class NearleyToLark(InlineTransformer): | |||
| def __init__(self): | |||
| self._count = 0 | |||
| self.extra_rules = {} | |||
| self.extra_rules_rev = {} | |||
| self.alias_js_code = {} | |||
| def _new_function(self, code): | |||
| name = 'alias_%d' % self._count | |||
| self._count += 1 | |||
| self.alias_js_code[name] = code | |||
| return name | |||
| def _extra_rule(self, rule): | |||
| if rule in self.extra_rules_rev: | |||
| return self.extra_rules_rev[rule] | |||
| name = 'xrule_%d' % len(self.extra_rules) | |||
| assert name not in self.extra_rules | |||
| self.extra_rules[name] = rule | |||
| self.extra_rules_rev[rule] = name | |||
| return name | |||
| def rule(self, name): | |||
| return _get_rulename(name) | |||
| def ruledef(self, name, exps): | |||
| return '!%s: %s' % (_get_rulename(name), exps) | |||
| def expr(self, item, op): | |||
| rule = '(%s)%s' % (item, op) | |||
| return self._extra_rule(rule) | |||
| def regexp(self, r): | |||
| return '/%s/' % r | |||
| def null(self): | |||
| return '' | |||
| def string(self, s): | |||
| return self._extra_rule(s) | |||
| def expansion(self, *x): | |||
| x, js = x[:-1], x[-1] | |||
| if js.children: | |||
| js_code ,= js.children | |||
| js_code = js_code[2:-2] | |||
| alias = '-> ' + self._new_function(js_code) | |||
| else: | |||
| alias = '' | |||
| return ' '.join(x) + alias | |||
| def expansions(self, *x): | |||
| return '%s' % ('\n |'.join(x)) | |||
| def start(self, *rules): | |||
| return '\n'.join(filter(None, rules)) | |||
| def _nearley_to_lark(g, builtin_path, n2l, js_code, folder_path, includes): | |||
| rule_defs = [] | |||
| tree = nearley_grammar_parser.parse(g) | |||
| for statement in tree.children: | |||
| if statement.data == 'directive': | |||
| directive, arg = statement.children | |||
| if directive in ('builtin', 'include'): | |||
| folder = builtin_path if directive == 'builtin' else folder_path | |||
| path = os.path.join(folder, arg[1:-1]) | |||
| if path not in includes: | |||
| includes.add(path) | |||
| with codecs.open(path, encoding='utf8') as f: | |||
| text = f.read() | |||
| rule_defs += _nearley_to_lark(text, builtin_path, n2l, js_code, os.path.abspath(os.path.dirname(path)), includes) | |||
| else: | |||
| assert False, directive | |||
| elif statement.data == 'js_code': | |||
| code ,= statement.children | |||
| code = code[2:-2] | |||
| js_code.append(code) | |||
| elif statement.data == 'macro': | |||
| pass # TODO Add support for macros! | |||
| elif statement.data == 'ruledef': | |||
| rule_defs.append( n2l.transform(statement) ) | |||
| else: | |||
| raise Exception("Unknown statement: %s" % statement) | |||
| return rule_defs | |||
| def create_code_for_nearley_grammar(g, start, builtin_path, folder_path): | |||
| import js2py | |||
| emit_code = [] | |||
| def emit(x=None): | |||
| if x: | |||
| emit_code.append(x) | |||
| emit_code.append('\n') | |||
| js_code = ['function id(x) {return x[0];}'] | |||
| n2l = NearleyToLark() | |||
| rule_defs = _nearley_to_lark(g, builtin_path, n2l, js_code, folder_path, set()) | |||
| lark_g = '\n'.join(rule_defs) | |||
| lark_g += '\n'+'\n'.join('!%s: %s' % item for item in n2l.extra_rules.items()) | |||
| emit('from lark import Lark, Transformer') | |||
| emit() | |||
| emit('grammar = ' + repr(lark_g)) | |||
| emit() | |||
| for alias, code in n2l.alias_js_code.items(): | |||
| js_code.append('%s = (%s);' % (alias, code)) | |||
| emit(js2py.translate_js('\n'.join(js_code))) | |||
| emit('class TransformNearley(Transformer):') | |||
| for alias in n2l.alias_js_code: | |||
| emit(" %s = var.get('%s').to_python()" % (alias, alias)) | |||
| emit(" __default__ = lambda self, n, c, m: c if c else None") | |||
| emit() | |||
| emit('parser = Lark(grammar, start="n_%s")' % start) | |||
| emit('def parse(text):') | |||
| emit(' return TransformNearley().transform(parser.parse(text))') | |||
| return ''.join(emit_code) | |||
| def main(fn, start, nearley_lib): | |||
| with codecs.open(fn, encoding='utf8') as f: | |||
| grammar = f.read() | |||
| return create_code_for_nearley_grammar(grammar, start, os.path.join(nearley_lib, 'builtin'), os.path.abspath(os.path.dirname(fn))) | |||
| if __name__ == '__main__': | |||
| if len(sys.argv) < 4: | |||
| print("Reads Nearley grammar (with js functions) outputs an equivalent lark parser.") | |||
| print("Usage: %s <nearley_grammar_path> <start_rule> <nearley_lib_path>" % sys.argv[0]) | |||
| sys.exit(1) | |||
| fn, start, nearley_lib = sys.argv[1:] | |||
| print(main(fn, start, nearley_lib)) | |||
+ 39
- 0
lark/tools/serialize.py
View File
| @@ -0,0 +1,39 @@ | |||
| import codecs | |||
| import sys | |||
| import json | |||
| from lark import Lark | |||
| from lark.grammar import RuleOptions, Rule | |||
| from lark.lexer import TerminalDef | |||
| import argparse | |||
| argparser = argparse.ArgumentParser(prog='python -m lark.tools.serialize') #description='''Lark Serialization Tool -- Stores Lark's internal state & LALR analysis as a convenient JSON file''') | |||
| argparser.add_argument('grammar_file', type=argparse.FileType('r'), help='A valid .lark file') | |||
| argparser.add_argument('-o', '--out', type=argparse.FileType('w'), default=sys.stdout, help='json file path to create (default=stdout)') | |||
| argparser.add_argument('-s', '--start', default='start', help='start symbol (default="start")', nargs='+') | |||
| argparser.add_argument('-l', '--lexer', default='standard', choices=['standard', 'contextual'], help='lexer type (default="standard")') | |||
| def serialize(infile, outfile, lexer, start): | |||
| lark_inst = Lark(infile, parser="lalr", lexer=lexer, start=start) # TODO contextual | |||
| data, memo = lark_inst.memo_serialize([TerminalDef, Rule]) | |||
| outfile.write('{\n') | |||
| outfile.write(' "data": %s,\n' % json.dumps(data)) | |||
| outfile.write(' "memo": %s\n' % json.dumps(memo)) | |||
| outfile.write('}\n') | |||
| def main(): | |||
| if len(sys.argv) == 1 or '-h' in sys.argv or '--help' in sys.argv: | |||
| print("Lark Serialization Tool - Stores Lark's internal state & LALR analysis as a JSON file") | |||
| print("") | |||
| argparser.print_help() | |||
| else: | |||
| args = argparser.parse_args() | |||
| serialize(args.grammar_file, args.out, args.lexer, args.start) | |||
| if __name__ == '__main__': | |||
| main() | |||
+ 137
- 0
lark/tools/standalone.py
View File
| @@ -0,0 +1,137 @@ | |||
| ###{standalone | |||
| # | |||
| # | |||
| # Lark Stand-alone Generator Tool | |||
| # ---------------------------------- | |||
| # Generates a stand-alone LALR(1) parser with a standard lexer | |||
| # | |||
| # Git: https://github.com/erezsh/lark | |||
| # Author: Erez Shinan (erezshin@gmail.com) | |||
| # | |||
| # | |||
| # >>> LICENSE | |||
| # | |||
| # This tool and its generated code use a separate license from Lark. | |||
| # | |||
| # It is licensed under GPLv2 or above. | |||
| # | |||
| # If you wish to purchase a commercial license for this tool and its | |||
| # generated code, contact me via email. | |||
| # | |||
| # If GPL is incompatible with your free or open-source project, | |||
| # contact me and we'll work it out (for free). | |||
| # | |||
| # This program is free software: you can redistribute it and/or modify | |||
| # it under the terms of the GNU General Public License as published by | |||
| # the Free Software Foundation, either version 2 of the License, or | |||
| # (at your option) any later version. | |||
| # | |||
| # This program is distributed in the hope that it will be useful, | |||
| # but WITHOUT ANY WARRANTY; without even the implied warranty of | |||
| # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the | |||
| # GNU General Public License for more details. | |||
| # | |||
| # See <http://www.gnu.org/licenses/>. | |||
| # | |||
| # | |||
| ###} | |||
| import pprint | |||
| import codecs | |||
| import sys | |||
| import os | |||
| from pprint import pprint | |||
| from os import path | |||
| from collections import defaultdict | |||
| import lark | |||
| from lark import Lark | |||
| from lark.parsers.lalr_analysis import Reduce | |||
| from lark.grammar import RuleOptions, Rule | |||
| from lark.lexer import TerminalDef | |||
| _dir = path.dirname(__file__) | |||
| _larkdir = path.join(_dir, path.pardir) | |||
| EXTRACT_STANDALONE_FILES = [ | |||
| 'tools/standalone.py', | |||
| 'exceptions.py', | |||
| 'utils.py', | |||
| 'tree.py', | |||
| 'visitors.py', | |||
| 'indenter.py', | |||
| 'grammar.py', | |||
| 'lexer.py', | |||
| 'common.py', | |||
| 'parse_tree_builder.py', | |||
| 'parsers/lalr_parser.py', | |||
| 'parsers/lalr_analysis.py', | |||
| 'parser_frontends.py', | |||
| 'lark.py', | |||
| ] | |||
| def extract_sections(lines): | |||
| section = None | |||
| text = [] | |||
| sections = defaultdict(list) | |||
| for l in lines: | |||
| if l.startswith('###'): | |||
| if l[3] == '{': | |||
| section = l[4:].strip() | |||
| elif l[3] == '}': | |||
| sections[section] += text | |||
| section = None | |||
| text = [] | |||
| else: | |||
| raise ValueError(l) | |||
| elif section: | |||
| text.append(l) | |||
| return {name:''.join(text) for name, text in sections.items()} | |||
| def main(fobj, start): | |||
| lark_inst = Lark(fobj, parser="lalr", lexer="contextual", start=start) | |||
| print('# The file was automatically generated by Lark v%s' % lark.__version__) | |||
| for pyfile in EXTRACT_STANDALONE_FILES: | |||
| with open(os.path.join(_larkdir, pyfile)) as f: | |||
| print (extract_sections(f)['standalone']) | |||
| data, m = lark_inst.memo_serialize([TerminalDef, Rule]) | |||
| print( 'DATA = (' ) | |||
| # pprint(data, width=160) | |||
| print(data) | |||
| print(')') | |||
| print( 'MEMO = (') | |||
| print(m) | |||
| print(')') | |||
| print('Shift = 0') | |||
| print('Reduce = 1') | |||
| print("def Lark_StandAlone(transformer=None, postlex=None):") | |||
| print(" namespace = {'Rule': Rule, 'TerminalDef': TerminalDef}") | |||
| print(" return Lark.deserialize(DATA, namespace, MEMO, transformer=transformer, postlex=postlex)") | |||
| if __name__ == '__main__': | |||
| if len(sys.argv) < 2: | |||
| print("Lark Stand-alone Generator Tool") | |||
| print("Usage: python -m lark.tools.standalone <grammar-file> [<start>]") | |||
| sys.exit(1) | |||
| if len(sys.argv) == 3: | |||
| fn, start = sys.argv[1:] | |||
| elif len(sys.argv) == 2: | |||
| fn, start = sys.argv[1], 'start' | |||
| else: | |||
| assert False, sys.argv | |||
| with codecs.open(fn, encoding='utf8') as f: | |||
| main(f, start) | |||
+ 183
- 0
lark/tree.py
View File
| @@ -0,0 +1,183 @@ | |||
| try: | |||
| from future_builtins import filter | |||
| except ImportError: | |||
| pass | |||
| from copy import deepcopy | |||
| ###{standalone | |||
| class Meta: | |||
| def __init__(self): | |||
| self.empty = True | |||
| class Tree(object): | |||
| def __init__(self, data, children, meta=None): | |||
| self.data = data | |||
| self.children = children | |||
| self._meta = meta | |||
| @property | |||
| def meta(self): | |||
| if self._meta is None: | |||
| self._meta = Meta() | |||
| return self._meta | |||
| def __repr__(self): | |||
| return 'Tree(%s, %s)' % (self.data, self.children) | |||
| def _pretty_label(self): | |||
| return self.data | |||
| def _pretty(self, level, indent_str): | |||
| if len(self.children) == 1 and not isinstance(self.children[0], Tree): | |||
| return [ indent_str*level, self._pretty_label(), '\t', '%s' % (self.children[0],), '\n'] | |||
| l = [ indent_str*level, self._pretty_label(), '\n' ] | |||
| for n in self.children: | |||
| if isinstance(n, Tree): | |||
| l += n._pretty(level+1, indent_str) | |||
| else: | |||
| l += [ indent_str*(level+1), '%s' % (n,), '\n' ] | |||
| return l | |||
| def pretty(self, indent_str=' '): | |||
| return ''.join(self._pretty(0, indent_str)) | |||
| def __eq__(self, other): | |||
| try: | |||
| return self.data == other.data and self.children == other.children | |||
| except AttributeError: | |||
| return False | |||
| def __ne__(self, other): | |||
| return not (self == other) | |||
| def __hash__(self): | |||
| return hash((self.data, tuple(self.children))) | |||
| ###} | |||
| def expand_kids_by_index(self, *indices): | |||
| "Expand (inline) children at the given indices" | |||
| for i in sorted(indices, reverse=True): # reverse so that changing tail won't affect indices | |||
| kid = self.children[i] | |||
| self.children[i:i+1] = kid.children | |||
| def find_pred(self, pred): | |||
| "Find all nodes where pred(tree) == True" | |||
| return filter(pred, self.iter_subtrees()) | |||
| def find_data(self, data): | |||
| "Find all nodes where tree.data == data" | |||
| return self.find_pred(lambda t: t.data == data) | |||
| def scan_values(self, pred): | |||
| for c in self.children: | |||
| if isinstance(c, Tree): | |||
| for t in c.scan_values(pred): | |||
| yield t | |||
| else: | |||
| if pred(c): | |||
| yield c | |||
| def iter_subtrees(self): | |||
| # TODO: Re-write as a more efficient version | |||
| visited = set() | |||
| q = [self] | |||
| l = [] | |||
| while q: | |||
| subtree = q.pop() | |||
| l.append( subtree ) | |||
| if id(subtree) in visited: | |||
| continue # already been here from another branch | |||
| visited.add(id(subtree)) | |||
| q += [c for c in subtree.children if isinstance(c, Tree)] | |||
| seen = set() | |||
| for x in reversed(l): | |||
| if id(x) not in seen: | |||
| yield x | |||
| seen.add(id(x)) | |||
| def iter_subtrees_topdown(self): | |||
| stack = [self] | |||
| while stack: | |||
| node = stack.pop() | |||
| if not isinstance(node, Tree): | |||
| continue | |||
| yield node | |||
| for n in reversed(node.children): | |||
| stack.append(n) | |||
| def __deepcopy__(self, memo): | |||
| return type(self)(self.data, deepcopy(self.children, memo)) | |||
| def copy(self): | |||
| return type(self)(self.data, self.children) | |||
| def set(self, data, children): | |||
| self.data = data | |||
| self.children = children | |||
| # XXX Deprecated! Here for backwards compatibility <0.6.0 | |||
| @property | |||
| def line(self): | |||
| return self.meta.line | |||
| @property | |||
| def column(self): | |||
| return self.meta.column | |||
| @property | |||
| def end_line(self): | |||
| return self.meta.end_line | |||
| @property | |||
| def end_column(self): | |||
| return self.meta.end_column | |||
| class SlottedTree(Tree): | |||
| __slots__ = 'data', 'children', 'rule', '_meta' | |||
| def pydot__tree_to_png(tree, filename, rankdir="LR", **kwargs): | |||
| """Creates a colorful image that represents the tree (data+children, without meta) | |||
| Possible values for `rankdir` are "TB", "LR", "BT", "RL", corresponding to | |||
| directed graphs drawn from top to bottom, from left to right, from bottom to | |||
| top, and from right to left, respectively. | |||
| `kwargs` can be any graph attribute (e. g. `dpi=200`). For a list of | |||
| possible attributes, see https://www.graphviz.org/doc/info/attrs.html. | |||
| """ | |||
| import pydot | |||
| graph = pydot.Dot(graph_type='digraph', rankdir=rankdir, **kwargs) | |||
| i = [0] | |||
| def new_leaf(leaf): | |||
| node = pydot.Node(i[0], label=repr(leaf)) | |||
| i[0] += 1 | |||
| graph.add_node(node) | |||
| return node | |||
| def _to_pydot(subtree): | |||
| color = hash(subtree.data) & 0xffffff | |||
| color |= 0x808080 | |||
| subnodes = [_to_pydot(child) if isinstance(child, Tree) else new_leaf(child) | |||
| for child in subtree.children] | |||
| node = pydot.Node(i[0], style="filled", fillcolor="#%x"%color, label=subtree.data) | |||
| i[0] += 1 | |||
| graph.add_node(node) | |||
| for subnode in subnodes: | |||
| graph.add_edge(pydot.Edge(node, subnode)) | |||
| return node | |||
| _to_pydot(tree) | |||
| graph.write_png(filename) | |||
+ 241
- 0
lark/utils.py
View File
| @@ -0,0 +1,241 @@ | |||
| import sys | |||
| from collections import deque | |||
| class fzset(frozenset): | |||
| def __repr__(self): | |||
| return '{%s}' % ', '.join(map(repr, self)) | |||
| def classify_bool(seq, pred): | |||
| true_elems = [] | |||
| false_elems = [] | |||
| for elem in seq: | |||
| if pred(elem): | |||
| true_elems.append(elem) | |||
| else: | |||
| false_elems.append(elem) | |||
| return true_elems, false_elems | |||
| def bfs(initial, expand): | |||
| open_q = deque(list(initial)) | |||
| visited = set(open_q) | |||
| while open_q: | |||
| node = open_q.popleft() | |||
| yield node | |||
| for next_node in expand(node): | |||
| if next_node not in visited: | |||
| visited.add(next_node) | |||
| open_q.append(next_node) | |||
| def _serialize(value, memo): | |||
| # if memo and memo.in_types(value): | |||
| # return {'__memo__': memo.memoized.get(value)} | |||
| if isinstance(value, Serialize): | |||
| return value.serialize(memo) | |||
| elif isinstance(value, list): | |||
| return [_serialize(elem, memo) for elem in value] | |||
| elif isinstance(value, frozenset): | |||
| return list(value) # TODO reversible? | |||
| elif isinstance(value, dict): | |||
| return {key:_serialize(elem, memo) for key, elem in value.items()} | |||
| return value | |||
| ###{standalone | |||
| def classify(seq, key=None, value=None): | |||
| d = {} | |||
| for item in seq: | |||
| k = key(item) if (key is not None) else item | |||
| v = value(item) if (value is not None) else item | |||
| if k in d: | |||
| d[k].append(v) | |||
| else: | |||
| d[k] = [v] | |||
| return d | |||
| def _deserialize(data, namespace, memo): | |||
| if isinstance(data, dict): | |||
| if '__type__' in data: # Object | |||
| class_ = namespace[data['__type__']] | |||
| return class_.deserialize(data, memo) | |||
| elif '@' in data: | |||
| return memo[data['@']] | |||
| return {key:_deserialize(value, namespace, memo) for key, value in data.items()} | |||
| elif isinstance(data, list): | |||
| return [_deserialize(value, namespace, memo) for value in data] | |||
| return data | |||
| class Serialize(object): | |||
| def memo_serialize(self, types_to_memoize): | |||
| memo = SerializeMemoizer(types_to_memoize) | |||
| return self.serialize(memo), memo.serialize() | |||
| def serialize(self, memo=None): | |||
| if memo and memo.in_types(self): | |||
| return {'@': memo.memoized.get(self)} | |||
| fields = getattr(self, '__serialize_fields__') | |||
| res = {f: _serialize(getattr(self, f), memo) for f in fields} | |||
| res['__type__'] = type(self).__name__ | |||
| postprocess = getattr(self, '_serialize', None) | |||
| if postprocess: | |||
| postprocess(res, memo) | |||
| return res | |||
| @classmethod | |||
| def deserialize(cls, data, memo): | |||
| namespace = getattr(cls, '__serialize_namespace__', {}) | |||
| namespace = {c.__name__:c for c in namespace} | |||
| fields = getattr(cls, '__serialize_fields__') | |||
| if '@' in data: | |||
| return memo[data['@']] | |||
| inst = cls.__new__(cls) | |||
| for f in fields: | |||
| try: | |||
| setattr(inst, f, _deserialize(data[f], namespace, memo)) | |||
| except KeyError as e: | |||
| raise KeyError("Cannot find key for class", cls, e) | |||
| postprocess = getattr(inst, '_deserialize', None) | |||
| if postprocess: | |||
| postprocess() | |||
| return inst | |||
| class SerializeMemoizer(Serialize): | |||
| __serialize_fields__ = 'memoized', | |||
| def __init__(self, types_to_memoize): | |||
| self.types_to_memoize = tuple(types_to_memoize) | |||
| self.memoized = Enumerator() | |||
| def in_types(self, value): | |||
| return isinstance(value, self.types_to_memoize) | |||
| def serialize(self): | |||
| return _serialize(self.memoized.reversed(), None) | |||
| @classmethod | |||
| def deserialize(cls, data, namespace, memo): | |||
| return _deserialize(data, namespace, memo) | |||
| try: | |||
| STRING_TYPE = basestring | |||
| except NameError: # Python 3 | |||
| STRING_TYPE = str | |||
| import types | |||
| from functools import wraps, partial | |||
| from contextlib import contextmanager | |||
| Str = type(u'') | |||
| try: | |||
| classtype = types.ClassType # Python2 | |||
| except AttributeError: | |||
| classtype = type # Python3 | |||
| def smart_decorator(f, create_decorator): | |||
| if isinstance(f, types.FunctionType): | |||
| return wraps(f)(create_decorator(f, True)) | |||
| elif isinstance(f, (classtype, type, types.BuiltinFunctionType)): | |||
| return wraps(f)(create_decorator(f, False)) | |||
| elif isinstance(f, types.MethodType): | |||
| return wraps(f)(create_decorator(f.__func__, True)) | |||
| elif isinstance(f, partial): | |||
| # wraps does not work for partials in 2.7: https://bugs.python.org/issue3445 | |||
| return wraps(f.func)(create_decorator(lambda *args, **kw: f(*args[1:], **kw), True)) | |||
| else: | |||
| return create_decorator(f.__func__.__call__, True) | |||
| import sys, re | |||
| Py36 = (sys.version_info[:2] >= (3, 6)) | |||
| import sre_parse | |||
| import sre_constants | |||
| def get_regexp_width(regexp): | |||
| try: | |||
| return sre_parse.parse(regexp).getwidth() | |||
| except sre_constants.error: | |||
| raise ValueError(regexp) | |||
| ###} | |||
| def dedup_list(l): | |||
| """Given a list (l) will removing duplicates from the list, | |||
| preserving the original order of the list. Assumes that | |||
| the list entrie are hashable.""" | |||
| dedup = set() | |||
| return [ x for x in l if not (x in dedup or dedup.add(x))] | |||
| try: | |||
| from contextlib import suppress # Python 3 | |||
| except ImportError: | |||
| @contextmanager | |||
| def suppress(*excs): | |||
| '''Catch and dismiss the provided exception | |||
| >>> x = 'hello' | |||
| >>> with suppress(IndexError): | |||
| ... x = x[10] | |||
| >>> x | |||
| 'hello' | |||
| ''' | |||
| try: | |||
| yield | |||
| except excs: | |||
| pass | |||
| try: | |||
| compare = cmp | |||
| except NameError: | |||
| def compare(a, b): | |||
| if a == b: | |||
| return 0 | |||
| elif a > b: | |||
| return 1 | |||
| return -1 | |||
| class Enumerator(Serialize): | |||
| def __init__(self): | |||
| self.enums = {} | |||
| def get(self, item): | |||
| if item not in self.enums: | |||
| self.enums[item] = len(self.enums) | |||
| return self.enums[item] | |||
| def __len__(self): | |||
| return len(self.enums) | |||
| def reversed(self): | |||
| r = {v: k for k, v in self.enums.items()} | |||
| assert len(r) == len(self.enums) | |||
| return r | |||
+ 273
- 0
lark/visitors.py
View File
| @@ -0,0 +1,273 @@ | |||
| from functools import wraps | |||
| from .utils import smart_decorator | |||
| from .tree import Tree | |||
| from .exceptions import VisitError, GrammarError | |||
| ###{standalone | |||
| from inspect import getmembers, getmro | |||
| class Discard(Exception): | |||
| pass | |||
| # Transformers | |||
| class Transformer: | |||
| """Visits the tree recursively, starting with the leaves and finally the root (bottom-up) | |||
| Calls its methods (provided by user via inheritance) according to tree.data | |||
| The returned value replaces the old one in the structure. | |||
| Can be used to implement map or reduce. | |||
| """ | |||
| def _call_userfunc(self, tree, new_children=None): | |||
| # Assumes tree is already transformed | |||
| children = new_children if new_children is not None else tree.children | |||
| try: | |||
| f = getattr(self, tree.data) | |||
| except AttributeError: | |||
| return self.__default__(tree.data, children, tree.meta) | |||
| else: | |||
| try: | |||
| if getattr(f, 'meta', False): | |||
| return f(children, tree.meta) | |||
| elif getattr(f, 'inline', False): | |||
| return f(*children) | |||
| elif getattr(f, 'whole_tree', False): | |||
| if new_children is not None: | |||
| tree.children = new_children | |||
| return f(tree) | |||
| else: | |||
| return f(children) | |||
| except (GrammarError, Discard): | |||
| raise | |||
| except Exception as e: | |||
| raise VisitError(tree, e) | |||
| def _transform_children(self, children): | |||
| for c in children: | |||
| try: | |||
| yield self._transform_tree(c) if isinstance(c, Tree) else c | |||
| except Discard: | |||
| pass | |||
| def _transform_tree(self, tree): | |||
| children = list(self._transform_children(tree.children)) | |||
| return self._call_userfunc(tree, children) | |||
| def transform(self, tree): | |||
| return self._transform_tree(tree) | |||
| def __mul__(self, other): | |||
| return TransformerChain(self, other) | |||
| def __default__(self, data, children, meta): | |||
| "Default operation on tree (for override)" | |||
| return Tree(data, children, meta) | |||
| @classmethod | |||
| def _apply_decorator(cls, decorator, **kwargs): | |||
| mro = getmro(cls) | |||
| assert mro[0] is cls | |||
| libmembers = {name for _cls in mro[1:] for name, _ in getmembers(_cls)} | |||
| for name, value in getmembers(cls): | |||
| # Make sure the function isn't inherited (unless it's overwritten) | |||
| if name.startswith('_') or (name in libmembers and name not in cls.__dict__): | |||
| continue | |||
| if not callable(cls.__dict__[name]): | |||
| continue | |||
| # Skip if v_args already applied (at the function level) | |||
| if hasattr(cls.__dict__[name], 'vargs_applied'): | |||
| continue | |||
| static = isinstance(cls.__dict__[name], (staticmethod, classmethod)) | |||
| setattr(cls, name, decorator(value, static=static, **kwargs)) | |||
| return cls | |||
| class InlineTransformer(Transformer): # XXX Deprecated | |||
| def _call_userfunc(self, tree, new_children=None): | |||
| # Assumes tree is already transformed | |||
| children = new_children if new_children is not None else tree.children | |||
| try: | |||
| f = getattr(self, tree.data) | |||
| except AttributeError: | |||
| return self.__default__(tree.data, children, tree.meta) | |||
| else: | |||
| return f(*children) | |||
| class TransformerChain(object): | |||
| def __init__(self, *transformers): | |||
| self.transformers = transformers | |||
| def transform(self, tree): | |||
| for t in self.transformers: | |||
| tree = t.transform(tree) | |||
| return tree | |||
| def __mul__(self, other): | |||
| return TransformerChain(*self.transformers + (other,)) | |||
| class Transformer_InPlace(Transformer): | |||
| "Non-recursive. Changes the tree in-place instead of returning new instances" | |||
| def _transform_tree(self, tree): # Cancel recursion | |||
| return self._call_userfunc(tree) | |||
| def transform(self, tree): | |||
| for subtree in tree.iter_subtrees(): | |||
| subtree.children = list(self._transform_children(subtree.children)) | |||
| return self._transform_tree(tree) | |||
| class Transformer_InPlaceRecursive(Transformer): | |||
| "Recursive. Changes the tree in-place instead of returning new instances" | |||
| def _transform_tree(self, tree): | |||
| tree.children = list(self._transform_children(tree.children)) | |||
| return self._call_userfunc(tree) | |||
| # Visitors | |||
| class VisitorBase: | |||
| def _call_userfunc(self, tree): | |||
| return getattr(self, tree.data, self.__default__)(tree) | |||
| def __default__(self, tree): | |||
| "Default operation on tree (for override)" | |||
| return tree | |||
| class Visitor(VisitorBase): | |||
| """Bottom-up visitor, non-recursive | |||
| Visits the tree, starting with the leaves and finally the root (bottom-up) | |||
| Calls its methods (provided by user via inheritance) according to tree.data | |||
| """ | |||
| def visit(self, tree): | |||
| for subtree in tree.iter_subtrees(): | |||
| self._call_userfunc(subtree) | |||
| return tree | |||
| class Visitor_Recursive(VisitorBase): | |||
| """Bottom-up visitor, recursive | |||
| Visits the tree, starting with the leaves and finally the root (bottom-up) | |||
| Calls its methods (provided by user via inheritance) according to tree.data | |||
| """ | |||
| def visit(self, tree): | |||
| for child in tree.children: | |||
| if isinstance(child, Tree): | |||
| self.visit(child) | |||
| f = getattr(self, tree.data, self.__default__) | |||
| f(tree) | |||
| return tree | |||
| def visit_children_decor(func): | |||
| "See Interpreter" | |||
| @wraps(func) | |||
| def inner(cls, tree): | |||
| values = cls.visit_children(tree) | |||
| return func(cls, values) | |||
| return inner | |||
| class Interpreter: | |||
| """Top-down visitor, recursive | |||
| Visits the tree, starting with the root and finally the leaves (top-down) | |||
| Calls its methods (provided by user via inheritance) according to tree.data | |||
| Unlike Transformer and Visitor, the Interpreter doesn't automatically visit its sub-branches. | |||
| The user has to explicitly call visit_children, or use the @visit_children_decor | |||
| """ | |||
| def visit(self, tree): | |||
| return getattr(self, tree.data)(tree) | |||
| def visit_children(self, tree): | |||
| return [self.visit(child) if isinstance(child, Tree) else child | |||
| for child in tree.children] | |||
| def __getattr__(self, name): | |||
| return self.__default__ | |||
| def __default__(self, tree): | |||
| return self.visit_children(tree) | |||
| # Decorators | |||
| def _apply_decorator(obj, decorator, **kwargs): | |||
| try: | |||
| _apply = obj._apply_decorator | |||
| except AttributeError: | |||
| return decorator(obj, **kwargs) | |||
| else: | |||
| return _apply(decorator, **kwargs) | |||
| def _inline_args__func(func): | |||
| @wraps(func) | |||
| def create_decorator(_f, with_self): | |||
| if with_self: | |||
| def f(self, children): | |||
| return _f(self, *children) | |||
| else: | |||
| def f(self, children): | |||
| return _f(*children) | |||
| return f | |||
| return smart_decorator(func, create_decorator) | |||
| def inline_args(obj): # XXX Deprecated | |||
| return _apply_decorator(obj, _inline_args__func) | |||
| def _visitor_args_func_dec(func, inline=False, meta=False, whole_tree=False, static=False): | |||
| assert [whole_tree, meta, inline].count(True) <= 1 | |||
| def create_decorator(_f, with_self): | |||
| if with_self: | |||
| def f(self, *args, **kwargs): | |||
| return _f(self, *args, **kwargs) | |||
| else: | |||
| def f(self, *args, **kwargs): | |||
| return _f(*args, **kwargs) | |||
| return f | |||
| if static: | |||
| f = wraps(func)(create_decorator(func, False)) | |||
| else: | |||
| f = smart_decorator(func, create_decorator) | |||
| f.vargs_applied = True | |||
| f.inline = inline | |||
| f.meta = meta | |||
| f.whole_tree = whole_tree | |||
| return f | |||
| def v_args(inline=False, meta=False, tree=False): | |||
| "A convenience decorator factory, for modifying the behavior of user-supplied visitor methods" | |||
| if [tree, meta, inline].count(True) > 1: | |||
| raise ValueError("Visitor functions can either accept tree, or meta, or be inlined. These cannot be combined.") | |||
| def _visitor_args_dec(obj): | |||
| return _apply_decorator(obj, _visitor_args_func_dec, inline=inline, meta=meta, whole_tree=tree) | |||
| return _visitor_args_dec | |||
| ###} | |||
+ 13
- 0
mkdocs.yml
View File
| @@ -0,0 +1,13 @@ | |||
| site_name: Lark | |||
| theme: readthedocs | |||
| pages: | |||
| - Main Page: index.md | |||
| - Philosophy: philosophy.md | |||
| - Features: features.md | |||
| - Parsers: parsers.md | |||
| - How To Use (Guide): how_to_use.md | |||
| - How To Develop (Guide): how_to_develop.md | |||
| - Grammar Reference: grammar.md | |||
| - Tree Construction Reference: tree_construction.md | |||
| - Classes Reference: classes.md | |||
| - Recipes: recipes.md | |||
+ 1
- 0
nearley-requirements.txt
View File
| @@ -0,0 +1 @@ | |||
| Js2Py==0.50 | |||
+ 10
- 0
readthedocs.yml
View File
| @@ -0,0 +1,10 @@ | |||
| version: 2 | |||
| mkdocs: | |||
| configuration: mkdocs.yml | |||
| fail_on_warning: false | |||
| formats: all | |||
| python: | |||
| version: 3.5 | |||
+ 0
- 35
reponames.py
View File
| @@ -1,35 +0,0 @@ | |||
| import re | |||
| import sys | |||
| import unittest | |||
| # man git-check-ref-format | |||
| reponameregex = re.compile(r'^(https://(?P<domain>github\.com)/(?P<slashpath>.*)\.git$)') | |||
| def doconvert(i): | |||
| mat = reponameregex.match(i) | |||
| gd = mat.groupdict() | |||
| p = gd['slashpath'].replace('/', '-') | |||
| return '%s--%s' % (gd['domain'], p) | |||
| if __name__ == '__main__': | |||
| for i in sys.stdin: | |||
| i = i.strip() | |||
| if not i or i.startswith('#'): | |||
| continue | |||
| print(i, doconvert(i)) | |||
| class _TestCases(unittest.TestCase): | |||
| def test_foo(self): | |||
| data = [ | |||
| ('https://github.com/python/cpython.git', 'github.com--python-cpython'), | |||
| ] | |||
| for i in data: | |||
| r = doconvert(i[0]) | |||
| self.assertEqual(r, i[1], msg='%s resulting in %s, should have been %s' % tuple(repr(x) for x in (i[0], r, i[1]))) | |||
+ 0
- 2
repos.txt
View File
| @@ -1,2 +0,0 @@ | |||
| #https://github.com/python/cpython.git | |||
| https://github.com/lark-parser/lark.git | |||
+ 10
- 0
setup.cfg
View File
| @@ -0,0 +1,10 @@ | |||
| [global] | |||
| zip_safe= | |||
| [bdist_wheel] | |||
| universal = 1 | |||
| [metadata] | |||
| description-file = README.md | |||
| license_file = LICENSE | |||
+ 62
- 0
setup.py
View File
| @@ -0,0 +1,62 @@ | |||
| import re | |||
| from setuptools import setup | |||
| __version__ ,= re.findall('__version__ = "(.*)"', open('lark/__init__.py').read()) | |||
| setup( | |||
| name = "lark-parser", | |||
| version = __version__, | |||
| packages = ['lark', 'lark.parsers', 'lark.tools', 'lark.grammars'], | |||
| requires = [], | |||
| install_requires = [], | |||
| package_data = { '': ['*.md', '*.lark'] }, | |||
| test_suite = 'tests.__main__', | |||
| # metadata for upload to PyPI | |||
| author = "Erez Shinan", | |||
| author_email = "erezshin@gmail.com", | |||
| description = "a modern parsing library", | |||
| license = "MIT", | |||
| keywords = "Earley LALR parser parsing ast", | |||
| url = "https://github.com/erezsh/lark", | |||
| download_url = "https://github.com/erezsh/lark/tarball/master", | |||
| long_description=''' | |||
| Lark is a modern general-purpose parsing library for Python. | |||
| With Lark, you can parse any context-free grammar, efficiently, with very little code. | |||
| Main Features: | |||
| - Builds a parse-tree (AST) automagically, based on the structure of the grammar | |||
| - Earley parser | |||
| - Can parse all context-free grammars | |||
| - Full support for ambiguous grammars | |||
| - LALR(1) parser | |||
| - Fast and light, competitive with PLY | |||
| - Can generate a stand-alone parser | |||
| - CYK parser, for highly ambiguous grammars | |||
| - EBNF grammar | |||
| - Unicode fully supported | |||
| - Python 2 & 3 compatible | |||
| - Automatic line & column tracking | |||
| - Standard library of terminals (strings, numbers, names, etc.) | |||
| - Import grammars from Nearley.js | |||
| - Extensive test suite | |||
| - And much more! | |||
| ''', | |||
| classifiers=[ | |||
| "Development Status :: 5 - Production/Stable", | |||
| "Intended Audience :: Developers", | |||
| "Programming Language :: Python :: 2.7", | |||
| "Programming Language :: Python :: 3", | |||
| "Topic :: Software Development :: Libraries :: Python Modules", | |||
| "Topic :: Text Processing :: General", | |||
| "Topic :: Text Processing :: Linguistic", | |||
| "License :: OSI Approved :: MIT License", | |||
| ], | |||
| ) | |||
+ 0
- 0
tests/__init__.py
View File
+ 36
- 0
tests/__main__.py
View File
| @@ -0,0 +1,36 @@ | |||
| from __future__ import absolute_import, print_function | |||
| import unittest | |||
| import logging | |||
| from .test_trees import TestTrees | |||
| from .test_tools import TestStandalone | |||
| from .test_reconstructor import TestReconstructor | |||
| try: | |||
| from .test_nearley.test_nearley import TestNearley | |||
| except ImportError: | |||
| pass | |||
| # from .test_selectors import TestSelectors | |||
| # from .test_grammars import TestPythonG, TestConfigG | |||
| from .test_parser import ( | |||
| TestLalrStandard, | |||
| TestEarleyStandard, | |||
| TestCykStandard, | |||
| TestLalrContextual, | |||
| TestEarleyDynamic, | |||
| TestLalrCustom, | |||
| # TestFullEarleyStandard, | |||
| TestFullEarleyDynamic, | |||
| TestFullEarleyDynamic_complete, | |||
| TestParsers, | |||
| ) | |||
| logging.basicConfig(level=logging.INFO) | |||
| if __name__ == '__main__': | |||
| unittest.main() | |||
+ 10
- 0
tests/grammars/ab.lark
View File
| @@ -0,0 +1,10 @@ | |||
| startab: expr | |||
| expr: A B | |||
| | A expr B | |||
| A: "a" | |||
| B: "b" | |||
| %import common.WS | |||
| %ignore WS | |||
+ 6
- 0
tests/grammars/leading_underscore_grammar.lark
View File
| @@ -0,0 +1,6 @@ | |||
| A: "A" | |||
| _SEP: "x" | |||
| _a: A | |||
| c: _a _SEP | |||
+ 3
- 0
tests/grammars/test.lark
View File
| @@ -0,0 +1,3 @@ | |||
| %import common.NUMBER | |||
| %import common.WORD | |||
| %import common.WS | |||
+ 4
- 0
tests/grammars/test_relative_import_of_nested_grammar.lark
View File
| @@ -0,0 +1,4 @@ | |||
| start: rule_to_import | |||
| %import .test_relative_import_of_nested_grammar__grammar_to_import.rule_to_import | |||
+ 4
- 0
tests/grammars/test_relative_import_of_nested_grammar__grammar_to_import.lark
View File
| @@ -0,0 +1,4 @@ | |||
| rule_to_import: NESTED_TERMINAL | |||
| %import .test_relative_import_of_nested_grammar__nested_grammar.NESTED_TERMINAL | |||
+ 1
- 0
tests/grammars/test_relative_import_of_nested_grammar__nested_grammar.lark
View File
| @@ -0,0 +1 @@ | |||
| NESTED_TERMINAL: "N" | |||
+ 7
- 0
tests/grammars/three_rules_using_same_token.lark
View File
| @@ -0,0 +1,7 @@ | |||
| %import common.INT | |||
| a: A | |||
| b: A | |||
| c: A | |||
| A: "A" | |||
+ 0
- 0
tests/test_nearley/__init__.py
View File
+ 3
- 0
tests/test_nearley/grammars/include_unicode.ne
View File
| @@ -0,0 +1,3 @@ | |||
| @include "unicode.ne" | |||
| main -> x | |||
+ 1
- 0
tests/test_nearley/grammars/unicode.ne
View File
| @@ -0,0 +1 @@ | |||
| x -> "±a" | |||
+ 1
- 0
tests/test_nearley/nearley
| @@ -0,0 +1 @@ | |||
| Subproject commit a46b37471db486db0f6e1ce6a2934fb238346b44 | |||
+ 105
- 0
tests/test_nearley/test_nearley.py
View File
| @@ -0,0 +1,105 @@ | |||
| # -*- coding: utf-8 -*- | |||
| from __future__ import absolute_import | |||
| import unittest | |||
| import logging | |||
| import os | |||
| import codecs | |||
| logging.basicConfig(level=logging.INFO) | |||
| from lark.tools.nearley import create_code_for_nearley_grammar, main as nearley_tool_main | |||
| TEST_PATH = os.path.abspath(os.path.dirname(__file__)) | |||
| NEARLEY_PATH = os.path.join(TEST_PATH, 'nearley') | |||
| BUILTIN_PATH = os.path.join(NEARLEY_PATH, 'builtin') | |||
| if not os.path.exists(NEARLEY_PATH): | |||
| print("Skipping Nearley tests!") | |||
| raise ImportError("Skipping Nearley tests!") | |||
| class TestNearley(unittest.TestCase): | |||
| def test_css(self): | |||
| fn = os.path.join(NEARLEY_PATH, 'examples/csscolor.ne') | |||
| with open(fn) as f: | |||
| grammar = f.read() | |||
| code = create_code_for_nearley_grammar(grammar, 'csscolor', BUILTIN_PATH, os.path.dirname(fn)) | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| c = parse('#a199ff') | |||
| assert c['r'] == 161 | |||
| assert c['g'] == 153 | |||
| assert c['b'] == 255 | |||
| c = parse('rgb(255, 70%, 3)') | |||
| assert c['r'] == 255 | |||
| assert c['g'] == 178 | |||
| assert c['b'] == 3 | |||
| def test_include(self): | |||
| fn = os.path.join(NEARLEY_PATH, 'test/grammars/folder-test.ne') | |||
| with open(fn) as f: | |||
| grammar = f.read() | |||
| code = create_code_for_nearley_grammar(grammar, 'main', BUILTIN_PATH, os.path.dirname(fn)) | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| parse('a') | |||
| parse('b') | |||
| def test_multi_include(self): | |||
| fn = os.path.join(NEARLEY_PATH, 'test/grammars/multi-include-test.ne') | |||
| with open(fn) as f: | |||
| grammar = f.read() | |||
| code = create_code_for_nearley_grammar(grammar, 'main', BUILTIN_PATH, os.path.dirname(fn)) | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| parse('a') | |||
| parse('b') | |||
| parse('c') | |||
| def test_utf8(self): | |||
| grammar = u'main -> "±a"' | |||
| code = create_code_for_nearley_grammar(grammar, 'main', BUILTIN_PATH, './') | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| parse(u'±a') | |||
| def test_backslash(self): | |||
| grammar = r'main -> "\""' | |||
| code = create_code_for_nearley_grammar(grammar, 'main', BUILTIN_PATH, './') | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| parse(u'"') | |||
| def test_null(self): | |||
| grammar = r'main -> "a" | null' | |||
| code = create_code_for_nearley_grammar(grammar, 'main', BUILTIN_PATH, './') | |||
| d = {} | |||
| exec (code, d) | |||
| parse = d['parse'] | |||
| parse('a') | |||
| parse('') | |||
| def test_utf8_2(self): | |||
| fn = os.path.join(TEST_PATH, 'grammars/unicode.ne') | |||
| nearley_tool_main(fn, 'x', NEARLEY_PATH) | |||
| def test_include_utf8(self): | |||
| fn = os.path.join(TEST_PATH, 'grammars/include_unicode.ne') | |||
| nearley_tool_main(fn, 'main', NEARLEY_PATH) | |||
| if __name__ == '__main__': | |||
| unittest.main() | |||
+ 1618
- 0
tests/test_parser.py
File diff suppressed because it is too large
View File
+ 116
- 0
tests/test_reconstructor.py
View File
| @@ -0,0 +1,116 @@ | |||
| import json | |||
| import unittest | |||
| from unittest import TestCase | |||
| from lark import Lark | |||
| from lark.reconstruct import Reconstructor | |||
| common = """ | |||
| %import common (WS_INLINE, NUMBER, WORD) | |||
| %ignore WS_INLINE | |||
| """ | |||
| def _remove_ws(s): | |||
| return s.replace(' ', '').replace('\n','') | |||
| class TestReconstructor(TestCase): | |||
| def assert_reconstruct(self, grammar, code): | |||
| parser = Lark(grammar, parser='lalr') | |||
| tree = parser.parse(code) | |||
| new = Reconstructor(parser).reconstruct(tree) | |||
| self.assertEqual(_remove_ws(code), _remove_ws(new)) | |||
| def test_starred_rule(self): | |||
| g = """ | |||
| start: item* | |||
| item: NL | |||
| | rule | |||
| rule: WORD ":" NUMBER | |||
| NL: /(\\r?\\n)+\\s*/ | |||
| """ + common | |||
| code = """ | |||
| Elephants: 12 | |||
| """ | |||
| self.assert_reconstruct(g, code) | |||
| def test_starred_group(self): | |||
| g = """ | |||
| start: (rule | NL)* | |||
| rule: WORD ":" NUMBER | |||
| NL: /(\\r?\\n)+\\s*/ | |||
| """ + common | |||
| code = """ | |||
| Elephants: 12 | |||
| """ | |||
| self.assert_reconstruct(g, code) | |||
| def test_alias(self): | |||
| g = """ | |||
| start: line* | |||
| line: NL | |||
| | rule | |||
| | "hello" -> hi | |||
| rule: WORD ":" NUMBER | |||
| NL: /(\\r?\\n)+\\s*/ | |||
| """ + common | |||
| code = """ | |||
| Elephants: 12 | |||
| hello | |||
| """ | |||
| self.assert_reconstruct(g, code) | |||
| def test_json_example(self): | |||
| test_json = ''' | |||
| { | |||
| "empty_object" : {}, | |||
| "empty_array" : [], | |||
| "booleans" : { "YES" : true, "NO" : false }, | |||
| "numbers" : [ 0, 1, -2, 3.3, 4.4e5, 6.6e-7 ], | |||
| "strings" : [ "This", [ "And" , "That", "And a \\"b" ] ], | |||
| "nothing" : null | |||
| } | |||
| ''' | |||
| json_grammar = r""" | |||
| ?start: value | |||
| ?value: object | |||
| | array | |||
| | string | |||
| | SIGNED_NUMBER -> number | |||
| | "true" -> true | |||
| | "false" -> false | |||
| | "null" -> null | |||
| array : "[" [value ("," value)*] "]" | |||
| object : "{" [pair ("," pair)*] "}" | |||
| pair : string ":" value | |||
| string : ESCAPED_STRING | |||
| %import common.ESCAPED_STRING | |||
| %import common.SIGNED_NUMBER | |||
| %import common.WS | |||
| %ignore WS | |||
| """ | |||
| json_parser = Lark(json_grammar, parser='lalr') | |||
| tree = json_parser.parse(test_json) | |||
| new_json = Reconstructor(json_parser).reconstruct(tree) | |||
| self.assertEqual(json.loads(new_json), json.loads(test_json)) | |||
| if __name__ == '__main__': | |||
| unittest.main() | |||
+ 7
- 0
tests/test_relative_import.lark
View File
| @@ -0,0 +1,7 @@ | |||
| start: NUMBER WORD | |||
| %import .grammars.test.NUMBER | |||
| %import common.WORD | |||
| %import common.WS | |||
| %ignore WS | |||